 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Training of Deep Neural Networks with Theoretical Analysis: Under SSP Setting
Paper and Code
Dec 11, 2015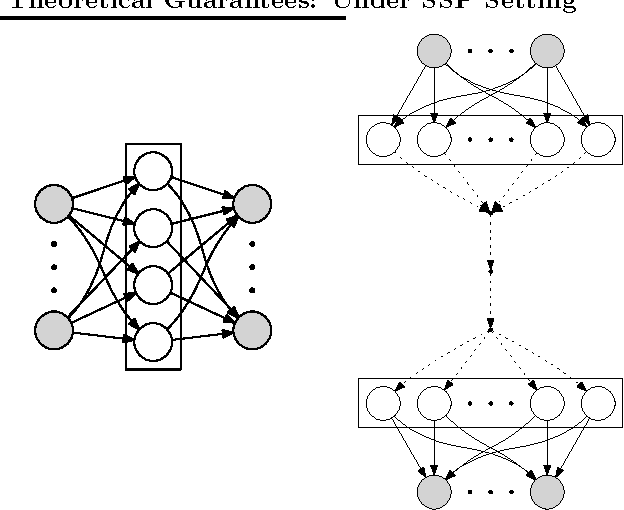

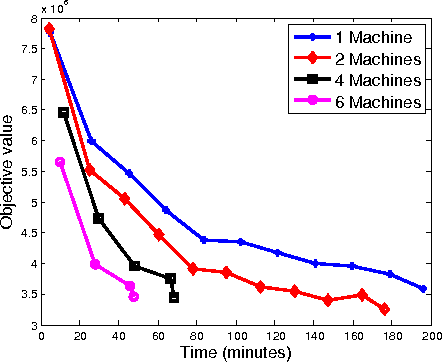
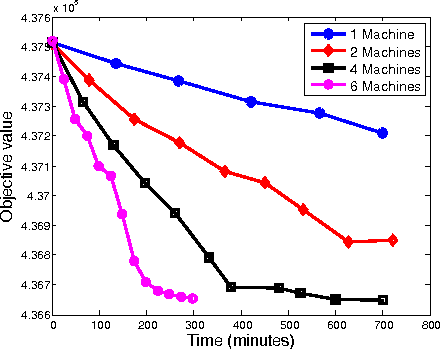
We propose a distributed approach to train deep neural networks (DNNs), which has guaranteed convergence theoretically and great scalability empirically: close to 6 times faster on instance of ImageNet data set when run with 6 machines. The proposed scheme is close to optimally scalable in terms of number of machines, and guaranteed to converge to the same optima as the undistributed setting. The convergence and scalability of the distributed setting is shown empirically across different datasets (TIMIT and ImageNet) and machine learning tasks (image classification and phoneme extraction). The convergence analysis provides novel insights into this complex learning scheme, including: 1) layerwise convergence, and 2) convergence of the weights in probability.