 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Distributions: Explicit Modeling of Scene Content is Key in Zero-Shot Video Captioning
Mar 31, 2025
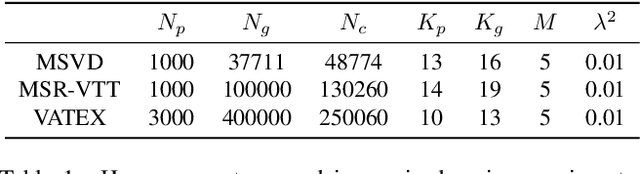

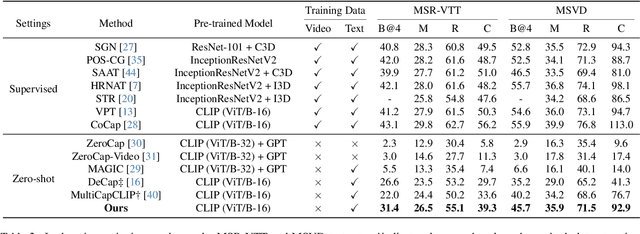
Zero-shot video captioning requires that a model generate high-quality captions without human-annotated video-text pairs for training. State-of-the-art approaches to the problem leverage CLIP to extract visual-relevant textual prompts to guide language models in generating captions. These methods tend to focus on one key aspect of the scene and build a caption that ignores the rest of the visual input. To address this issue, and generate more accurate and complete captions, we propose a novel progressive multi-granularity textual prompting strategy for zero-shot video captioning. Our approach constructs three distinct memory banks, encompassing noun phrases, scene graphs of noun phrases, and entire sentences. Moreover, we introduce a category-aware retrieval mechanism that models the distribution of natural language surrounding the specific topics in question. Extensive experiments demonstrate the effectiveness of our method with 5.7%, 16.2%, and 3.4% improvements in terms of the main metric CIDEr on MSR-VTT, MSVD, and VATEX benchmarks compared to existing state-of-the-art.