 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppearance Composing GAN: A General Method for Appearance-Controllable Human Video Motion Transfer
Paper and Code
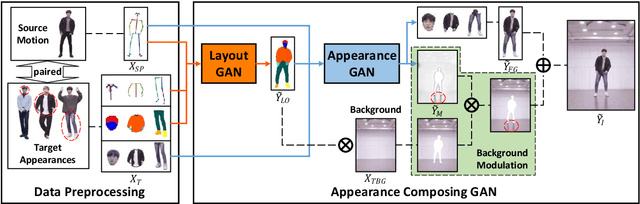
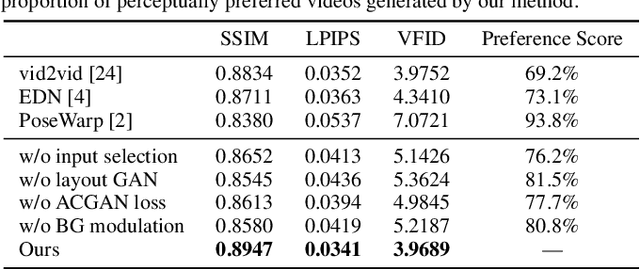
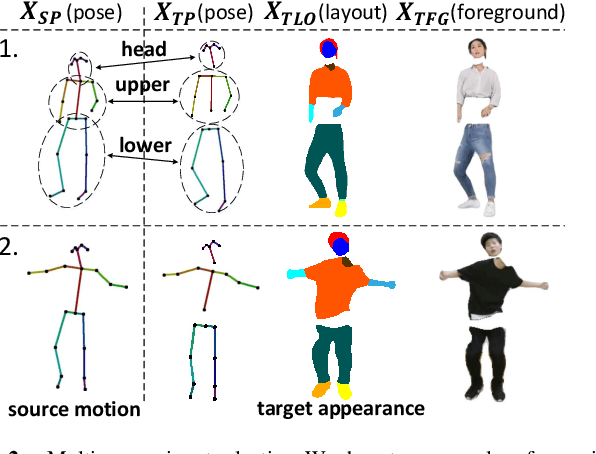
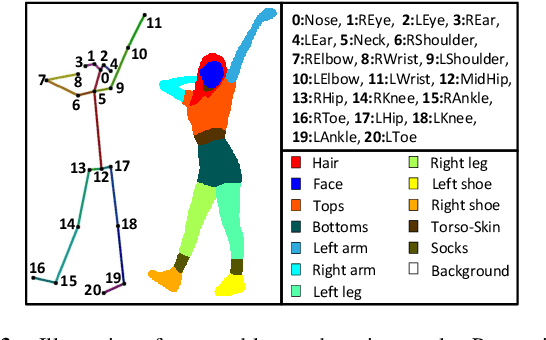
Due to the rapid development of GANs, there has been significant progress in the field of human video motion transfer which has a wide range of applications in computer vision and graphics. However, existing works only support motion-controllable video synthesis while appearances of different video components are bound together and uncontrollable, which means one person can only appear with the same clothing and background. Besides, most of these works are person-specific and require to train an individual model for each person, which is inflexible and inefficient. Therefore, we propose appearance composing GAN: a general method enabling control over not only human motions but also video appearances for arbitrary human subjects within only one model. The key idea is to exert layout-level appearance control on different video components and fuse them to compose the desired full video scene. Specifically, we achieve such appearance control by providing our model with optimal appearance conditioning inputs obtained separately for each component, allowing controllable component appearance synthesis for different people by changing the input appearance conditions accordingly. In terms of synthesis, a two-stage GAN framework is proposed to sequentially generate the desired body semantic layouts and component appearances, both are consistent with the input human motions and appearance conditions. Coupled with our ACGAN loss and background modulation block, the proposed method can achieve general and appearance-controllable human video motion transfer. Moreover, we build a dataset containing a large number of dance videos for training and evaluation. Experimental results show that, when applied to motion transfer tasks involving a variety of human subjects, our proposed method achieves appearance-controllable synthesis with higher video quality than state-of-arts based on only one-time training.