 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Erasing Network Based on Multi-Scale Temporal Features for Weakly Supervised Video Anomaly Detection
Dec 04, 2023



The goal of weakly supervised video anomaly detection is to learn a detection model using only video-level labeled data. However, prior studies typically divide videos into fixed-length segments without considering the complexity or duration of anomalies. Moreover, these studies usually just detect the most abnormal segments, potentially overlooking the completeness of anomalies. To address these limitations, we propose a Dynamic Erasing Network (DE-Net) for weakly supervised video anomaly detection, which learns multi-scale temporal features. Specifically, to handle duration variations of abnormal events, we first propose a multi-scale temporal modeling module, capable of extracting features from segments of varying lengths and capturing both local and global visual information across different temporal scales. Then, we design a dynamic erasing strategy, which dynamically assesses the completeness of the detected anomalies and erases prominent abnormal segments in order to encourage the model to discover gentle abnormal segments in a video. The proposed method obtains favorable performance compared to several state-of-the-art approaches on three datasets: XD-Violence, TAD, and UCF-Crime. Code will be made available at https://github.com/ArielZc/DE-Net.
Dual-Stream Transformer for Generic Event Boundary Captioning
Jul 07, 2022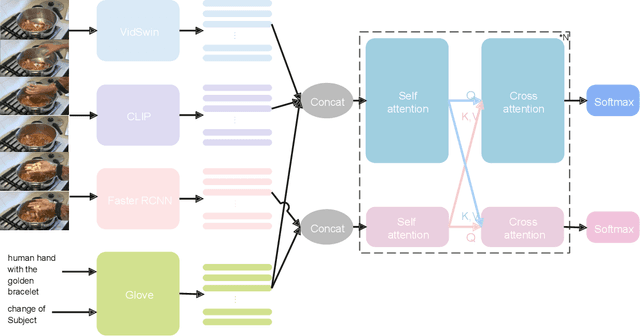


This paper describes our champion solution for the CVPR2022 Generic Event Boundary Captioning (GEBC) competition. GEBC requires the captioning model to have a comprehension of instantaneous status changes around the given video boundary, which makes it much more challenging than conventional video captioning task. In this paper, a Dual-Stream Transformer with improvements on both video content encoding and captions generation is proposed: (1) We utilize three pre-trained models to extract the video features from different granularities. Moreover, we exploit the types of boundary as hints to help the model generate captions. (2) We particularly design an model, termed as Dual-Stream Transformer, to learn discriminative representations for boundary captioning. (3) Towards generating content-relevant and human-like captions, we improve the description quality by designing a word-level ensemble strategy. The promising results on the GEBC test split demonstrate the efficacy of our proposed model.
Hierarchical Modular Network for Video Captioning
Nov 25, 2021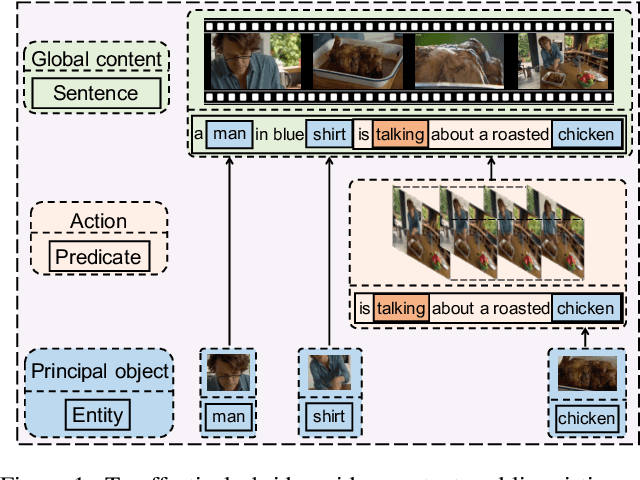
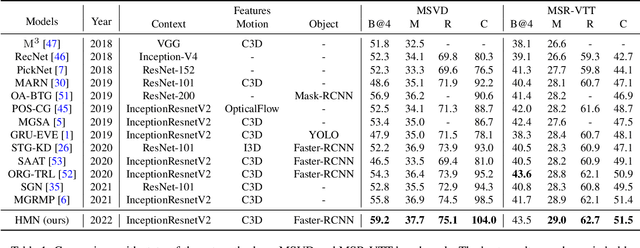
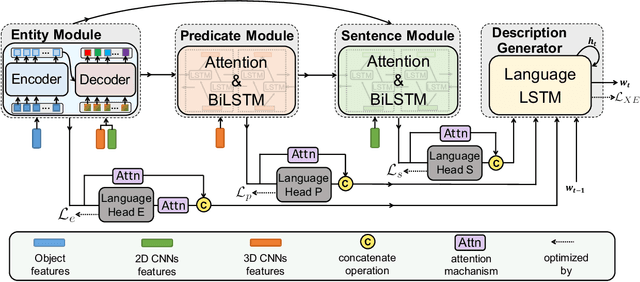

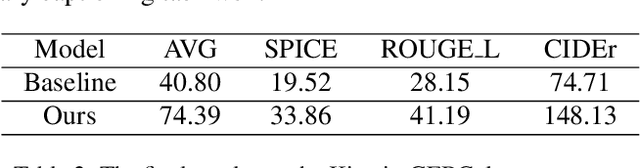
Video captioning aims to generate natural language descriptions according to the content, where representation learning plays a crucial role. Existing methods are mainly developed within the supervised learning framework via word-by-word comparison of the generated caption against the ground-truth text without fully exploiting linguistic semantics. In this work, we propose a hierarchical modular network to bridge video representations and linguistic semantics from three levels before generating captions. In particular, the hierarchy is composed of: (I) Entity level, which highlights objects that are most likely to be mentioned in captions. (II) Predicate level, which learns the actions conditioned on highlighted objects and is supervised by the predicate in captions. (III) Sentence level, which learns the global semantic representation and is supervised by the whole caption. Each level is implemented by one module. Extensive experimental results show that the proposed method performs favorably against the state-of-the-art models on the two widely-used benchmarks: MSVD 104.0% and MSR-VTT 51.5% in CIDEr score.