 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeDi: Joint-Image Diffusion Models for Finetuning-Free Personalized Text-to-Image Generation
Paper and Code
Jul 08, 2024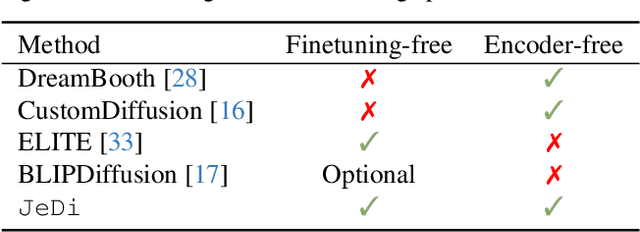
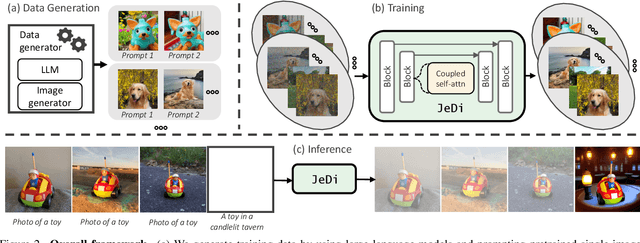
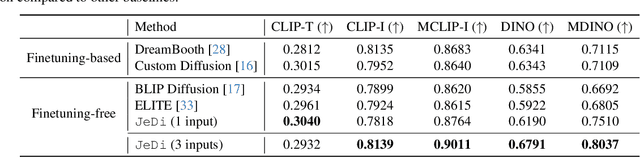
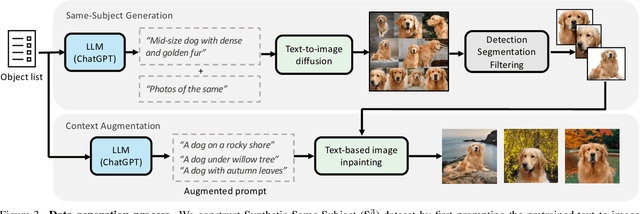
Personalized text-to-image generation models enable users to create images that depict their individual possessions in diverse scenes, finding applications in various domains. To achieve the personalization capability, existing methods rely on finetuning a text-to-image foundation model on a user's custom dataset, which can be non-trivial for general users, resource-intensive, and time-consuming. Despite attempts to develop finetuning-free methods, their generation quality is much lower compared to their finetuning counterparts. In this paper, we propose Joint-Image Diffusion (\jedi), an effective technique for learning a finetuning-free personalization model. Our key idea is to learn the joint distribution of multiple related text-image pairs that share a common subject. To facilitate learning, we propose a scalable synthetic dataset generation technique. Once trained, our model enables fast and easy personalization at test time by simply using reference images as input during the sampling process. Our approach does not require any expensive optimization process or additional modules and can faithfully preserve the identity represented by any number of reference images. Experimental results show that our model achieves state-of-the-art generation quality, both quantitatively and qualitatively, significantly outperforming both the prior finetuning-based and finetuning-free personalization baselines.