 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi3DeTr: A LiDAR based 3D Detection Transformer
Oct 27, 2022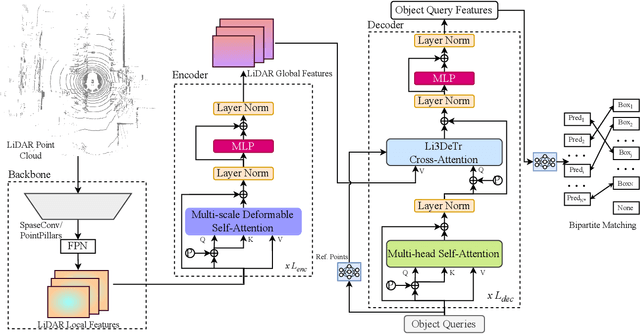
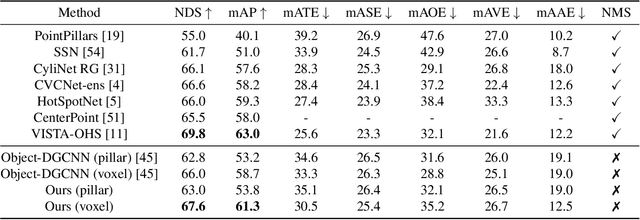
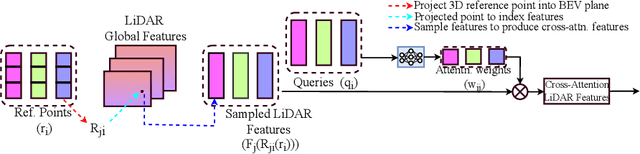
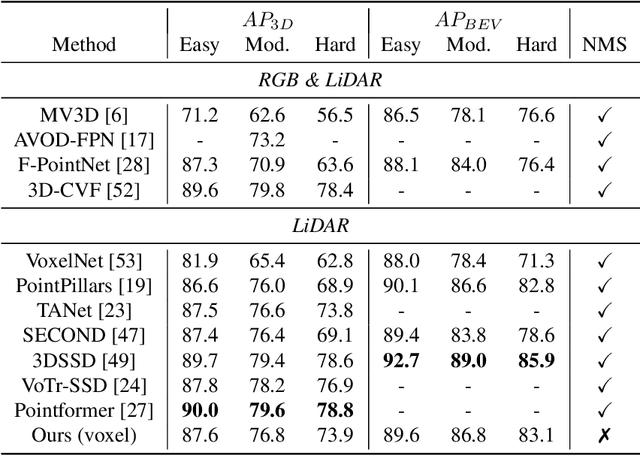
Inspired by recent advances in vision transformers for object detection, we propose Li3DeTr, an end-to-end LiDAR based 3D Detection Transformer for autonomous driving, that inputs LiDAR point clouds and regresses 3D bounding boxes. The LiDAR local and global features are encoded using sparse convolution and multi-scale deformable attention respectively. In the decoder head, firstly, in the novel Li3DeTr cross-attention block, we link the LiDAR global features to 3D predictions leveraging the sparse set of object queries learnt from the data. Secondly, the object query interactions are formulated using multi-head self-attention. Finally, the decoder layer is repeated $L_{dec}$ number of times to refine the object queries. Inspired by DETR, we employ set-to-set loss to train the Li3DeTr network. Without bells and whistles, the Li3DeTr network achieves 61.3% mAP and 67.6% NDS surpassing the state-of-the-art methods with non-maximum suppression (NMS) on the nuScenes dataset and it also achieves competitive performance on the KITTI dataset. We also employ knowledge distillation (KD) using a teacher and student model that slightly improves the performance of our network.
MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer for Autonomous Driving
Oct 27, 20223D object detection is a significant task for autonomous driving. Recently with the progress of vision transformers, the 2D object detection problem is being treated with the set-to-set loss. Inspired by these approaches on 2D object detection and an approach for multi-view 3D object detection DETR3D, we propose MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer architecture to fuse image and LiDAR features to improve the detection accuracy. Our end-to-end single-stage, anchor-free and NMS-free network takes in multi-view images and LiDAR point clouds and predicts 3D bounding boxes. Firstly, we link the object queries learnt from data to the image and LiDAR features using a novel MSF3DDETR cross-attention block. Secondly, the object queries interacts with each other in multi-head self-attention block. Finally, MSF3DDETR block is repeated for $L$ number of times to refine the object queries. The MSF3DDETR network is trained end-to-end on the nuScenes dataset using Hungarian algorithm based bipartite matching and set-to-set loss inspired by DETR. We present both quantitative and qualitative results which are competitive to the state-of-the-art approaches.
FAIR-FATE: Fair Federated Learning with Momentum
Sep 27, 2022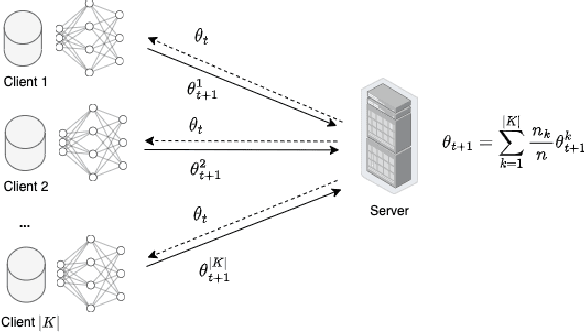
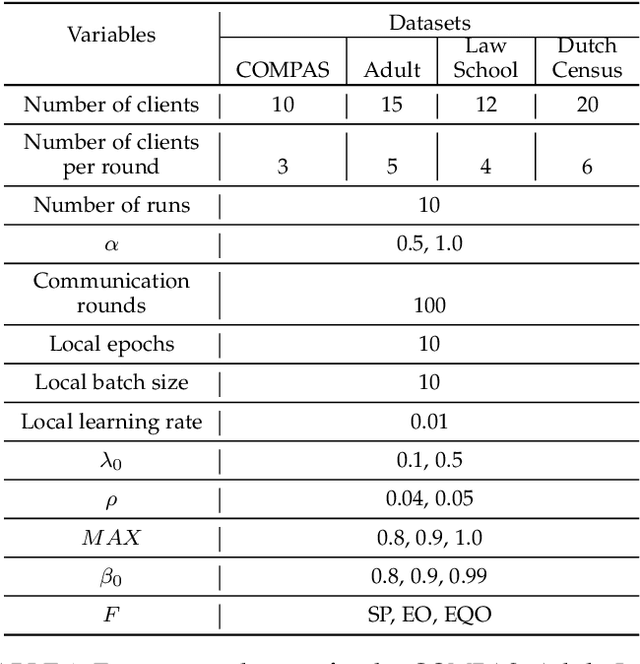
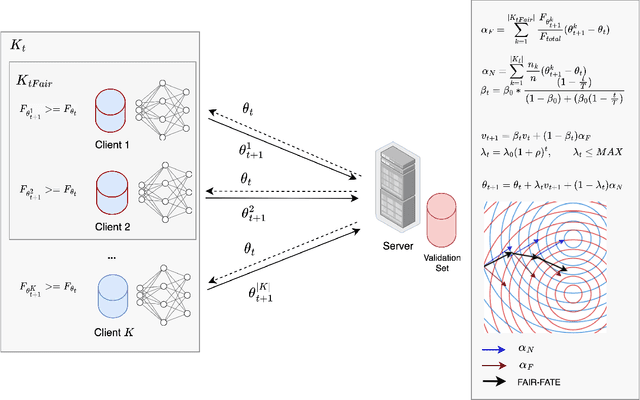
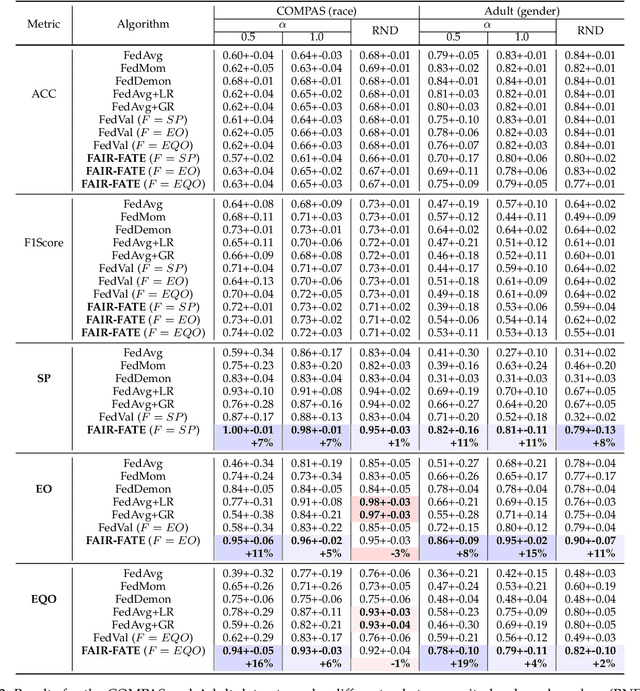
While fairness-aware machine learning algorithms have been receiving increasing attention, the focus has been on centralized machine learning, leaving decentralized methods underexplored. Federated Learning is a decentralized form of machine learning where clients train local models with a server aggregating them to obtain a shared global model. Data heterogeneity amongst clients is a common characteristic of Federated Learning, which may induce or exacerbate discrimination of unprivileged groups defined by sensitive attributes such as race or gender. In this work we propose FAIR-FATE: a novel FAIR FederATEd Learning algorithm that aims to achieve group fairness while maintaining high utility via a fairness-aware aggregation method that computes the global model by taking into account the fairness of the clients. To achieve that, the global model update is computed by estimating a fair model update using a Momentum term that helps to overcome the oscillations of noisy non-fair gradients. To the best of our knowledge, this is the first approach in machine learning that aims to achieve fairness using a fair Momentum estimate. Experimental results on four real-world datasets demonstrate that FAIR-FATE significantly outperforms state-of-the-art fair Federated Learning algorithms under different levels of data heterogeneity.
Quantitative Evaluation of Endoscopic SLAM Methods: EndoSLAM Dataset
Jul 01, 2020

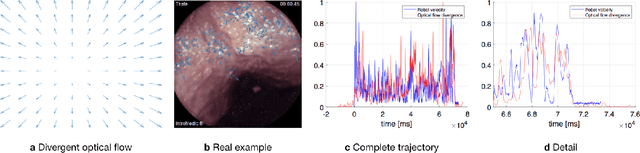

Deep learning techniques hold promise to improve dense topography reconstruction and pose estimation, as well as simultaneous localization and mapping (SLAM). However, currently available datasets do not support effective quantitative benchmarking. With this paper, we introduce a comprehensive endoscopic SLAM dataset containing both capsule and standard endoscopy recordings. A Panda robotic arm, two different commercially available high precision 3D scanners, two different commercially available capsule endoscopes with different camera properties and two different conventional endoscopy cameras were employed to collect data from eight ex-vivo porcine gastrointestinal (GI)-tract organs. In total, 35 sub-datasets are provided: 18 sub-datasets for colon, 12 sub-datasets for stomach and five sub-datasets for small intestine, while four of these contain polyp-mimicking elevations carried out by an expert gastroenterologist. To exemplify the use-case, SC-SfMLearner was comprehensively benchmarked. The codes and the link for the dataset are publicly available at https://github.com/CapsuleEndoscope/EndoSLAM. A video demonstrating the experimental setup and procedure is available at https://www.youtube.com/watch?v=G_LCe0aWWdQ.
Magnetic-Visual Sensor Fusion-based Dense 3D Reconstruction and Localization for Endoscopic Capsule Robots
Mar 02, 2018
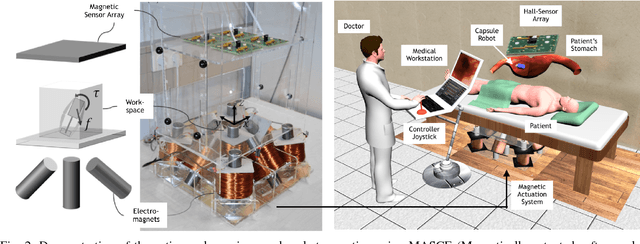

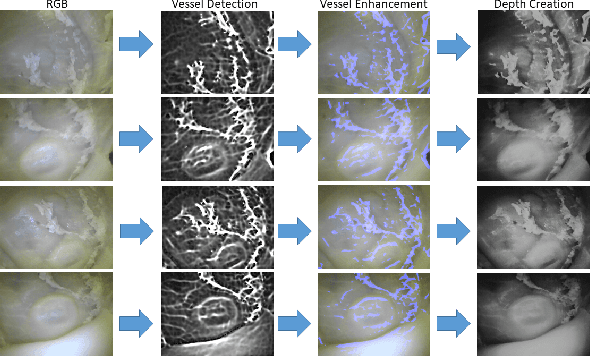
Reliable and real-time 3D reconstruction and localization functionality is a crucial prerequisite for the navigation of actively controlled capsule endoscopic robots as an emerging, minimally invasive diagnostic and therapeutic technology for use in the gastrointestinal (GI) tract. In this study, we propose a fully dense, non-rigidly deformable, strictly real-time, intraoperative map fusion approach for actively controlled endoscopic capsule robot applications which combines magnetic and vision-based localization, with non-rigid deformations based frame-to-model map fusion. The performance of the proposed method is demonstrated using four different ex-vivo porcine stomach models. Across different trajectories of varying speed and complexity, and four different endoscopic cameras, the root mean square surface reconstruction errors 1.58 to 2.17 cm.
Magnetic-Visual Sensor Fusion based Medical SLAM for Endoscopic Capsule Robot
Nov 06, 2017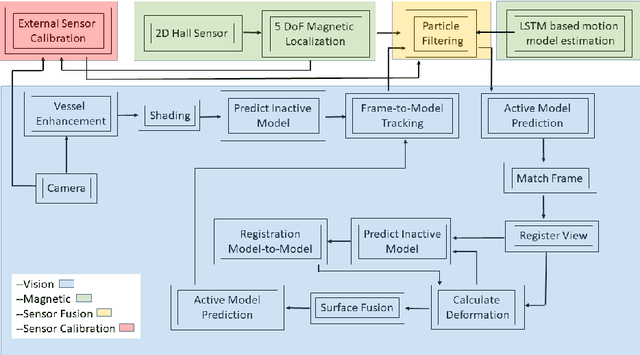
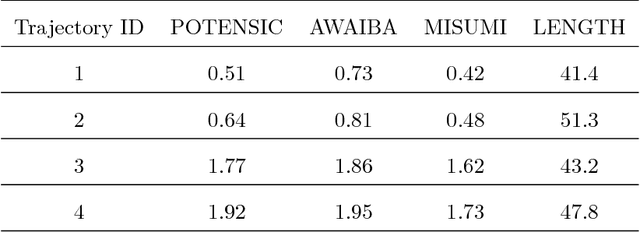
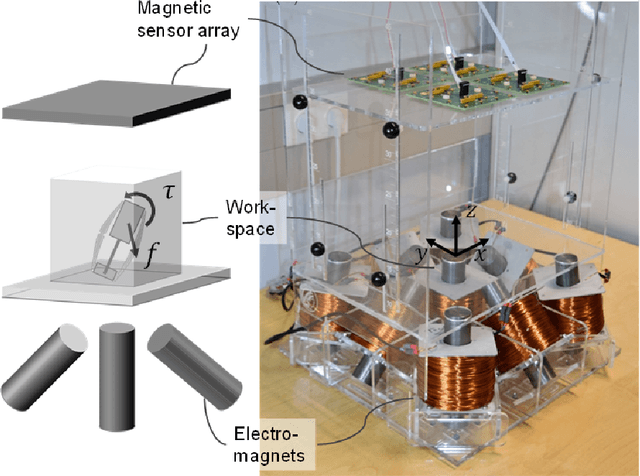
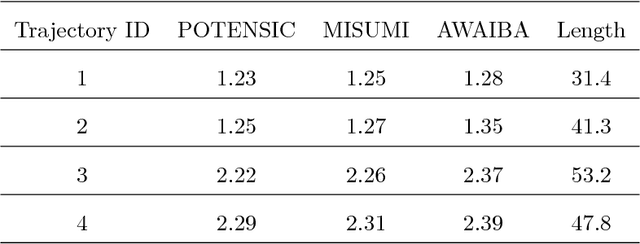
A reliable, real-time simultaneous localization and mapping (SLAM) method is crucial for the navigation of actively controlled capsule endoscopy robots. These robots are an emerging, minimally invasive diagnostic and therapeutic technology for use in the gastrointestinal (GI) tract. In this study, we propose a dense, non-rigidly deformable, and real-time map fusion approach for actively controlled endoscopic capsule robot applications. The method combines magnetic and vision based localization, and makes use of frame-to-model fusion and model-to-model loop closure. The performance of the method is demonstrated using an ex-vivo porcine stomach model. Across four trajectories of varying speed and complexity, and across three cameras, the root mean square localization errors range from 0.42 to 1.92 cm, and the root mean square surface reconstruction errors range from 1.23 to 2.39 cm.
EndoSensorFusion: Particle Filtering-Based Multi-sensory Data Fusion with Switching State-Space Model for Endoscopic Capsule Robots
Sep 25, 2017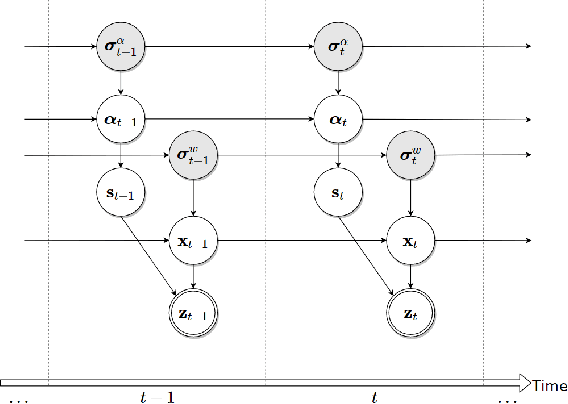
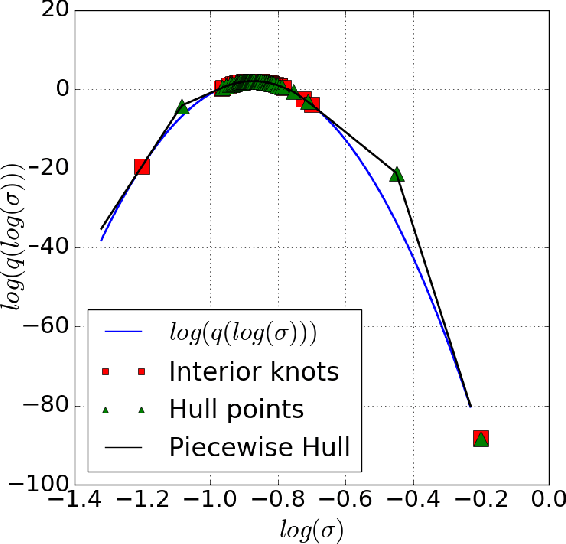
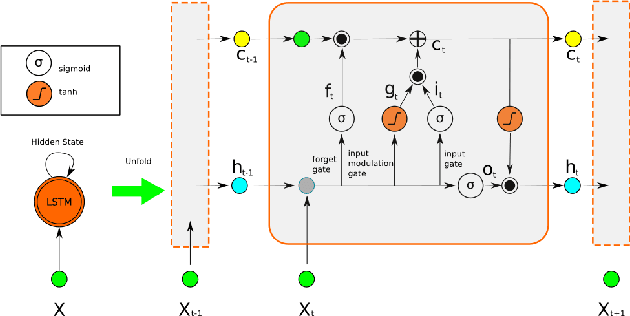

A reliable, real time multi-sensor fusion functionality is crucial for localization of actively controlled capsule endoscopy robots, which are an emerging, minimally invasive diagnostic and therapeutic technology for the gastrointestinal (GI) tract. In this study, we propose a novel multi-sensor fusion approach based on a particle filter that incorporates an online estimation of sensor reliability and a non-linear kinematic model learned by a recurrent neural network. Our method sequentially estimates the true robot pose from noisy pose observations delivered by multiple sensors. We experimentally test the method using 5 degree-of-freedom (5-DoF) absolute pose measurement by a magnetic localization system and a 6-DoF relative pose measurement by visual odometry. In addition, the proposed method is capable of detecting and handling sensor failures by ignoring corrupted data, providing the robustness expected of a medical device. Detailed analyses and evaluations are presented using ex-vivo experiments on a porcine stomach model prove that our system achieves high translational and rotational accuracies for different types of endoscopic capsule robot trajectories.
3D Reconstruction with Low Resolution, Small Baseline and High Radial Distortion Stereo Images
Sep 19, 2017
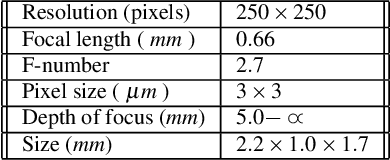
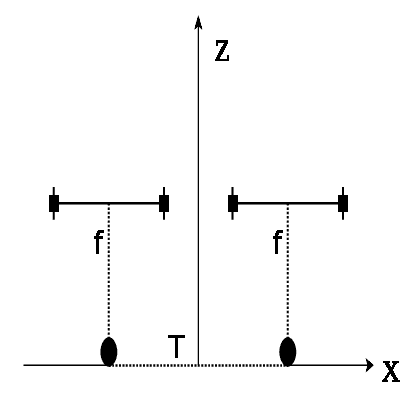
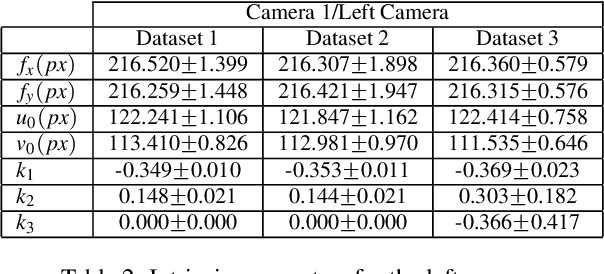
In this paper we analyze and compare approaches for 3D reconstruction from low-resolution (250x250), high radial distortion stereo images, which are acquired with small baseline (approximately 1mm). These images are acquired with the system NanEye Stereo manufactured by CMOSIS/AWAIBA. These stereo cameras have also small apertures, which means that high levels of illumination are required. The goal was to develop an approach yielding accurate reconstructions, with a low computational cost, i.e., avoiding non-linear numerical optimization algorithms. In particular we focused on the analysis and comparison of radial distortion models. To perform the analysis and comparison, we defined a baseline method based on available software and methods, such as the Bouguet toolbox [2] or the Computer Vision Toolbox from Matlab. The approaches tested were based on the use of the polynomial model of radial distortion, and on the application of the division model. The issue of the center of distortion was also addressed within the framework of the application of the division model. We concluded that the division model with a single radial distortion parameter has limitations.
Deep EndoVO: A Recurrent Convolutional Neural Network (RCNN) based Visual Odometry Approach for Endoscopic Capsule Robots
Sep 08, 2017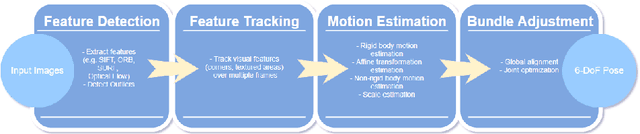


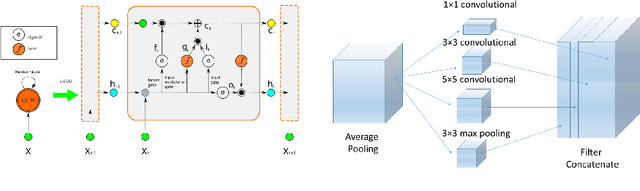
Ingestible wireless capsule endoscopy is an emerging minimally invasive diagnostic technology for inspection of the GI tract and diagnosis of a wide range of diseases and pathologies. Medical device companies and many research groups have recently made substantial progresses in converting passive capsule endoscopes to active capsule robots, enabling more accurate, precise, and intuitive detection of the location and size of the diseased areas. Since a reliable real time pose estimation functionality is crucial for actively controlled endoscopic capsule robots, in this study, we propose a monocular visual odometry (VO) method for endoscopic capsule robot operations. Our method lies on the application of the deep Recurrent Convolutional Neural Networks (RCNNs) for the visual odometry task, where Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are used for the feature extraction and inference of dynamics across the frames, respectively. Detailed analyses and evaluations made on a real pig stomach dataset proves that our system achieves high translational and rotational accuracies for different types of endoscopic capsule robot trajectories.
Sparse-then-Dense Alignment based 3D Map Reconstruction Method for Endoscopic Capsule Robots
Aug 29, 2017



Since the development of capsule endoscopcy technology, substantial progress were made in converting passive capsule endoscopes to robotic active capsule endoscopes which can be controlled by the doctor. However, robotic capsule endoscopy still has some challenges. In particular, the use of such devices to generate a precise and globally consistent three-dimensional (3D) map of the entire inner organ remains an unsolved problem. Such global 3D maps of inner organs would help doctors to detect the location and size of diseased areas more accurately, precisely, and intuitively, thus permitting more accurate and intuitive diagnoses. The proposed 3D reconstruction system is built in a modular fashion including preprocessing, frame stitching, and shading-based 3D reconstruction modules. We propose an efficient scheme to automatically select the key frames out of the huge quantity of raw endoscopic images. Together with a bundle fusion approach that aligns all the selected key frames jointly in a globally consistent way, a significant improvement of the mosaic and 3D map accuracy was reached. To the best of our knowledge, this framework is the first complete pipeline for an endoscopic capsule robot based 3D map reconstruction containing all of the necessary steps for a reliable and accurate endoscopic 3D map. For the qualitative evaluations, a real pig stomach is employed. Moreover, for the first time in literature, a detailed and comprehensive quantitative analysis of each proposed pipeline modules is performed using a non-rigid esophagus gastro duodenoscopy simulator, four different endoscopic cameras, a magnetically activated soft capsule robot (MASCE), a sub-millimeter precise optical motion tracker and a fine-scale 3D optical scanner.