 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Psychological Generalist AI: A Survey of Current Applications of Large Language Models and Future Prospects
Dec 01, 2023


The complexity of psychological principles underscore a significant societal challenge, given the vast social implications of psychological problems. Bridging the gap between understanding these principles and their actual clinical and real-world applications demands rigorous exploration and adept implementation. In recent times, the swift advancement of highly adaptive and reusable artificial intelligence (AI) models has emerged as a promising way to unlock unprecedented capabilities in the realm of psychology. This paper emphasizes the importance of performance validation for these large-scale AI models, emphasizing the need to offer a comprehensive assessment of their verification from diverse perspectives. Moreover, we review the cutting-edge advancements and practical implementations of these expansive models in psychology, highlighting pivotal work spanning areas such as social media analytics, clinical nursing insights, vigilant community monitoring, and the nuanced exploration of psychological theories. Based on our review, we project an acceleration in the progress of psychological fields, driven by these large-scale AI models. These future generalist AI models harbor the potential to substantially curtail labor costs and alleviate social stress. However, this forward momentum will not be without its set of challenges, especially when considering the paradigm changes and upgrades required for medical instrumentation and related applications.
Evaluating the Efficacy of Supervised Learning vs Large Language Models for Identifying Cognitive Distortions and Suicidal Risks in Chinese Social Media
Sep 07, 2023
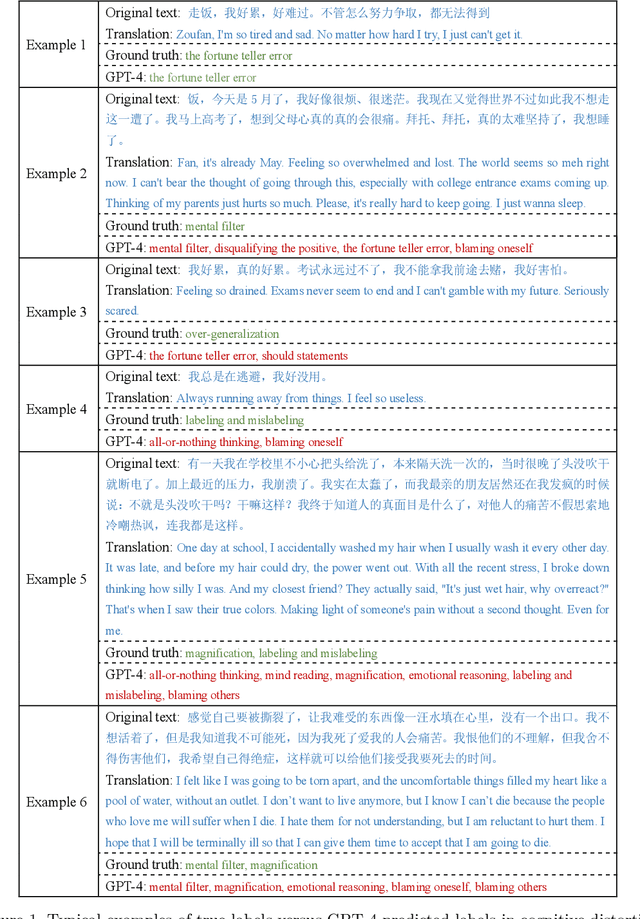

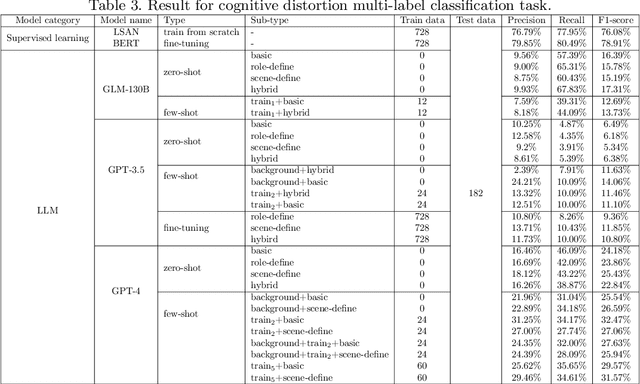
Large language models, particularly those akin to the rapidly progressing GPT series, are gaining traction for their expansive influence. While there is keen interest in their applicability within medical domains such as psychology, tangible explorations on real-world data remain scant. Concurrently, users on social media platforms are increasingly vocalizing personal sentiments; under specific thematic umbrellas, these sentiments often manifest as negative emotions, sometimes escalating to suicidal inclinations. Timely discernment of such cognitive distortions and suicidal risks is crucial to effectively intervene and potentially avert dire circumstances. Our study ventured into this realm by experimenting on two pivotal tasks: suicidal risk and cognitive distortion identification on Chinese social media platforms. Using supervised learning as a baseline, we examined and contrasted the efficacy of large language models via three distinct strategies: zero-shot, few-shot, and fine-tuning. Our findings revealed a discernible performance gap between the large language models and traditional supervised learning approaches, primarily attributed to the models' inability to fully grasp subtle categories. Notably, while GPT-4 outperforms its counterparts in multiple scenarios, GPT-3.5 shows significant enhancement in suicide risk classification after fine-tuning. To our knowledge, this investigation stands as the maiden attempt at gauging large language models on Chinese social media tasks. This study underscores the forward-looking and transformative implications of using large language models in the field of psychology. It lays the groundwork for future applications in psychological research and practice.