 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOET: Protocol Optimization via Eligibility Tuning
Jan 30, 2026Eligibility criteria (EC) are essential for clinical trial design, yet drafting them remains a time-intensive and cognitively demanding task for clinicians. Existing automated approaches often fall at two extremes either requiring highly structured inputs, such as predefined entities to generate specific criteria, or relying on end-to-end systems that produce full eligibility criteria from minimal input such as trial descriptions limiting their practical utility. In this work, we propose a guided generation framework that introduces interpretable semantic axes, such as Demographics, Laboratory Parameters, and Behavioral Factors, to steer EC generation. These axes, derived using large language models, offer a middle ground between specificity and usability, enabling clinicians to guide generation without specifying exact entities. In addition, we present a reusable rubric-based evaluation framework that assesses generated criteria along clinically meaningful dimensions. Our results show that our guided generation approach consistently outperforms unguided generation in both automatic, rubric-based and clinician evaluations, offering a practical and interpretable solution for AI-assisted trial design.
$\texttt{AMEND++}$: Benchmarking Eligibility Criteria Amendments in Clinical Trials
Jan 09, 2026Clinical trial amendments frequently introduce delays, increased costs, and administrative burden, with eligibility criteria being the most commonly amended component. We introduce \textit{eligibility criteria amendment prediction}, a novel NLP task that aims to forecast whether the eligibility criteria of an initial trial protocol will undergo future amendments. To support this task, we release $\texttt{AMEND++}$, a benchmark suite comprising two datasets: $\texttt{AMEND}$, which captures eligibility-criteria version histories and amendment labels from public clinical trials, and $\verb|AMEND_LLM|$, a refined subset curated using an LLM-based denoising pipeline to isolate substantive changes. We further propose $\textit{Change-Aware Masked Language Modeling}$ (CAMLM), a revision-aware pretraining strategy that leverages historical edits to learn amendment-sensitive representations. Experiments across diverse baselines show that CAMLM consistently improves amendment prediction, enabling more robust and cost-effective clinical trial design.
SECRET: Semi-supervised Clinical Trial Document Similarity Search
May 16, 2025Clinical trials are vital for evaluation of safety and efficacy of new treatments. However, clinical trials are resource-intensive, time-consuming and expensive to conduct, where errors in trial design, reduced efficacy, and safety events can result in significant delays, financial losses, and damage to reputation. These risks underline the importance of informed and strategic decisions in trial design to mitigate these risks and improve the chances of a successful trial. Identifying similar historical trials is critical as these trials can provide an important reference for potential pitfalls and challenges including serious adverse events, dosage inaccuracies, recruitment difficulties, patient adherence issues, etc. Addressing these challenges in trial design can lead to development of more effective study protocols with optimized patient safety and trial efficiency. In this paper, we present a novel method to identify similar historical trials by summarizing clinical trial protocols and searching for similar trials based on a query trial's protocol. Our approach significantly outperforms all baselines, achieving up to a 78% improvement in recall@1 and a 53% improvement in precision@1 over the best baseline. We also show that our method outperforms all other baselines in partial trial similarity search and zero-shot patient-trial matching, highlighting its superior utility in these tasks.
SynRL: Aligning Synthetic Clinical Trial Data with Human-preferred Clinical Endpoints Using Reinforcement Learning
Nov 11, 2024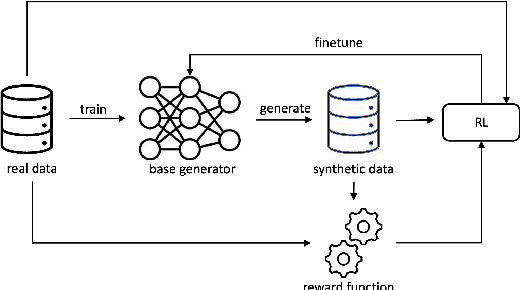

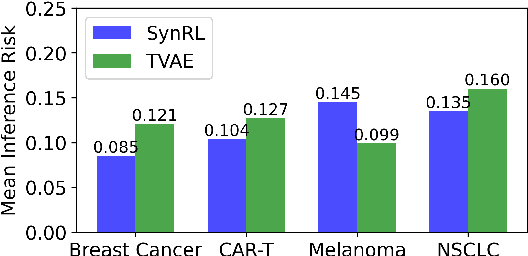
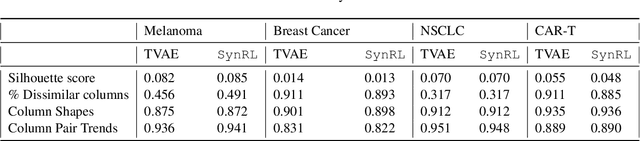
Each year, hundreds of clinical trials are conducted to evaluate new medical interventions, but sharing patient records from these trials with other institutions can be challenging due to privacy concerns and federal regulations. To help mitigate privacy concerns, researchers have proposed methods for generating synthetic patient data. However, existing approaches for generating synthetic clinical trial data disregard the usage requirements of these data, including maintaining specific properties of clinical outcomes, and only use post hoc assessments that are not coupled with the data generation process. In this paper, we propose SynRL which leverages reinforcement learning to improve the performance of patient data generators by customizing the generated data to meet the user-specified requirements for synthetic data outcomes and endpoints. Our method includes a data value critic function to evaluate the quality of the generated data and uses reinforcement learning to align the data generator with the users' needs based on the critic's feedback. We performed experiments on four clinical trial datasets and demonstrated the advantages of SynRL in improving the quality of the generated synthetic data while keeping the privacy risks low. We also show that SynRL can be utilized as a general framework that can customize data generation of multiple types of synthetic data generators. Our code is available at https://anonymous.4open.science/r/SynRL-DB0F/.
Synthetic Patient-Physician Dialogue Generation from Clinical Notes Using LLM
Aug 12, 2024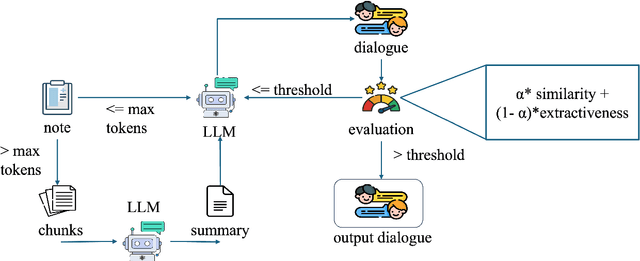
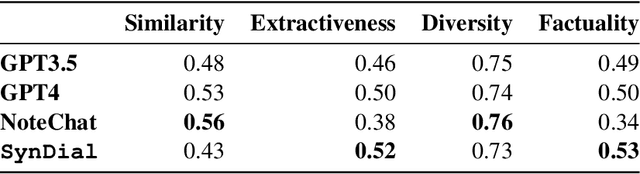
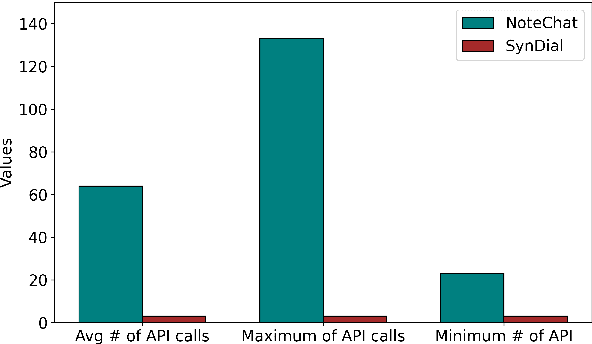
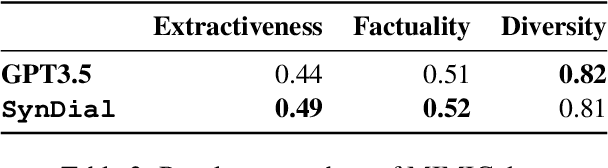
Medical dialogue systems (MDS) enhance patient-physician communication, improve healthcare accessibility, and reduce costs. However, acquiring suitable data to train these systems poses significant challenges. Privacy concerns prevent the use of real conversations, necessitating synthetic alternatives. Synthetic dialogue generation from publicly available clinical notes offers a promising solution to this issue, providing realistic data while safeguarding privacy. Our approach, SynDial, uses a single LLM iteratively with zero-shot prompting and a feedback loop to generate and refine high-quality synthetic dialogues. The feedback consists of weighted evaluation scores for similarity and extractiveness. The iterative process ensures dialogues meet predefined thresholds, achieving superior extractiveness as a result of the feedback loop. Additionally, evaluation shows that the generated dialogues excel in factuality metric compared to the baselines and has comparable diversity scores with GPT4.
Automatically Labeling $200B Life-Saving Datasets: A Large Clinical Trial Outcome Benchmark
Jun 13, 2024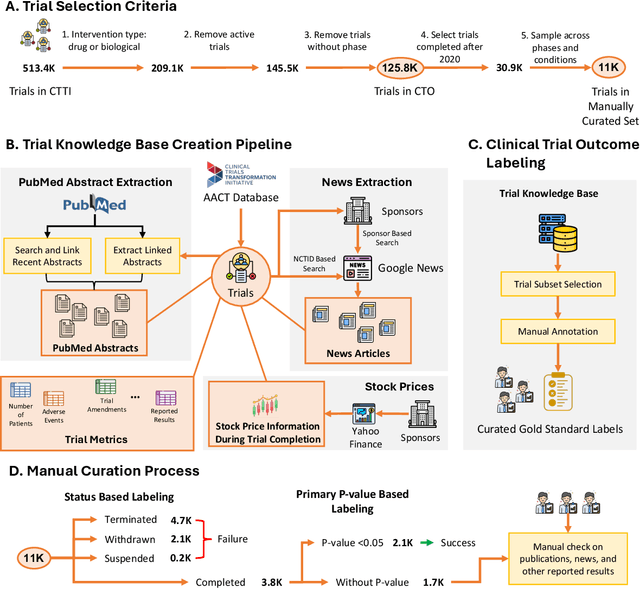
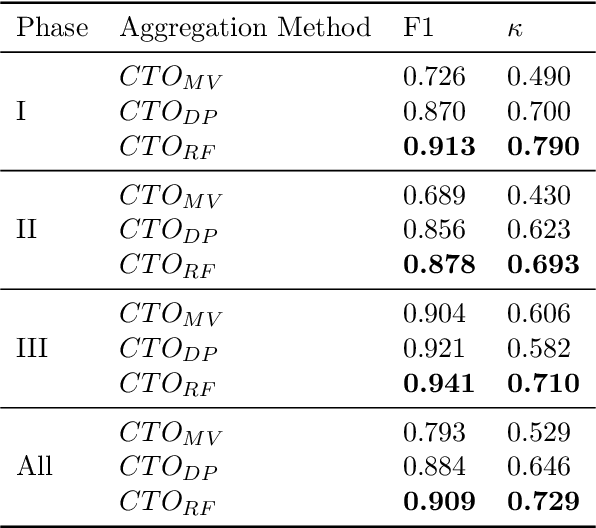
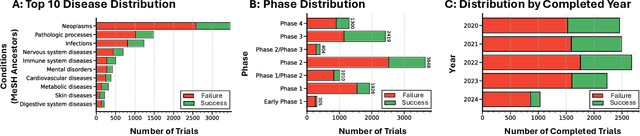
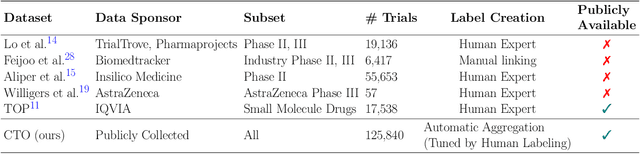
The global cost of drug discovery and development exceeds $200 billion annually. The main results of drug discovery and development are the outcomes of clinical trials, which directly influence the regulatory approval of new drug candidates and ultimately affect patient outcomes. Despite their significance, large-scale, high-quality clinical trial outcome data are not readily available to the public. Suppose a large clinical trial outcome dataset is provided; machine learning researchers can potentially develop accurate prediction models using past trials and outcome labels, which could help prioritize and optimize therapeutic programs, ultimately benefiting patients. This paper introduces Clinical Trial Outcome (CTO) dataset, the largest trial outcome dataset with around 479K clinical trials, aggregating outcomes from multiple sources of weakly supervised labels, minimizing the noise from individual sources, and eliminating the need for human annotation. These sources include large language model (LLM) decisions on trial-related documents, news headline sentiments, stock prices of trial sponsors, trial linkages across phases, and other signals such as patient dropout rates and adverse events. CTO's labels show unprecedented agreement with supervised clinical trial outcome labels from test split of the supervised TOP dataset, with a 91 F1.
TopicAdapt- An Inter-Corpora Topics Adaptation Approach
Oct 08, 2023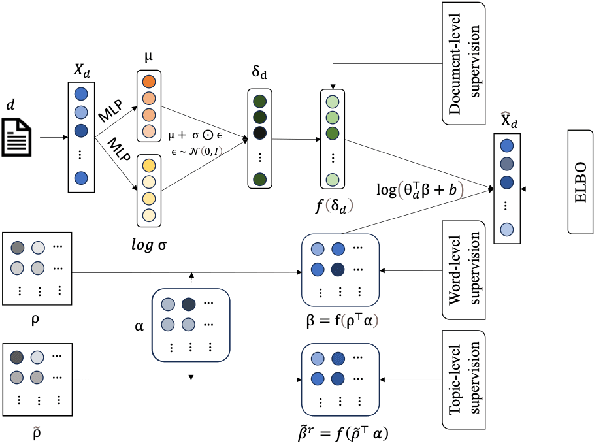
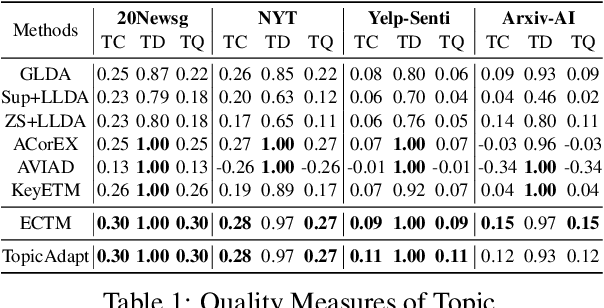
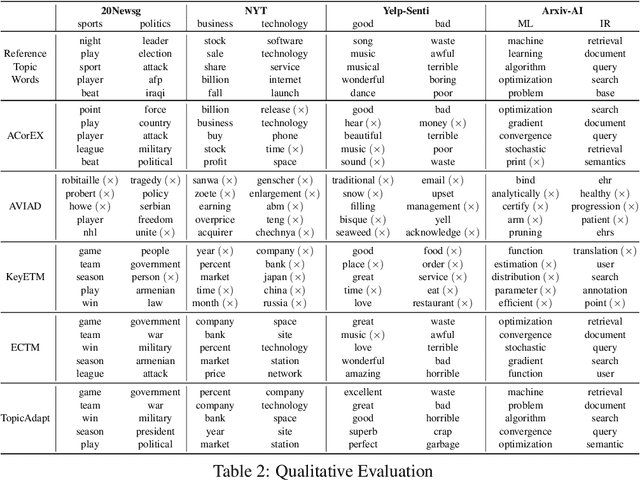

Topic models are popular statistical tools for detecting latent semantic topics in a text corpus. They have been utilized in various applications across different fields. However, traditional topic models have some limitations, including insensitivity to user guidance, sensitivity to the amount and quality of data, and the inability to adapt learned topics from one corpus to another. To address these challenges, this paper proposes a neural topic model, TopicAdapt, that can adapt relevant topics from a related source corpus and also discover new topics in a target corpus that are absent in the source corpus. The proposed model offers a promising approach to improve topic modeling performance in practical scenarios. Experiments over multiple datasets from diverse domains show the superiority of the proposed model against the state-of-the-art topic models.