 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuSEditor: From Multi-View Images to Text-Guided Neural Surface Edits
May 16, 2025Implicit surface representations are valued for their compactness and continuity, but they pose significant challenges for editing. Despite recent advancements, existing methods often fail to preserve identity and maintain geometric consistency during editing. To address these challenges, we present NeuSEditor, a novel method for text-guided editing of neural implicit surfaces derived from multi-view images. NeuSEditor introduces an identity-preserving architecture that efficiently separates scenes into foreground and background, enabling precise modifications without altering the scene-specific elements. Our geometry-aware distillation loss significantly enhances rendering and geometric quality. Our method simplifies the editing workflow by eliminating the need for continuous dataset updates and source prompting. NeuSEditor outperforms recent state-of-the-art methods like PDS and InstructNeRF2NeRF, delivering superior quantitative and qualitative results. For more visual results, visit: neuseditor.github.io.
MuVieCAST: Multi-View Consistent Artistic Style Transfer
Dec 08, 2023



We introduce MuVieCAST, a modular multi-view consistent style transfer network architecture that enables consistent style transfer between multiple viewpoints of the same scene. This network architecture supports both sparse and dense views, making it versatile enough to handle a wide range of multi-view image datasets. The approach consists of three modules that perform specific tasks related to style transfer, namely content preservation, image transformation, and multi-view consistency enforcement. We extensively evaluate our approach across multiple application domains including depth-map-based point cloud fusion, mesh reconstruction, and novel-view synthesis. Our experiments reveal that the proposed framework achieves an exceptional generation of stylized images, exhibiting consistent outcomes across perspectives. A user study focusing on novel-view synthesis further confirms these results, with approximately 68\% of cases participants expressing a preference for our generated outputs compared to the recent state-of-the-art method. Our modular framework is extensible and can easily be integrated with various backbone architectures, making it a flexible solution for multi-view style transfer. More results are demonstrated on our project page: muviecast.github.io
Push-the-Boundary: Boundary-aware Feature Propagation for Semantic Segmentation of 3D Point Clouds
Dec 23, 2022



Feedforward fully convolutional neural networks currently dominate in semantic segmentation of 3D point clouds. Despite their great success, they suffer from the loss of local information at low-level layers, posing significant challenges to accurate scene segmentation and precise object boundary delineation. Prior works either address this issue by post-processing or jointly learn object boundaries to implicitly improve feature encoding of the networks. These approaches often require additional modules which are difficult to integrate into the original architecture. To improve the segmentation near object boundaries, we propose a boundary-aware feature propagation mechanism. This mechanism is achieved by exploiting a multi-task learning framework that aims to explicitly guide the boundaries to their original locations. With one shared encoder, our network outputs (i) boundary localization, (ii) prediction of directions pointing to the object's interior, and (iii) semantic segmentation, in three parallel streams. The predicted boundaries and directions are fused to propagate the learned features to refine the segmentation. We conduct extensive experiments on the S3DIS and SensatUrban datasets against various baseline methods, demonstrating that our proposed approach yields consistent improvements by reducing boundary errors. Our code is available at https://github.com/shenglandu/PushBoundary.
DDL-MVS: Depth Discontinuity Learning for MVS Networks
Mar 30, 2022



Traditional MVS methods have good accuracy but struggle with completeness, while recently developed learning-based multi-view stereo (MVS) techniques have improved completeness except accuracy being compromised. We propose depth discontinuity learning for MVS methods, which further improves accuracy while retaining the completeness of the reconstruction. Our idea is to jointly estimate the depth and boundary maps where the boundary maps are explicitly used for further refinement of the depth maps. We validate our idea and demonstrate that our strategies can be easily integrated into the existing learning-based MVS pipeline where the reconstruction depends on high-quality depth map estimation. Extensive experiments on various datasets show that our method improves reconstruction quality compared to baseline. Experiments also demonstrate that the presented model and strategies have good generalization capabilities. The source code will be available soon.
Unsupervised Odometry and Depth Learning for Endoscopic Capsule Robots
Mar 02, 2018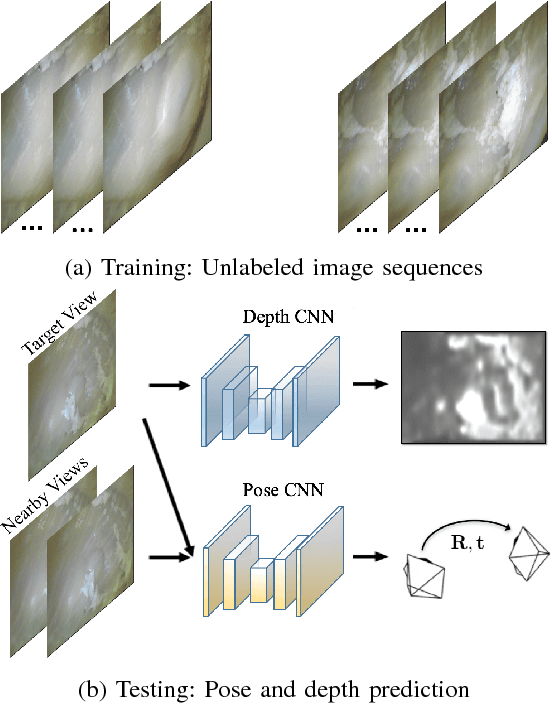
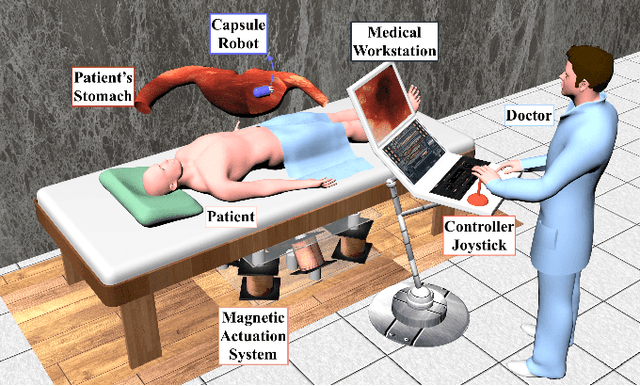

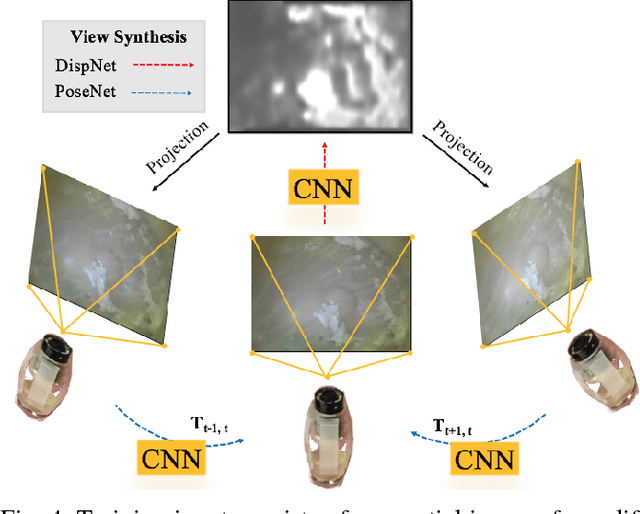
In the last decade, many medical companies and research groups have tried to convert passive capsule endoscopes as an emerging and minimally invasive diagnostic technology into actively steerable endoscopic capsule robots which will provide more intuitive disease detection, targeted drug delivery and biopsy-like operations in the gastrointestinal(GI) tract. In this study, we introduce a fully unsupervised, real-time odometry and depth learner for monocular endoscopic capsule robots. We establish the supervision by warping view sequences and assigning the re-projection minimization to the loss function, which we adopt in multi-view pose estimation and single-view depth estimation network. Detailed quantitative and qualitative analyses of the proposed framework performed on non-rigidly deformable ex-vivo porcine stomach datasets proves the effectiveness of the method in terms of motion estimation and depth recovery.