 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Stream Transformer for Generic Event Boundary Captioning
Paper and Code
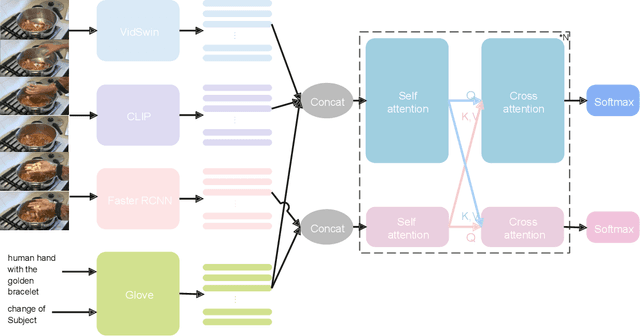


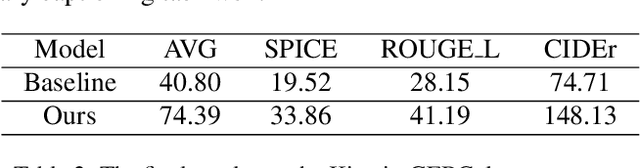
This paper describes our champion solution for the CVPR2022 Generic Event Boundary Captioning (GEBC) competition. GEBC requires the captioning model to have a comprehension of instantaneous status changes around the given video boundary, which makes it much more challenging than conventional video captioning task. In this paper, a Dual-Stream Transformer with improvements on both video content encoding and captions generation is proposed: (1) We utilize three pre-trained models to extract the video features from different granularities. Moreover, we exploit the types of boundary as hints to help the model generate captions. (2) We particularly design an model, termed as Dual-Stream Transformer, to learn discriminative representations for boundary captioning. (3) Towards generating content-relevant and human-like captions, we improve the description quality by designing a word-level ensemble strategy. The promising results on the GEBC test split demonstrate the efficacy of our proposed model.