 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAR Object Detection with Self-Supervised Pretraining and Curriculum-Aware Sampling
Apr 17, 2025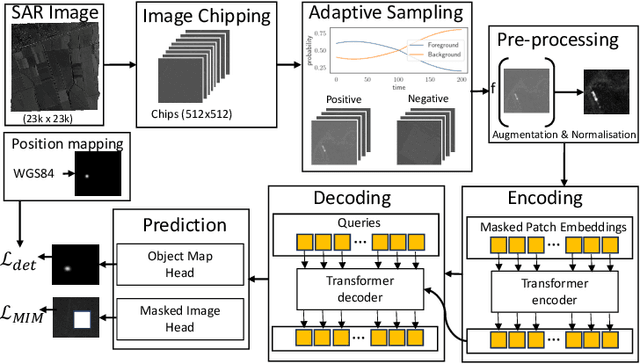
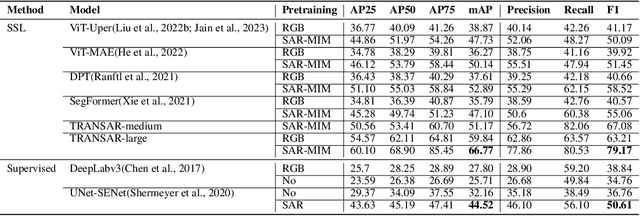

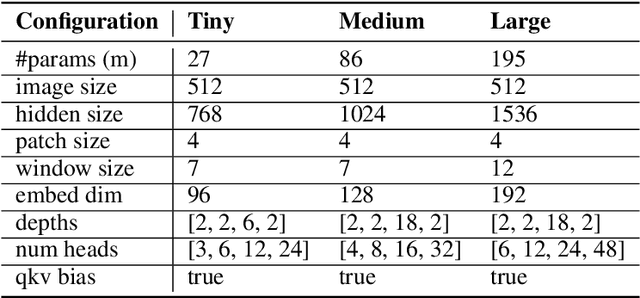
Object detection in satellite-borne Synthetic Aperture Radar (SAR) imagery holds immense potential in tasks such as urban monitoring and disaster response. However, the inherent complexities of SAR data and the scarcity of annotations present significant challenges in the advancement of object detection in this domain. Notably, the detection of small objects in satellite-borne SAR images poses a particularly intricate problem, because of the technology's relatively low spatial resolution and inherent noise. Furthermore, the lack of large labelled SAR datasets hinders the development of supervised deep learning-based object detection models. In this paper, we introduce TRANSAR, a novel self-supervised end-to-end vision transformer-based SAR object detection model that incorporates masked image pre-training on an unlabeled SAR image dataset that spans more than $25,700$ km\textsuperscript{2} ground area. Unlike traditional object detection formulation, our approach capitalises on auxiliary binary semantic segmentation, designed to segregate objects of interest during the post-tuning, especially the smaller ones, from the background. In addition, to address the innate class imbalance due to the disproportion of the object to the image size, we introduce an adaptive sampling scheduler that dynamically adjusts the target class distribution during training based on curriculum learning and model feedback. This approach allows us to outperform conventional supervised architecture such as DeepLabv3 or UNet, and state-of-the-art self-supervised learning-based arhitectures such as DPT, SegFormer or UperNet, as shown by extensive evaluations on benchmark SAR datasets.
Modular Adaptive Policy Selection for Multi-Task Imitation Learning through Task Division
Mar 28, 2022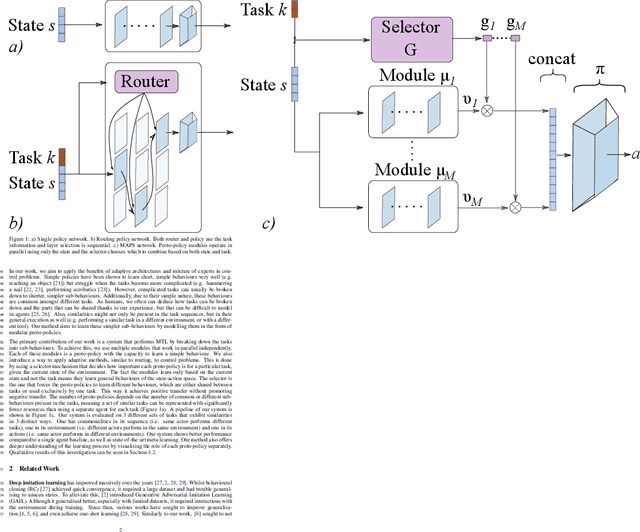

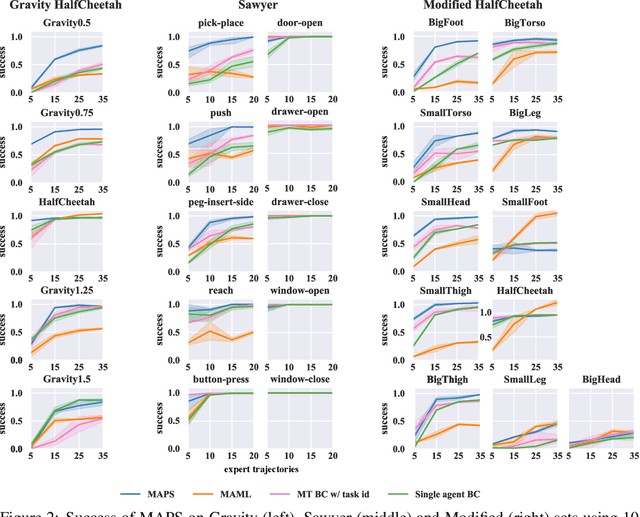
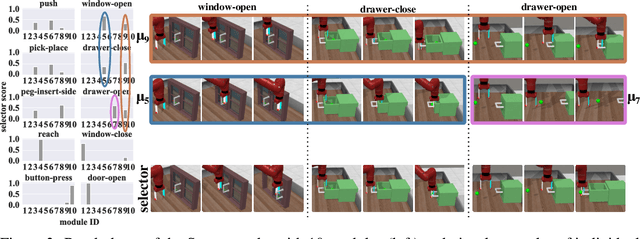
Deep imitation learning requires many expert demonstrations, which can be hard to obtain, especially when many tasks are involved. However, different tasks often share similarities, so learning them jointly can greatly benefit them and alleviate the need for many demonstrations. But, joint multi-task learning often suffers from negative transfer, sharing information that should be task-specific. In this work, we introduce a method to perform multi-task imitation while allowing for task-specific features. This is done by using proto-policies as modules to divide the tasks into simple sub-behaviours that can be shared. The proto-policies operate in parallel and are adaptively chosen by a selector mechanism that is jointly trained with the modules. Experiments on different sets of tasks show that our method improves upon the accuracy of single agents, task-conditioned and multi-headed multi-task agents, as well as state-of-the-art meta learning agents. We also demonstrate its ability to autonomously divide the tasks into both shared and task-specific sub-behaviours.
Adversarial Imitation Learning with Trajectorial Augmentation and Correction
Mar 26, 2021

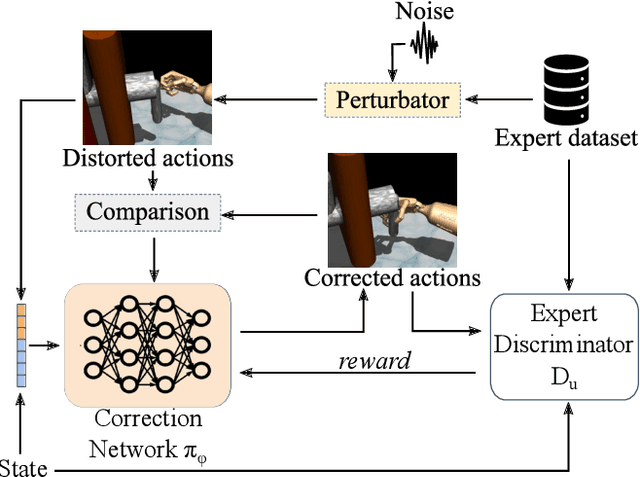
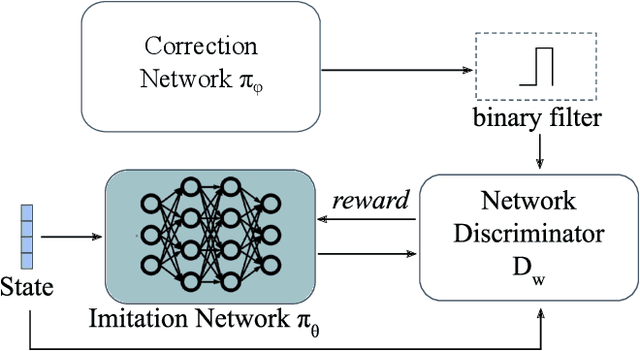
Deep Imitation Learning requires a large number of expert demonstrations, which are not always easy to obtain, especially for complex tasks. A way to overcome this shortage of labels is through data augmentation. However, this cannot be easily applied to control tasks due to the sequential nature of the problem. In this work, we introduce a novel augmentation method which preserves the success of the augmented trajectories. To achieve this, we introduce a semi-supervised correction network that aims to correct distorted expert actions. To adequately test the abilities of the correction network, we develop an adversarial data augmented imitation architecture to train an imitation agent using synthetic experts. Additionally, we introduce a metric to measure diversity in trajectory datasets. Experiments show that our data augmentation strategy can improve accuracy and convergence time of adversarial imitation while preserving the diversity between the generated and real trajectories.
Task-Oriented Hand Motion Retargeting for Dexterous Manipulation Imitation
Oct 03, 2018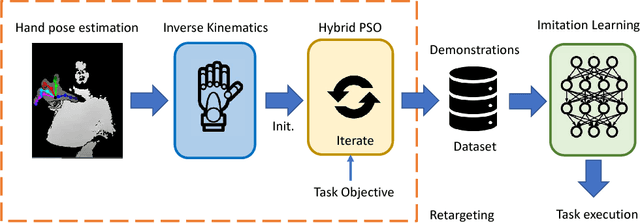
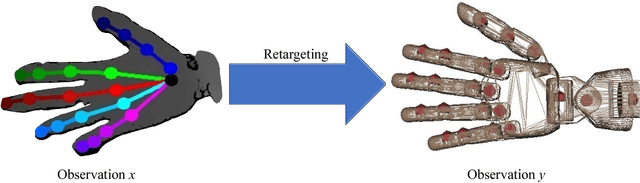
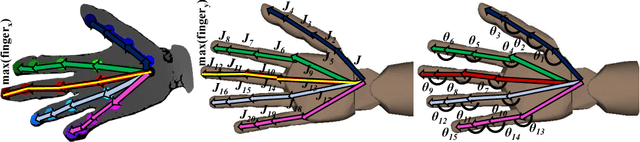

Human hand actions are quite complex, especially when they involve object manipulation, mainly due to the high dimensionality of the hand and the vast action space that entails. Imitating those actions with dexterous hand models involves different important and challenging steps: acquiring human hand information, retargeting it to a hand model, and learning a policy from acquired data. In this work, we capture the hand information by using a state-of-the-art hand pose estimator. We tackle the retargeting problem from the hand pose to a 29 DoF hand model by combining inverse kinematics and PSO with a task objective optimisation. This objective encourages the virtual hand to accomplish the manipulation task, relieving the effect of the estimator's noise and the domain gap. Our approach leads to a better success rate in the grasping task compared to our inverse kinematics baseline, allowing us to record successful human demonstrations. Furthermore, we used these demonstrations to learn a policy network using generative adversarial imitation learning (GAIL) that is able to autonomously grasp an object in the virtual space.