 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Temporal Consistency for Point-Level Weakly-Supervised Temporal Action Localization
Feb 05, 2026Point-supervised Temporal Action Localization (PTAL) adopts a lightly frame-annotated paradigm (\textit{i.e.}, labeling only a single frame per action instance) to train a model to effectively locate action instances within untrimmed videos. Most existing approaches design the task head of models with only a point-supervised snippet-level classification, without explicit modeling of understanding temporal relationships among frames of an action. However, understanding the temporal relationships of frames is crucial because it can help a model understand how an action is defined and therefore benefits localizing the full frames of an action. To this end, in this paper, we design a multi-task learning framework that fully utilizes point supervision to boost the model's temporal understanding capability for action localization. Specifically, we design three self-supervised temporal understanding tasks: (i) Action Completion, (ii) Action Order Understanding, and (iii) Action Regularity Understanding. These tasks help a model understand the temporal consistency of actions across videos. To the best of our knowledge, this is the first attempt to explicitly explore temporal consistency for point supervision action localization. Extensive experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method compared to several state-of-the-art approaches.
Boosting Point-supervised Temporal Action Localization via Text Refinement and Alignment
Feb 01, 2026Recently, point-supervised temporal action localization has gained significant attention for its effective balance between labeling costs and localization accuracy. However, current methods only consider features from visual inputs, neglecting helpful semantic information from the text side. To address this issue, we propose a Text Refinement and Alignment (TRA) framework that effectively utilizes textual features from visual descriptions to complement the visual features as they are semantically rich. This is achieved by designing two new modules for the original point-supervised framework: a Point-based Text Refinement module (PTR) and a Point-based Multimodal Alignment module (PMA). Specifically, we first generate descriptions for video frames using a pre-trained multimodal model. Next, PTR refines the initial descriptions by leveraging point annotations together with multiple pre-trained models. PMA then projects all features into a unified semantic space and leverages a point-level multimodal feature contrastive learning to reduce the gap between visual and linguistic modalities. Last, the enhanced multi-modal features are fed into the action detector for precise localization. Extensive experimental results on five widely used benchmarks demonstrate the favorable performance of our proposed framework compared to several state-of-the-art methods. Moreover, our computational overhead analysis shows that the framework can run on a single 24 GB RTX 3090 GPU, indicating its practicality and scalability.
SDVPT: Semantic-Driven Visual Prompt Tuning for Open-World Object Counting
Apr 24, 2025
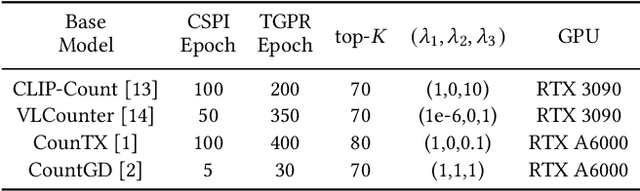

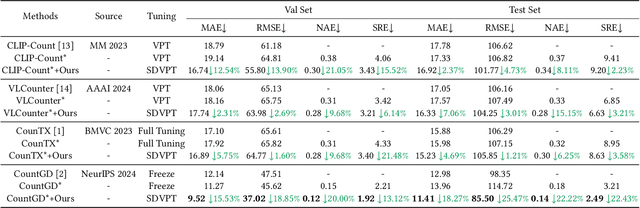
Open-world object counting leverages the robust text-image alignment of pre-trained vision-language models (VLMs) to enable counting of arbitrary categories in images specified by textual queries. However, widely adopted naive fine-tuning strategies concentrate exclusively on text-image consistency for categories contained in training, which leads to limited generalizability for unseen categories. In this work, we propose a plug-and-play Semantic-Driven Visual Prompt Tuning framework (SDVPT) that transfers knowledge from the training set to unseen categories with minimal overhead in parameters and inference time. First, we introduce a two-stage visual prompt learning strategy composed of Category-Specific Prompt Initialization (CSPI) and Topology-Guided Prompt Refinement (TGPR). The CSPI generates category-specific visual prompts, and then TGPR distills latent structural patterns from the VLM's text encoder to refine these prompts. During inference, we dynamically synthesize the visual prompts for unseen categories based on the semantic correlation between unseen and training categories, facilitating robust text-image alignment for unseen categories. Extensive experiments integrating SDVPT with all available open-world object counting models demonstrate its effectiveness and adaptability across three widely used datasets: FSC-147, CARPK, and PUCPR+.
Retrieval Enhanced Zero-Shot Video Captioning
May 11, 2024



Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
Dynamic Erasing Network Based on Multi-Scale Temporal Features for Weakly Supervised Video Anomaly Detection
Dec 04, 2023



The goal of weakly supervised video anomaly detection is to learn a detection model using only video-level labeled data. However, prior studies typically divide videos into fixed-length segments without considering the complexity or duration of anomalies. Moreover, these studies usually just detect the most abnormal segments, potentially overlooking the completeness of anomalies. To address these limitations, we propose a Dynamic Erasing Network (DE-Net) for weakly supervised video anomaly detection, which learns multi-scale temporal features. Specifically, to handle duration variations of abnormal events, we first propose a multi-scale temporal modeling module, capable of extracting features from segments of varying lengths and capturing both local and global visual information across different temporal scales. Then, we design a dynamic erasing strategy, which dynamically assesses the completeness of the detected anomalies and erases prominent abnormal segments in order to encourage the model to discover gentle abnormal segments in a video. The proposed method obtains favorable performance compared to several state-of-the-art approaches on three datasets: XD-Violence, TAD, and UCF-Crime. Code will be made available at https://github.com/ArielZc/DE-Net.
Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection
Dec 08, 2022
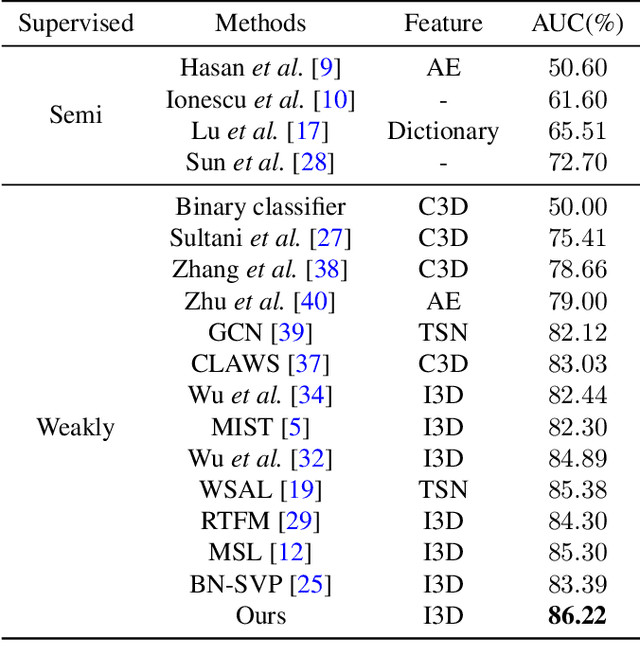
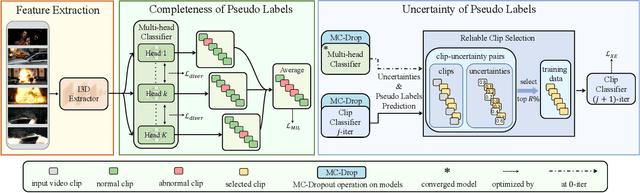
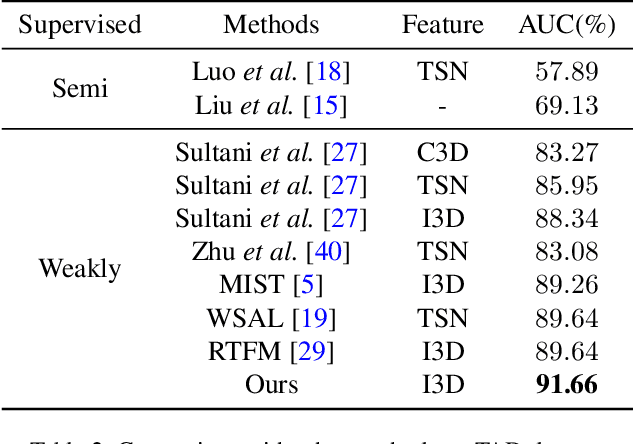
Weakly supervised video anomaly detection aims to identify abnormal events in videos using only video-level labels. Recently, two-stage self-training methods have achieved significant improvements by self-generating pseudo labels and self-refining anomaly scores with these labels. As the pseudo labels play a crucial role, we propose an enhancement framework by exploiting completeness and uncertainty properties for effective self-training. Specifically, we first design a multi-head classification module (each head serves as a classifier) with a diversity loss to maximize the distribution differences of predicted pseudo labels across heads. This encourages the generated pseudo labels to cover as many abnormal events as possible. We then devise an iterative uncertainty pseudo label refinement strategy, which improves not only the initial pseudo labels but also the updated ones obtained by the desired classifier in the second stage. Extensive experimental results demonstrate the proposed method performs favorably against state-of-the-art approaches on the UCF-Crime, TAD, and XD-Violence benchmark datasets.
Multi-Attention Network for Compressed Video Referring Object Segmentation
Jul 26, 2022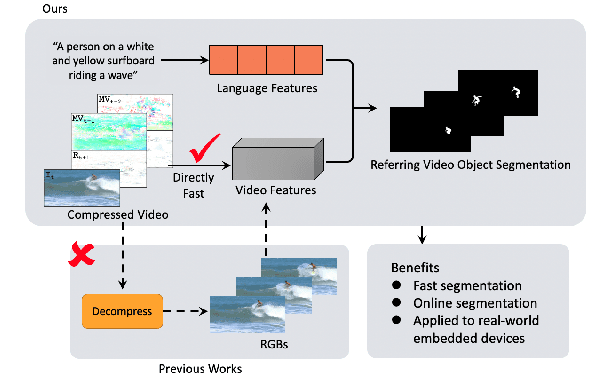
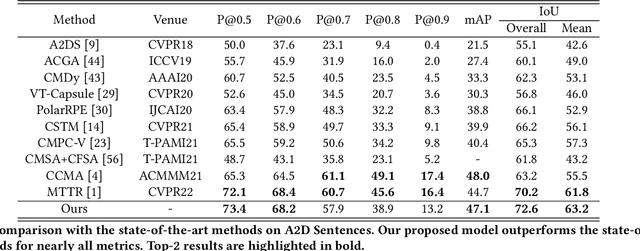
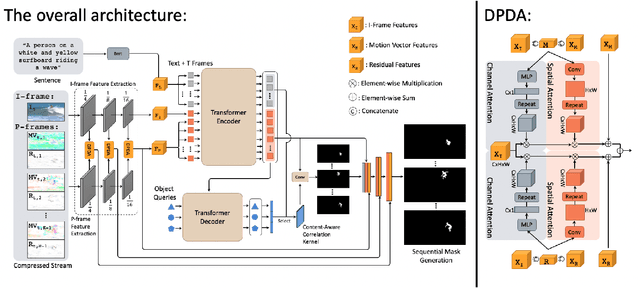
Referring video object segmentation aims to segment the object referred by a given language expression. Existing works typically require compressed video bitstream to be decoded to RGB frames before being segmented, which increases computation and storage requirements and ultimately slows the inference down. This may hamper its application in real-world computing resource limited scenarios, such as autonomous cars and drones. To alleviate this problem, in this paper, we explore the referring object segmentation task on compressed videos, namely on the original video data flow. Besides the inherent difficulty of the video referring object segmentation task itself, obtaining discriminative representation from compressed video is also rather challenging. To address this problem, we propose a multi-attention network which consists of dual-path dual-attention module and a query-based cross-modal Transformer module. Specifically, the dual-path dual-attention module is designed to extract effective representation from compressed data in three modalities, i.e., I-frame, Motion Vector and Residual. The query-based cross-modal Transformer firstly models the correlation between linguistic and visual modalities, and then the fused multi-modality features are used to guide object queries to generate a content-aware dynamic kernel and to predict final segmentation masks. Different from previous works, we propose to learn just one kernel, which thus removes the complicated post mask-matching procedure of existing methods. Extensive promising experimental results on three challenging datasets show the effectiveness of our method compared against several state-of-the-art methods which are proposed for processing RGB data. Source code is available at: https://github.com/DexiangHong/MANet.
Deep Trans-layer Unsupervised Networks for Representation Learning
Sep 27, 2015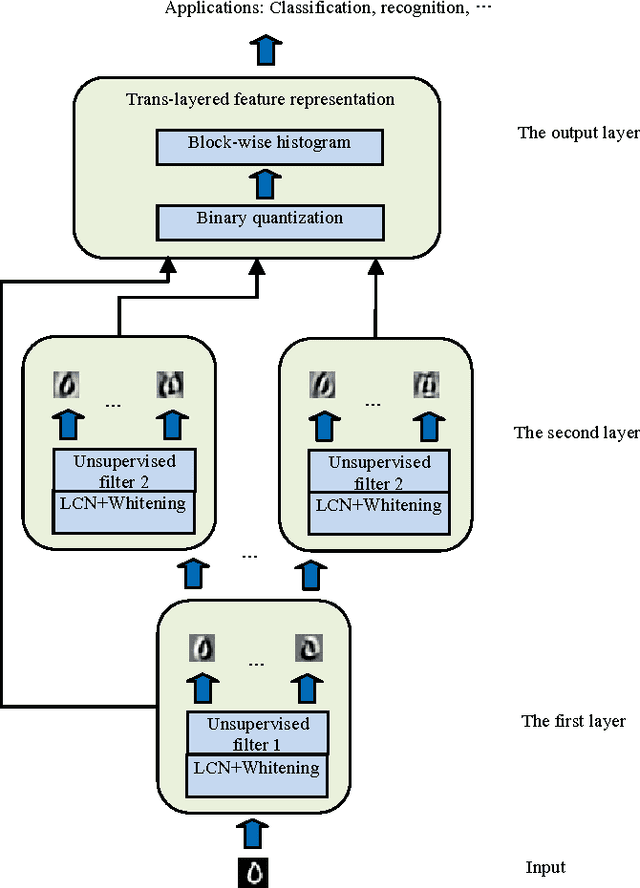

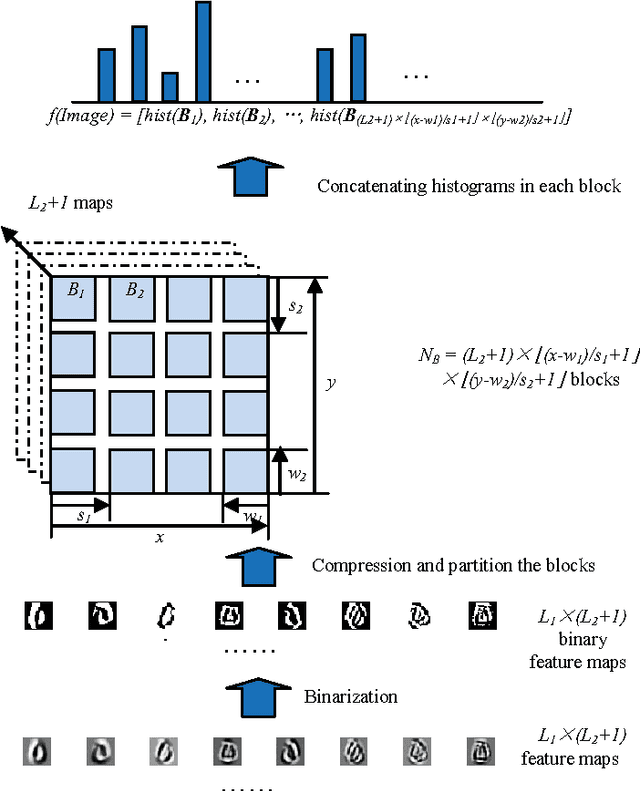

Learning features from massive unlabelled data is a vast prevalent topic for high-level tasks in many machine learning applications. The recent great improvements on benchmark data sets achieved by increasingly complex unsupervised learning methods and deep learning models with lots of parameters usually requires many tedious tricks and much expertise to tune. However, filters learned by these complex architectures are quite similar to standard hand-crafted features visually. In this paper, unsupervised learning methods, such as PCA or auto-encoder, are employed as the building block to learn filter banks at each layer. The lower layer responses are transferred to the last layer (trans-layer) to form a more complete representation retaining more information. In addition, some beneficial methods such as local contrast normalization and whitening are added to the proposed deep trans-layer networks to further boost performance. The trans-layer representations are followed by block histograms with binary encoder schema to learn translation and rotation invariant representations, which are utilized to do high-level tasks such as recognition and classification. Compared to traditional deep learning methods, the implemented feature learning method has much less parameters and is validated in several typical experiments, such as digit recognition on MNIST and MNIST variations, object recognition on Caltech 101 dataset and face verification on LFW dataset. The deep trans-layer unsupervised learning achieves 99.45% accuracy on MNIST dataset, 67.11% accuracy on 15 samples per class and 75.98% accuracy on 30 samples per class on Caltech 101 dataset, 87.10% on LFW dataset.
Constrained Extreme Learning Machines: A Study on Classification Cases
Feb 04, 2015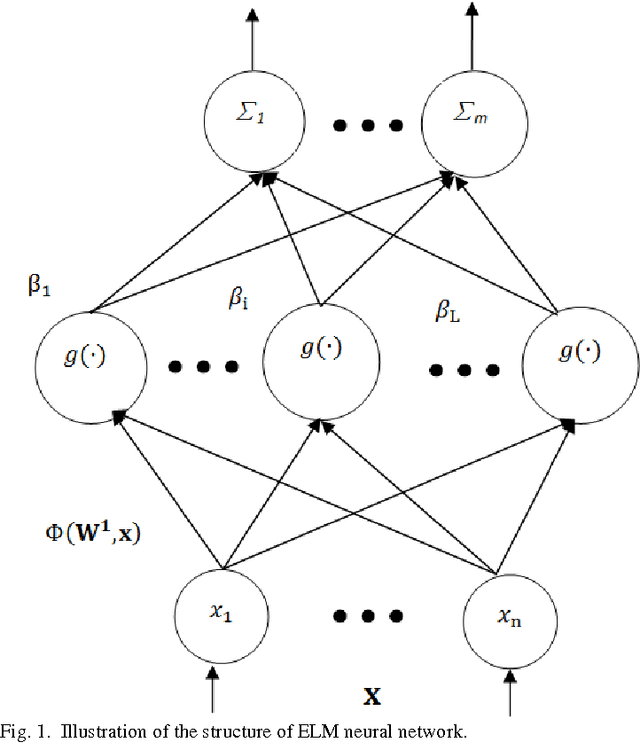
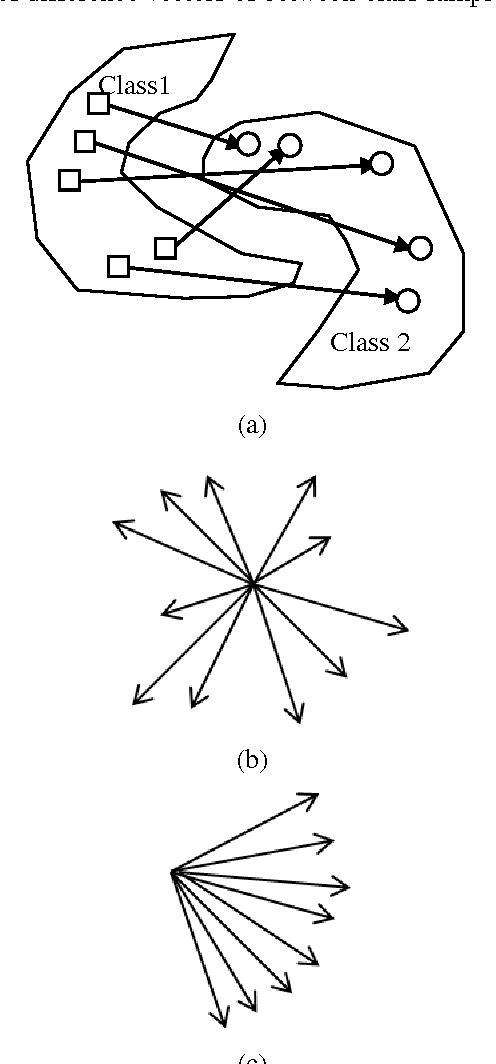
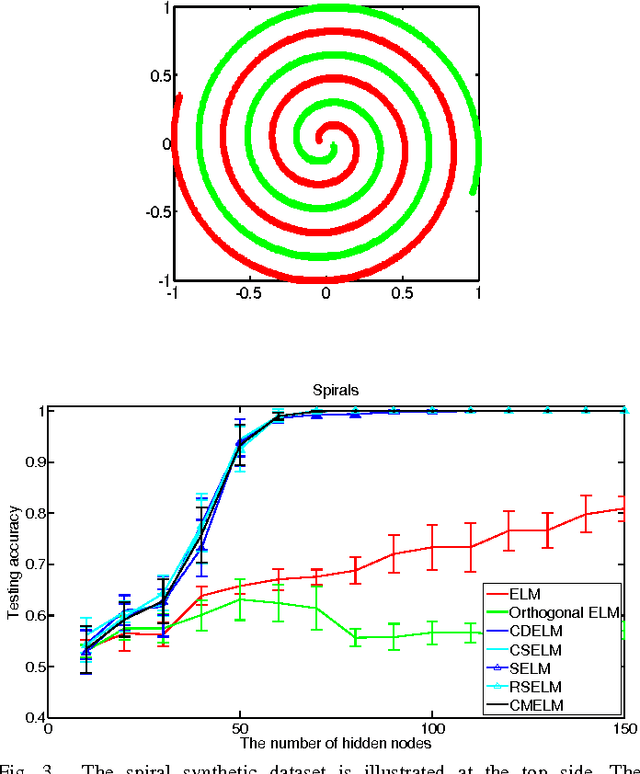
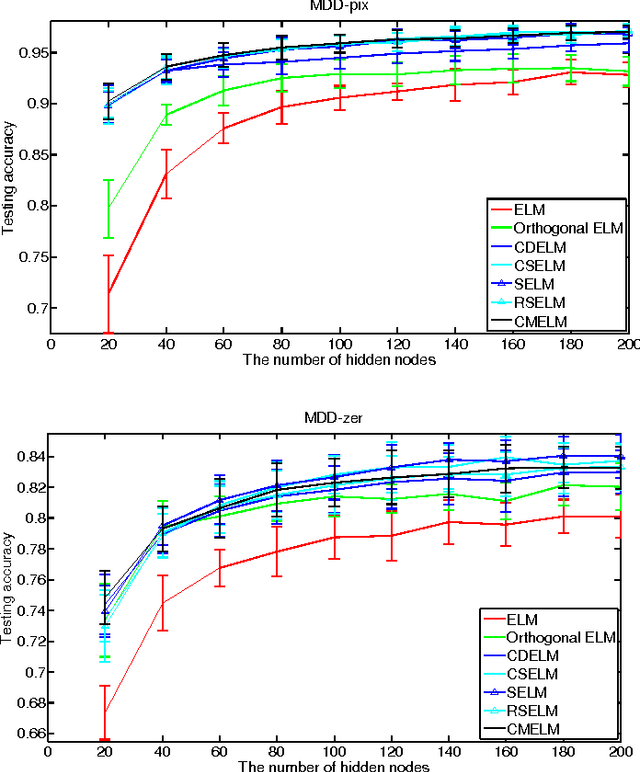
Extreme learning machine (ELM) is an extremely fast learning method and has a powerful performance for pattern recognition tasks proven by enormous researches and engineers. However, its good generalization ability is built on large numbers of hidden neurons, which is not beneficial to real time response in the test process. In this paper, we proposed new ways, named "constrained extreme learning machines" (CELMs), to randomly select hidden neurons based on sample distribution. Compared to completely random selection of hidden nodes in ELM, the CELMs randomly select hidden nodes from the constrained vector space containing some basic combinations of original sample vectors. The experimental results show that the CELMs have better generalization ability than traditional ELM, SVM and some other related methods. Additionally, the CELMs have a similar fast learning speed as ELM.