 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Data Synthetisation for Secure Information Sharing
Dec 01, 2022



We can protect user data privacy via many approaches, such as statistical transformation or generative models. However, each of them has critical drawbacks. On the one hand, creating a transformed data set using conventional techniques is highly time-consuming. On the other hand, in addition to long training phases, recent deep learning-based solutions require significant computational resources. In this paper, we propose PrivateSMOTE, a technique designed for competitive effectiveness in protecting cases at maximum risk of re-identification while requiring much less time and computational resources. It works by synthetic data generation via interpolation to obfuscate high-risk cases while minimizing data utility loss of the original data. Compared to multiple conventional and state-of-the-art privacy-preservation methods on 20 data sets, PrivateSMOTE demonstrates competitive results in re-identification risk. Also, it presents similar or higher predictive performance than the baselines, including generative adversarial networks and variational autoencoders, reducing their energy consumption and time requirements by a minimum factor of 9 and 12, respectively.
Towards a Data Privacy-Predictive Performance Trade-off
Jan 13, 2022
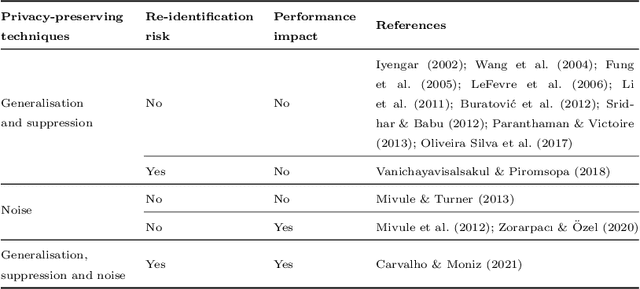


Machine learning is increasingly used in the most diverse applications and domains, whether in healthcare, to predict pathologies, or in the financial sector to detect fraud. One of the linchpins for efficiency and accuracy in machine learning is data utility. However, when it contains personal information, full access may be restricted due to laws and regulations aiming to protect individuals' privacy. Therefore, data owners must ensure that any data shared guarantees such privacy. Removal or transformation of private information (de-identification) are among the most common techniques. Intuitively, one can anticipate that reducing detail or distorting information would result in losses for model predictive performance. However, previous work concerning classification tasks using de-identified data generally demonstrates that predictive performance can be preserved in specific applications. In this paper, we aim to evaluate the existence of a trade-off between data privacy and predictive performance in classification tasks. We leverage a large set of privacy-preserving techniques and learning algorithms to provide an assessment of re-identification ability and the impact of transformed variants on predictive performance. Unlike previous literature, we confirm that the higher the level of privacy (lower re-identification risk), the higher the impact on predictive performance, pointing towards clear evidence of a trade-off.