 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Challenges in Tabular Membership Inference Attacks
Jan 22, 2026Membership Inference Attacks (MIAs) are currently a dominant approach for evaluating privacy in machine learning applications. Despite their significance in identifying records belonging to the training dataset, several concerns remain unexplored, particularly with regard to tabular data. In this paper, first, we provide an extensive review and analysis of MIAs considering two main learning paradigms: centralized and federated learning. We extend and refine the taxonomy for both. Second, we demonstrate the efficacy of MIAs in tabular data using several attack strategies, also including defenses. Furthermore, in a federated learning scenario, we consider the threat posed by an outsider adversary, which is often neglected. Third, we demonstrate the high vulnerability of single-outs (records with a unique signature) to MIAs. Lastly, we explore how MIAs transfer across model architectures. Our results point towards a general poor performance of these attacks in tabular data which contrasts with previous state-of-the-art. Notably, even attacks with limited attack performance can still successfully expose a large portion of single-outs. Moreover, our findings suggest that using different surrogate models makes MIAs more effective.
Secure Visual Data Processing via Federated Learning
Feb 09, 2025



As the demand for privacy in visual data management grows, safeguarding sensitive information has become a critical challenge. This paper addresses the need for privacy-preserving solutions in large-scale visual data processing by leveraging federated learning. Although there have been developments in this field, previous research has mainly focused on integrating object detection with either anonymization or federated learning. However, these pairs often fail to address complex privacy concerns. On the one hand, object detection with anonymization alone can be vulnerable to reverse techniques. On the other hand, federated learning may not provide sufficient privacy guarantees. Therefore, we propose a new approach that combines object detection, federated learning and anonymization. Combining these three components aims to offer a robust privacy protection strategy by addressing different vulnerabilities in visual data. Our solution is evaluated against traditional centralized models, showing that while there is a slight trade-off in accuracy, the privacy benefits are substantial, making it well-suited for privacy sensitive applications.
Automated Privacy-Preserving Techniques via Meta-Learning
Jun 24, 2024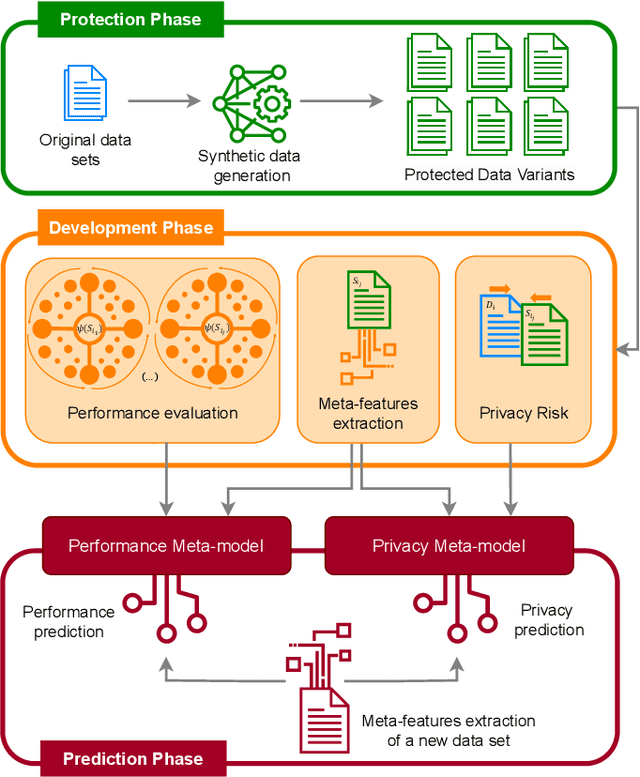
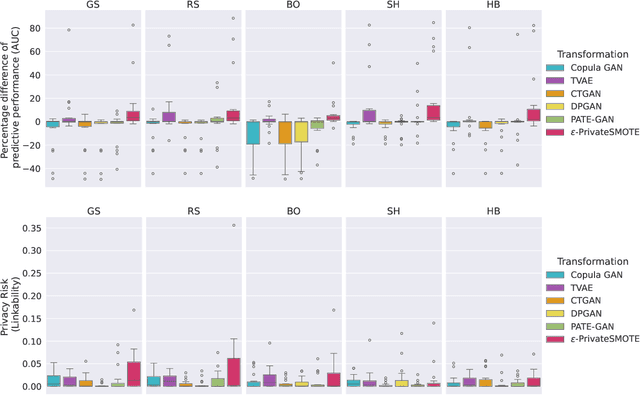
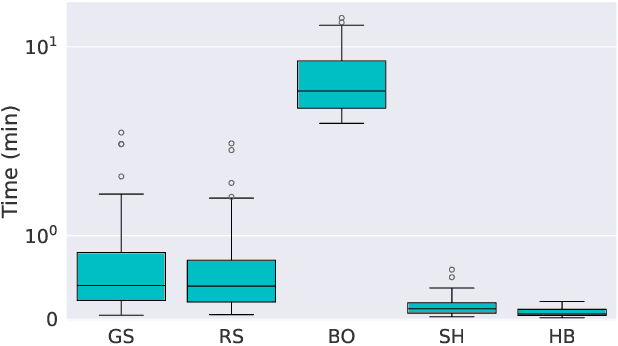
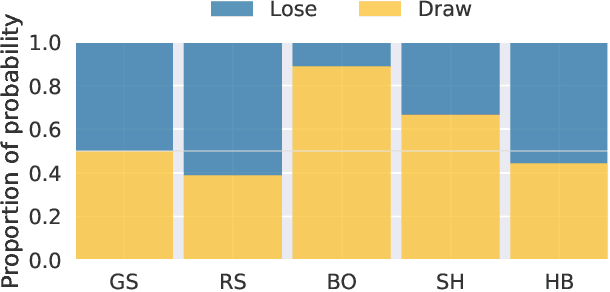
Sharing private data for learning tasks is pivotal for transparent and secure machine learning applications. Many privacy-preserving techniques have been proposed for this task aiming to transform the data while ensuring the privacy of individuals. Some of these techniques have been incorporated into tools, whereas others are accessed through various online platforms. However, such tools require manual configuration, which can be complex and time-consuming. Moreover, they require substantial expertise, potentially restricting their use to those with advanced technical knowledge. In this paper, we propose AUTOPRIV, the first automated privacy-preservation method, that eliminates the need for any manual configuration. AUTOPRIV employs meta-learning to automate the de-identification process, facilitating the secure release of data for machine learning tasks. The main goal is to anticipate the predictive performance and privacy risk of a large set of privacy configurations. We provide a ranked list of the most promising solutions, which are likely to achieve an optimal approximation within a new domain. AUTOPRIV is highly effective as it reduces computational complexity and energy consumption considerably.
Synthetic Data Outliers: Navigating Identity Disclosure
Jun 04, 2024



Multiple synthetic data generation models have emerged, among which deep learning models have become the vanguard due to their ability to capture the underlying characteristics of the original data. However, the resemblance of the synthetic to the original data raises important questions on the protection of individuals' privacy. As synthetic data is perceived as a means to fully protect personal information, most current related work disregards the impact of re-identification risk. In particular, limited attention has been given to exploring outliers, despite their privacy relevance. In this work, we analyze the privacy of synthetic data w.r.t the outliers. Our main findings suggest that outliers re-identification via linkage attack is feasible and easily achieved. Furthermore, additional safeguards such as differential privacy can prevent re-identification, albeit at the expense of the data utility.
A Three-Way Knot: Privacy, Fairness, and Predictive Performance Dynamics
Jun 27, 2023



As the frontier of machine learning applications moves further into human interaction, multiple concerns arise regarding automated decision-making. Two of the most critical issues are fairness and data privacy. On the one hand, one must guarantee that automated decisions are not biased against certain groups, especially those unprotected or marginalized. On the other hand, one must ensure that the use of personal information fully abides by privacy regulations and that user identities are kept safe. The balance between privacy, fairness, and predictive performance is complex. However, despite their potential societal impact, we still demonstrate a poor understanding of the dynamics between these optimization vectors. In this paper, we study this three-way tension and how the optimization of each vector impacts others, aiming to inform the future development of safe applications. In light of claims that predictive performance and fairness can be jointly optimized, we find this is only possible at the expense of data privacy. Overall, experimental results show that one of the vectors will be penalized regardless of which of the three we optimize. Nonetheless, we find promising avenues for future work in joint optimization solutions, where smaller trade-offs are observed between the three vectors.
Privacy-Preserving Data Synthetisation for Secure Information Sharing
Dec 01, 2022



We can protect user data privacy via many approaches, such as statistical transformation or generative models. However, each of them has critical drawbacks. On the one hand, creating a transformed data set using conventional techniques is highly time-consuming. On the other hand, in addition to long training phases, recent deep learning-based solutions require significant computational resources. In this paper, we propose PrivateSMOTE, a technique designed for competitive effectiveness in protecting cases at maximum risk of re-identification while requiring much less time and computational resources. It works by synthetic data generation via interpolation to obfuscate high-risk cases while minimizing data utility loss of the original data. Compared to multiple conventional and state-of-the-art privacy-preservation methods on 20 data sets, PrivateSMOTE demonstrates competitive results in re-identification risk. Also, it presents similar or higher predictive performance than the baselines, including generative adversarial networks and variational autoencoders, reducing their energy consumption and time requirements by a minimum factor of 9 and 12, respectively.
Towards a Data Privacy-Predictive Performance Trade-off
Jan 13, 2022
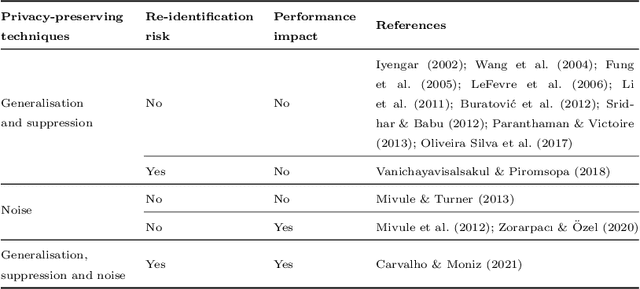


Machine learning is increasingly used in the most diverse applications and domains, whether in healthcare, to predict pathologies, or in the financial sector to detect fraud. One of the linchpins for efficiency and accuracy in machine learning is data utility. However, when it contains personal information, full access may be restricted due to laws and regulations aiming to protect individuals' privacy. Therefore, data owners must ensure that any data shared guarantees such privacy. Removal or transformation of private information (de-identification) are among the most common techniques. Intuitively, one can anticipate that reducing detail or distorting information would result in losses for model predictive performance. However, previous work concerning classification tasks using de-identified data generally demonstrates that predictive performance can be preserved in specific applications. In this paper, we aim to evaluate the existence of a trade-off between data privacy and predictive performance in classification tasks. We leverage a large set of privacy-preserving techniques and learning algorithms to provide an assessment of re-identification ability and the impact of transformed variants on predictive performance. Unlike previous literature, we confirm that the higher the level of privacy (lower re-identification risk), the higher the impact on predictive performance, pointing towards clear evidence of a trade-off.