 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Video Generation through Global and Local Motion Dynamics
Paper and Code

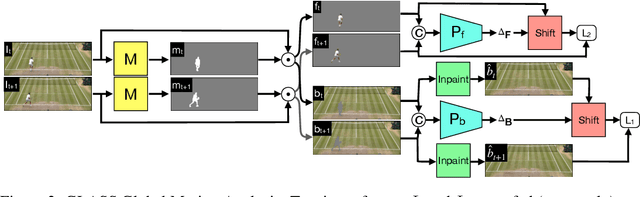
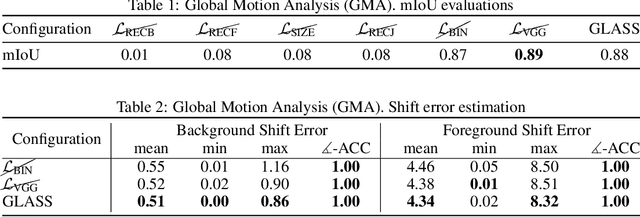
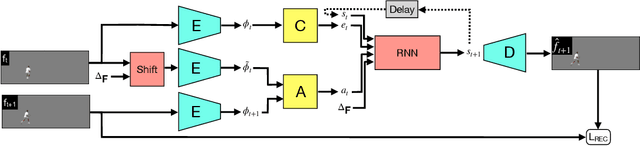
We present GLASS, a method for Global and Local Action-driven Sequence Synthesis. GLASS is a generative model that is trained on video sequences in an unsupervised manner and that can animate an input image at test time. The method learns to segment frames into foreground-background layers and to generate transitions of the foregrounds over time through a global and local action representation. Global actions are explicitly related to 2D shifts, while local actions are instead related to (both geometric and photometric) local deformations. GLASS uses a recurrent neural network to transition between frames and is trained through a reconstruction loss. We also introduce W-Sprites (Walking Sprites), a novel synthetic dataset with a predefined action space. We evaluate our method on both W-Sprites and real datasets, and find that GLASS is able to generate realistic video sequences from a single input image and to successfully learn a more advanced action space than in prior work.