 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Self-Replication: Detecting Distributed Selfhood in the Outlier Cellular Automaton
Aug 11, 2025Spontaneous self-replication in cellular automata has long been considered rare, with most known examples requiring careful design or artificial initialization. In this paper, we present formal, causal evidence that such replication can emerge unassisted -- and that it can do so in a distributed, multi-component form. Building on prior work identifying complex dynamics in the Outlier rule, we introduce a data-driven framework that reconstructs the full causal ancestry of patterns in a deterministic cellular automaton. This allows us to rigorously identify self-replicating structures via explicit causal lineages. Our results show definitively that self-replicators in the Outlier CA are not only spontaneous and robust, but are also often composed of multiple disjoint clusters working in coordination, raising questions about some conventional notions of individuality and replication in artificial life systems.
Promoting Cooperation in the Public Goods Game using Artificial Intelligent Agents
Dec 06, 2024The tragedy of the commons illustrates a fundamental social dilemma where individual rational actions lead to collectively undesired outcomes, threatening the sustainability of shared resources. Strategies to escape this dilemma, however, are in short supply. In this study, we explore how artificial intelligence (AI) agents can be leveraged to enhance cooperation in public goods games, moving beyond traditional regulatory approaches to using AI as facilitators of cooperation. We investigate three scenarios: (1) Mandatory Cooperation Policy for AI Agents, where AI agents are institutionally mandated always to cooperate; (2) Player-Controlled Agent Cooperation Policy, where players evolve control over AI agents' likelihood to cooperate; and (3) Agents Mimic Players, where AI agents copy the behavior of players. Using a computational evolutionary model with a population of agents playing public goods games, we find that only when AI agents mimic player behavior does the critical synergy threshold for cooperation decrease, effectively resolving the dilemma. This suggests that we can leverage AI to promote collective well-being in societal dilemmas by designing AI agents to mimic human players.
Detecting Information Relays in Deep Neural Networks
Jan 03, 2023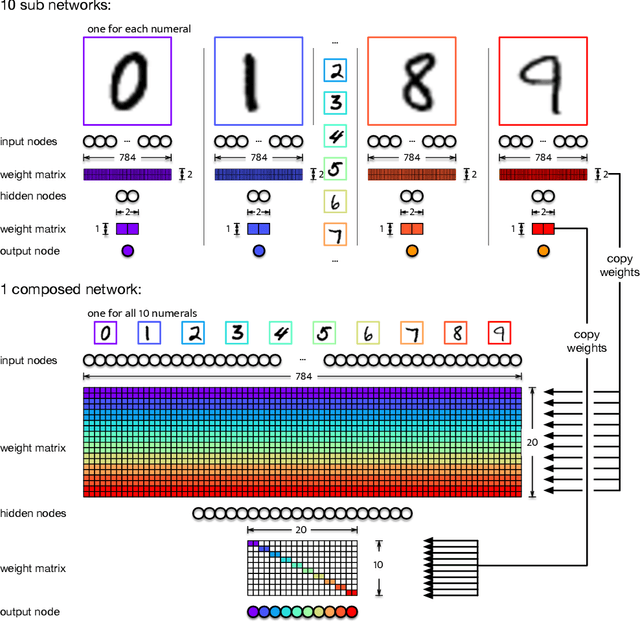



Deep-learning of artificial neural networks (ANNs) is creating highly functional tools that are, unfortunately, as hard to interpret as their natural counterparts. While it is possible to identify functional modules in natural brains using technologies such as fMRI, we do not have at our disposal similarly robust methods for artificial neural networks. Ideally, understanding which parts of an artificial neural network perform what function might help us to address a number of vexing problems in ANN research, such as catastrophic forgetting and overfitting. Furthermore, revealing a network's modularity could improve our trust in them by making these black boxes more transparent. Here we introduce a new information-theoretic concept that proves useful in understanding and analyzing a network's functional modularity: the relay information $I_R$. The relay information measures how much information groups of neurons that participate in a particular function (modules) relay from inputs to outputs. Combined with a greedy search algorithm, relay information can be used to {\em identify} computational modules in neural networks. We also show that the functionality of modules correlates with the amount of relay information they carry.
The structure of evolved representations across different substrates for artificial intelligence
Apr 05, 2018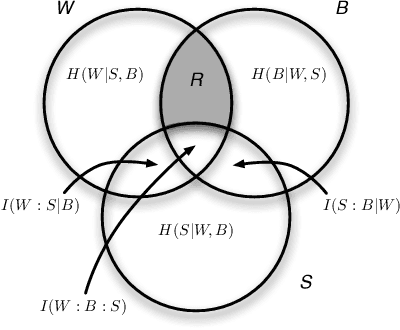
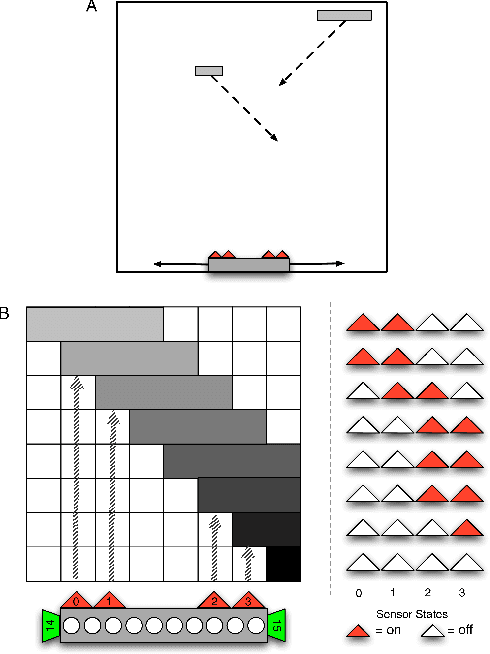
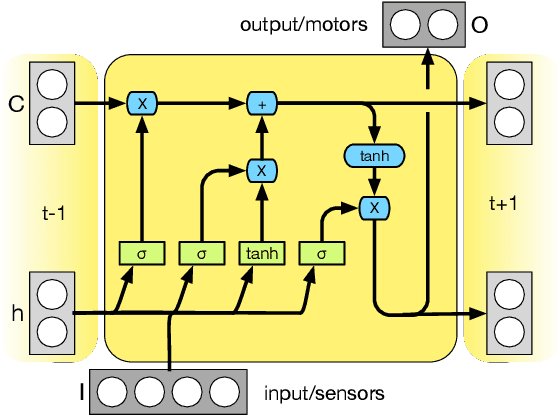
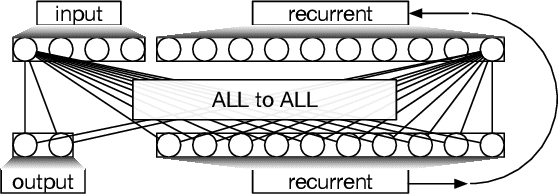
Artificial neural networks (ANNs), while exceptionally useful for classification, are vulnerable to misdirection. Small amounts of noise can significantly affect their ability to correctly complete a task. Instead of generalizing concepts, ANNs seem to focus on surface statistical regularities in a given task. Here we compare how recurrent artificial neural networks, long short-term memory units, and Markov Brains sense and remember their environments. We show that information in Markov Brains is localized and sparsely distributed, while the other neural network substrates "smear" information about the environment across all nodes, which makes them vulnerable to noise.
The Role of Conditional Independence in the Evolution of Intelligent Systems
Jan 16, 2018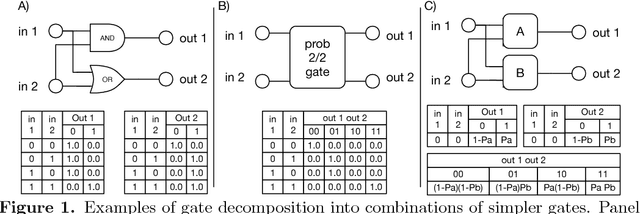
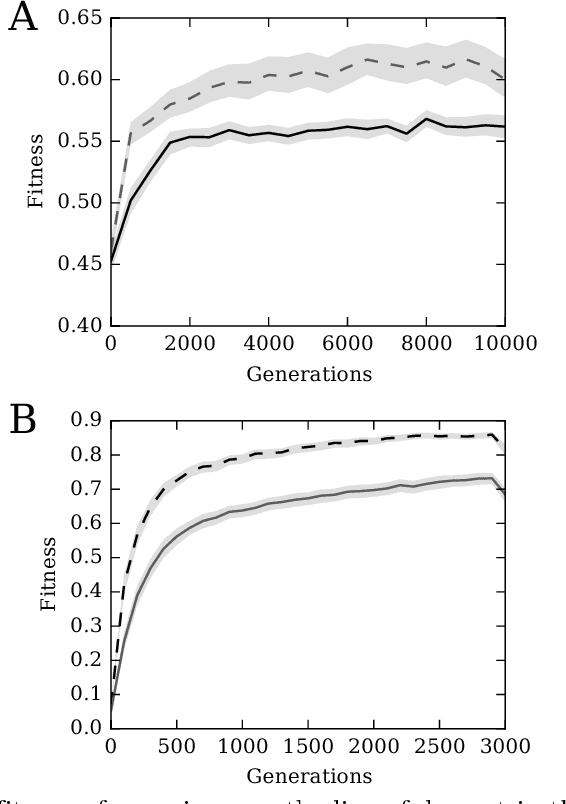
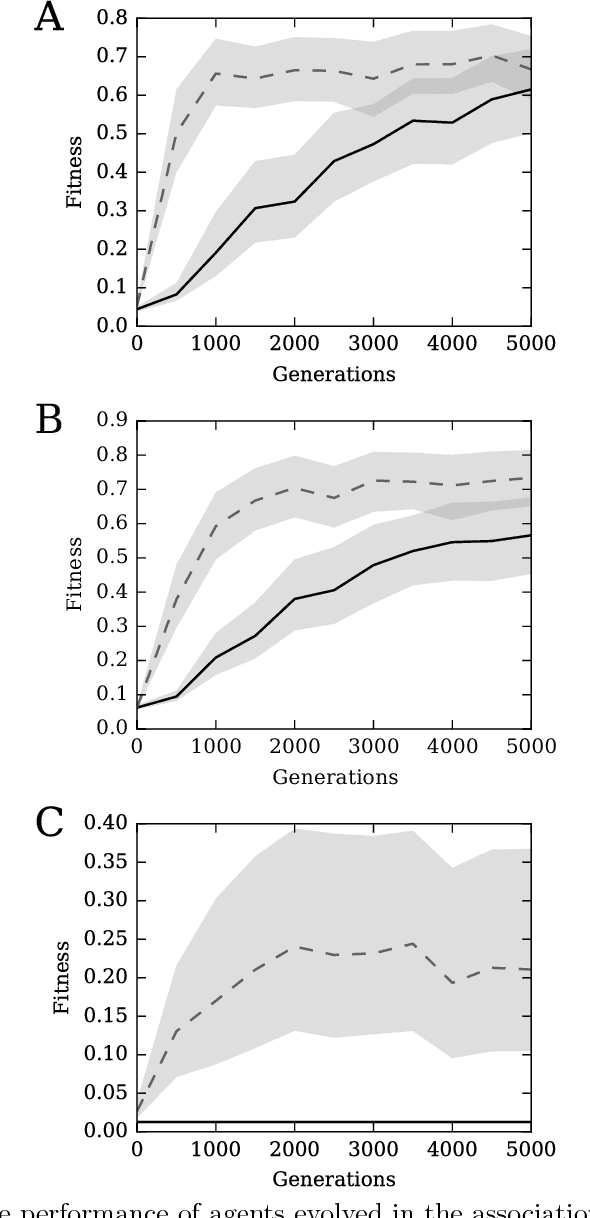
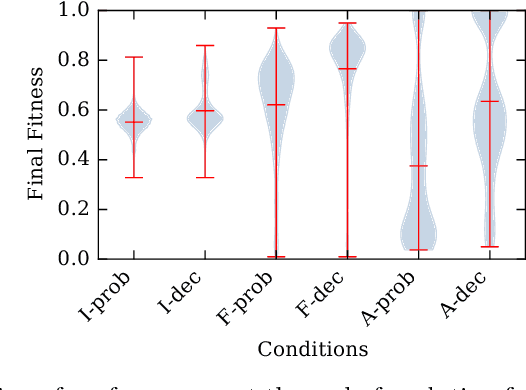
Systems are typically made from simple components regardless of their complexity. While the function of each part is easily understood, higher order functions are emergent properties and are notoriously difficult to explain. In networked systems, both digital and biological, each component receives inputs, performs a simple computation, and creates an output. When these components have multiple outputs, we intuitively assume that the outputs are causally dependent on the inputs but are themselves independent of each other given the state of their shared input. However, this intuition can be violated for components with probabilistic logic, as these typically cannot be decomposed into separate logic gates with one output each. This violation of conditional independence on the past system state is equivalent to instantaneous interaction --- the idea is that some information between the outputs is not coming from the inputs and thus must have been created instantaneously. Here we compare evolved artificial neural systems with and without instantaneous interaction across several task environments. We show that systems without instantaneous interactions evolve faster, to higher final levels of performance, and require fewer logic components to create a densely connected cognitive machinery.
Markov Brains: A Technical Introduction
Sep 17, 2017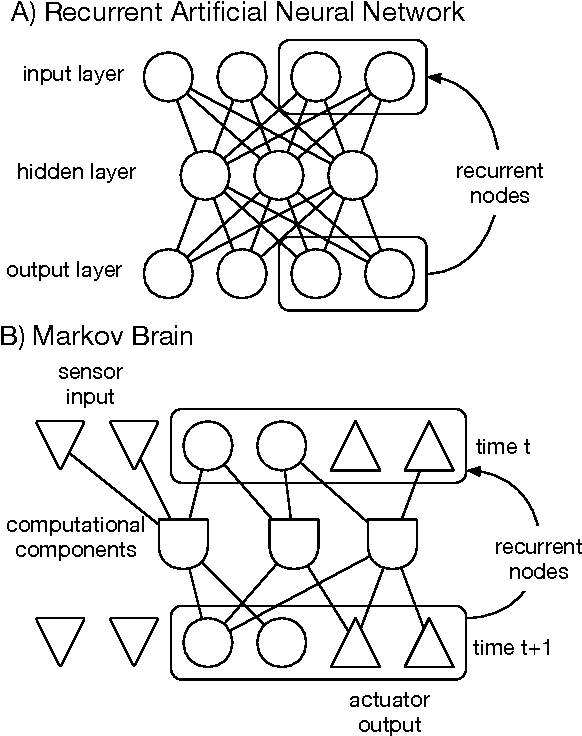
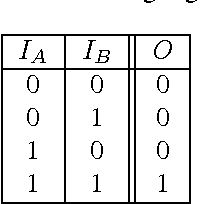
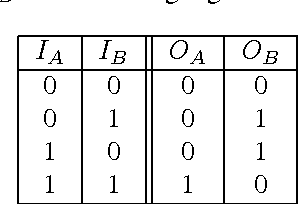

Markov Brains are a class of evolvable artificial neural networks (ANN). They differ from conventional ANNs in many aspects, but the key difference is that instead of a layered architecture, with each node performing the same function, Markov Brains are networks built from individual computational components. These computational components interact with each other, receive inputs from sensors, and control motor outputs. The function of the computational components, their connections to each other, as well as connections to sensors and motors are all subject to evolutionary optimization. Here we describe in detail how a Markov Brain works, what techniques can be used to study them, and how they can be evolved.
Machine Learned Learning Machines
Aug 31, 2017


There are two common approaches for optimizing the performance of a machine: genetic algorithms and machine learning. A genetic algorithm is applied over many generations whereas machine learning works by applying feedback until the system meets a performance threshold. Though these are methods that typically operate separately, we combine evolutionary adaptation and machine learning into one approach. Our focus is on machines that can learn during their lifetime, but instead of equipping them with a machine learning algorithm we aim to let them evolve their ability to learn by themselves. We use evolvable networks of probabilistic and deterministic logic gates, known as Markov Brains, as our computational model organism. The ability of Markov Brains to learn is augmented by a novel adaptive component that can change its computational behavior based on feedback. We show that Markov Brains can indeed evolve to incorporate these feedback gates to improve their adaptability to variable environments. By combining these two methods, we now also implemented a computational model that can be used to study the evolution of learning.
Exploring the coevolution of predator and prey morphology and behavior
Feb 29, 2016
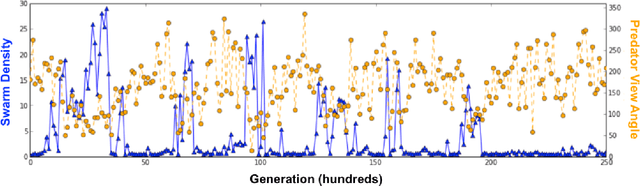
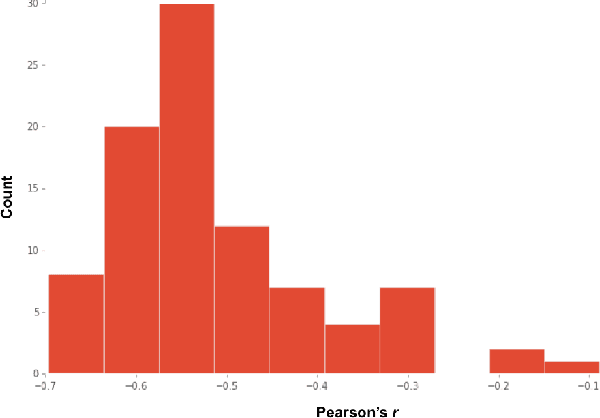
A common idiom in biology education states, "Eyes in the front, the animal hunts. Eyes on the side, the animal hides." In this paper, we explore one possible explanation for why predators tend to have forward-facing, high-acuity visual systems. We do so using an agent-based computational model of evolution, where predators and prey interact and adapt their behavior and morphology to one another over successive generations of evolution. In this model, we observe a coevolutionary cycle between prey swarming behavior and the predator's visual system, where the predator and prey continually adapt their visual system and behavior, respectively, over evolutionary time in reaction to one another due to the well-known "predator confusion effect." Furthermore, we provide evidence that the predator visual system is what drives this coevolutionary cycle, and suggest that the cycle could be closed if the predator evolves a hybrid visual system capable of narrow, high-acuity vision for tracking prey as well as broad, coarse vision for prey discovery. Thus, the conflicting demands imposed on a predator's visual system by the predator confusion effect could have led to the evolution of complex eyes in many predators.
* 8 pages, 8 figures, submitted to Artificial Life 2016 conference
Computational evolution of decision-making strategies
Sep 18, 2015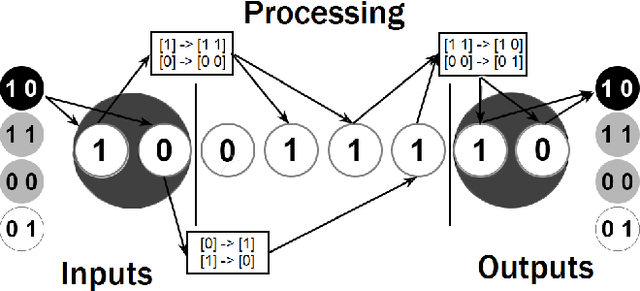
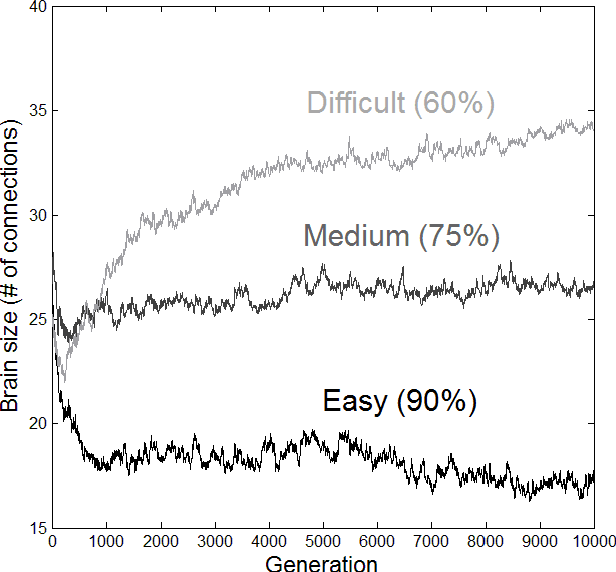
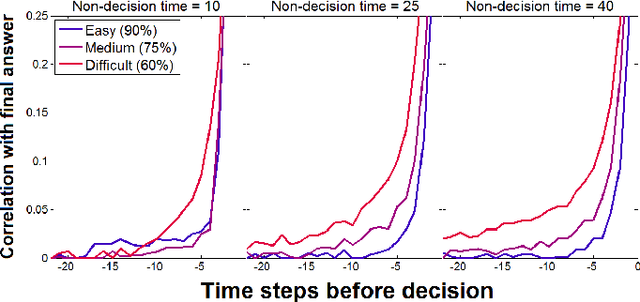
Most research on adaptive decision-making takes a strategy-first approach, proposing a method of solving a problem and then examining whether it can be implemented in the brain and in what environments it succeeds. We present a method for studying strategy development based on computational evolution that takes the opposite approach, allowing strategies to develop in response to the decision-making environment via Darwinian evolution. We apply this approach to a dynamic decision-making problem where artificial agents make decisions about the source of incoming information. In doing so, we show that the complexity of the brains and strategies of evolved agents are a function of the environment in which they develop. More difficult environments lead to larger brains and more information use, resulting in strategies resembling a sequential sampling approach. Less difficult environments drive evolution toward smaller brains and less information use, resulting in simpler heuristic-like strategies.
* Conference paper, 6 pages / 3 figures
Risk aversion as an evolutionary adaptation
Oct 23, 2013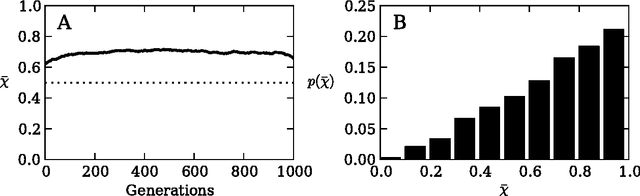
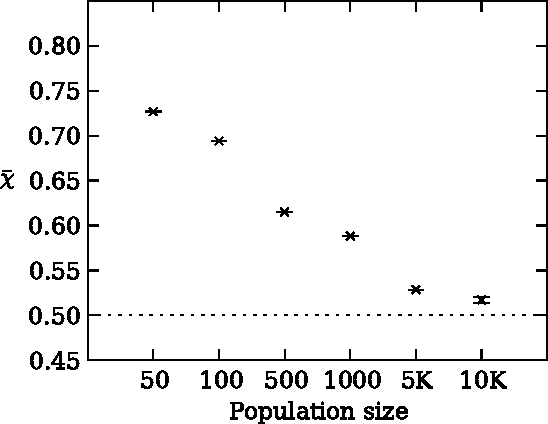
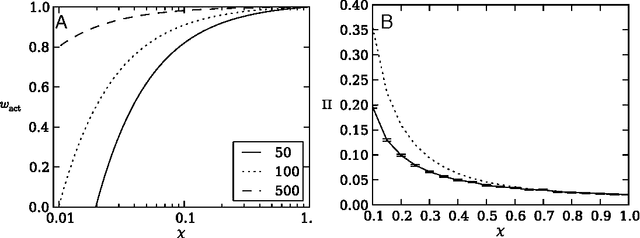
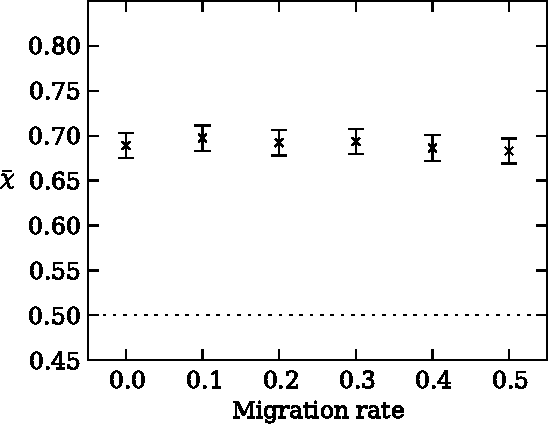
Risk aversion is a common behavior universal to humans and animals alike. Economists have traditionally defined risk preferences by the curvature of the utility function. Psychologists and behavioral economists also make use of concepts such as loss aversion and probability weighting to model risk aversion. Neurophysiological evidence suggests that loss aversion has its origins in relatively ancient neural circuitries (e.g., ventral striatum). Could there thus be an evolutionary origin to risk avoidance? We study this question by evolving strategies that adapt to play the equivalent mean payoff gamble. We hypothesize that risk aversion in the equivalent mean payoff gamble is beneficial as an adaptation to living in small groups, and find that a preference for risk averse strategies only evolves in small populations of less than 1,000 individuals, while agents exhibit no such strategy preference in larger populations. Further, we discover that risk aversion can also evolve in larger populations, but only when the population is segmented into small groups of around 150 individuals. Finally, we observe that risk aversion only evolves when the gamble is a rare event that has a large impact on the individual's fitness. These findings align with earlier reports that humans lived in small groups for a large portion of their evolutionary history. As such, we suggest that rare, high-risk, high-payoff events such as mating and mate competition could have driven the evolution of risk averse behavior in humans living in small groups.
* 18 pages, 7 figures