 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling spatio-temporal knowledge for weakly supervised object detection and segmentation in surgical video
Paper and Code
Jul 23, 2024

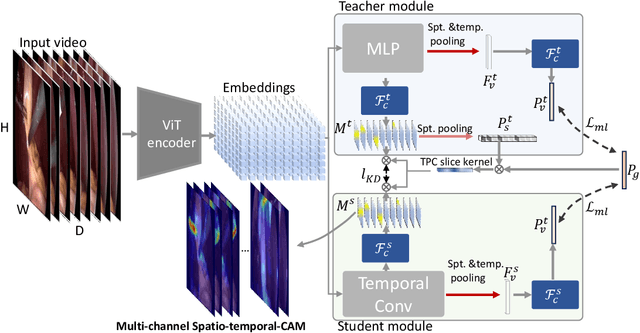
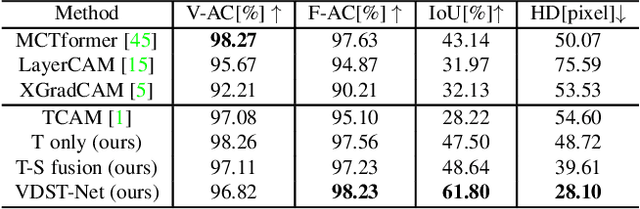
Weakly supervised video object segmentation (WSVOS) enables the identification of segmentation maps without requiring an extensive training dataset of object masks, relying instead on coarse video labels indicating object presence. Current state-of-the-art methods either require multiple independent stages of processing that employ motion cues or, in the case of end-to-end trainable networks, lack in segmentation accuracy, in part due to the difficulty of learning segmentation maps from videos with transient object presence. This limits the application of WSVOS for semantic annotation of surgical videos where multiple surgical tools frequently move in and out of the field of view, a problem that is more difficult than typically encountered in WSVOS. This paper introduces Video Spatio-Temporal Disentanglement Networks (VDST-Net), a framework to disentangle spatiotemporal information using semi-decoupled knowledge distillation to predict high-quality class activation maps (CAMs). A teacher network designed to resolve temporal conflicts when specifics about object location and timing in the video are not provided works with a student network that integrates information over time by leveraging temporal dependencies. We demonstrate the efficacy of our framework on a public reference dataset and on a more challenging surgical video dataset where objects are, on average, present in less than 60\% of annotated frames. Our method outperforms state-of-the-art techniques and generates superior segmentation masks under video-level weak supervision.