 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Music and Text with Crowdsourced Music Comments: A Sequence-to-Sequence Framework for Thematic Music Comments Generation
Paper and Code
Sep 05, 2022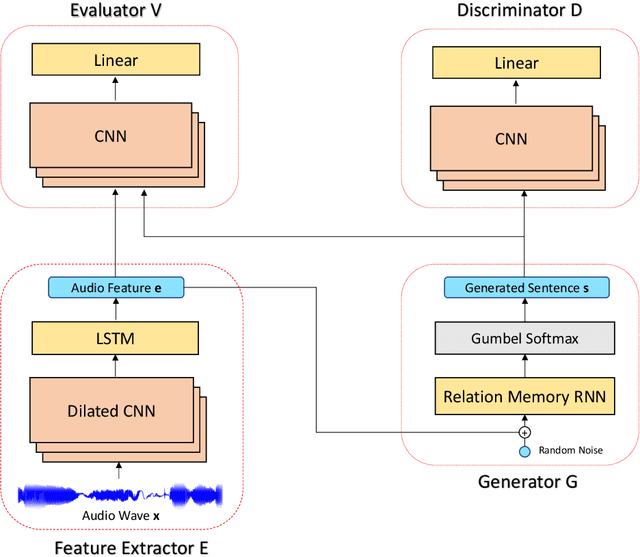
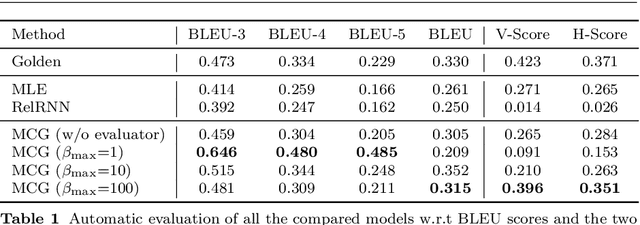
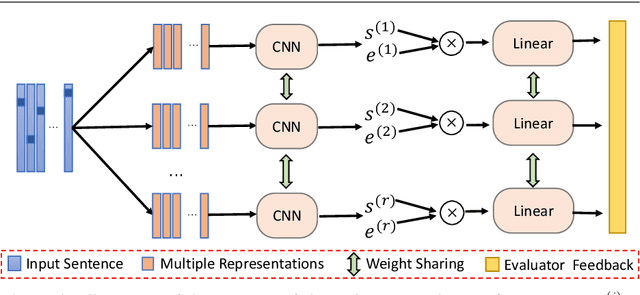

We consider a novel task of automatically generating text descriptions of music. Compared with other well-established text generation tasks such as image caption, the scarcity of well-paired music and text datasets makes it a much more challenging task. In this paper, we exploit the crowd-sourced music comments to construct a new dataset and propose a sequence-to-sequence model to generate text descriptions of music. More concretely, we use the dilated convolutional layer as the basic component of the encoder and a memory based recurrent neural network as the decoder. To enhance the authenticity and thematicity of generated texts, we further propose to fine-tune the model with a discriminator as well as a novel topic evaluator. To measure the quality of generated texts, we also propose two new evaluation metrics, which are more aligned with human evaluation than traditional metrics such as BLEU. Experimental results verify that our model is capable of generating fluent and meaningful comments while containing thematic and content information of the original music.