 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{AMEND++}$: Benchmarking Eligibility Criteria Amendments in Clinical Trials
Jan 09, 2026Clinical trial amendments frequently introduce delays, increased costs, and administrative burden, with eligibility criteria being the most commonly amended component. We introduce \textit{eligibility criteria amendment prediction}, a novel NLP task that aims to forecast whether the eligibility criteria of an initial trial protocol will undergo future amendments. To support this task, we release $\texttt{AMEND++}$, a benchmark suite comprising two datasets: $\texttt{AMEND}$, which captures eligibility-criteria version histories and amendment labels from public clinical trials, and $\verb|AMEND_LLM|$, a refined subset curated using an LLM-based denoising pipeline to isolate substantive changes. We further propose $\textit{Change-Aware Masked Language Modeling}$ (CAMLM), a revision-aware pretraining strategy that leverages historical edits to learn amendment-sensitive representations. Experiments across diverse baselines show that CAMLM consistently improves amendment prediction, enabling more robust and cost-effective clinical trial design.
SynRL: Aligning Synthetic Clinical Trial Data with Human-preferred Clinical Endpoints Using Reinforcement Learning
Nov 11, 2024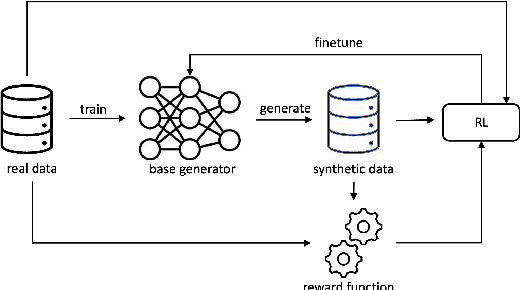

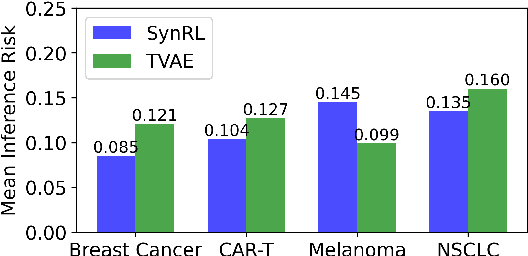
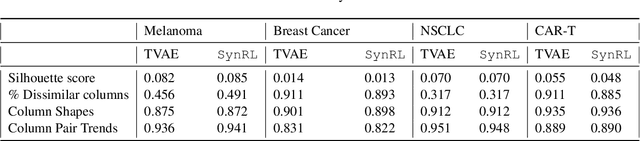
Each year, hundreds of clinical trials are conducted to evaluate new medical interventions, but sharing patient records from these trials with other institutions can be challenging due to privacy concerns and federal regulations. To help mitigate privacy concerns, researchers have proposed methods for generating synthetic patient data. However, existing approaches for generating synthetic clinical trial data disregard the usage requirements of these data, including maintaining specific properties of clinical outcomes, and only use post hoc assessments that are not coupled with the data generation process. In this paper, we propose SynRL which leverages reinforcement learning to improve the performance of patient data generators by customizing the generated data to meet the user-specified requirements for synthetic data outcomes and endpoints. Our method includes a data value critic function to evaluate the quality of the generated data and uses reinforcement learning to align the data generator with the users' needs based on the critic's feedback. We performed experiments on four clinical trial datasets and demonstrated the advantages of SynRL in improving the quality of the generated synthetic data while keeping the privacy risks low. We also show that SynRL can be utilized as a general framework that can customize data generation of multiple types of synthetic data generators. Our code is available at https://anonymous.4open.science/r/SynRL-DB0F/.
TrialSynth: Generation of Synthetic Sequential Clinical Trial Data
Sep 11, 2024


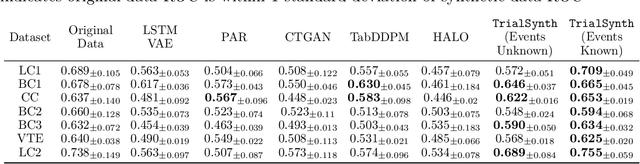
Analyzing data from past clinical trials is part of the ongoing effort to optimize the design, implementation, and execution of new clinical trials and more efficiently bring life-saving interventions to market. While there have been recent advances in the generation of static context synthetic clinical trial data, due to both limited patient availability and constraints imposed by patient privacy needs, the generation of fine-grained synthetic time-sequential clinical trial data has been challenging. Given that patient trajectories over an entire clinical trial are of high importance for optimizing trial design and efforts to prevent harmful adverse events, there is a significant need for the generation of high-fidelity time-sequence clinical trial data. Here we introduce TrialSynth, a Variational Autoencoder (VAE) designed to address the specific challenges of generating synthetic time-sequence clinical trial data. Distinct from related clinical data VAE methods, the core of our method leverages Hawkes Processes (HP), which are particularly well-suited for modeling event-type and time gap prediction needed to capture the structure of sequential clinical trial data. Our experiments demonstrate that TrialSynth surpasses the performance of other comparable methods that can generate sequential clinical trial data, in terms of both fidelity and in enabling the generation of highly accurate event sequences across multiple real-world sequential event datasets with small patient source populations when using minimal external information. Notably, our empirical findings highlight that TrialSynth not only outperforms existing clinical sequence-generating methods but also produces data with superior utility while empirically preserving patient privacy.