 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Attention Network for Compressed Video Referring Object Segmentation
Paper and Code
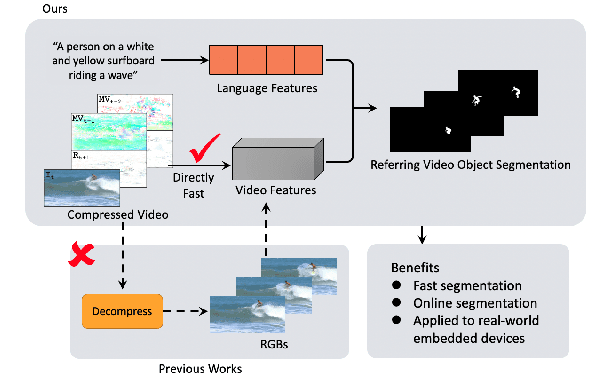
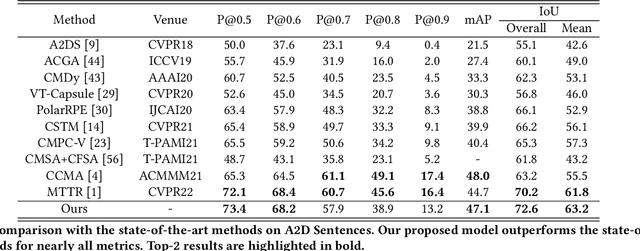
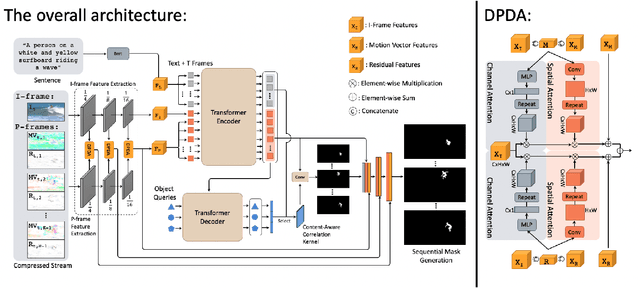
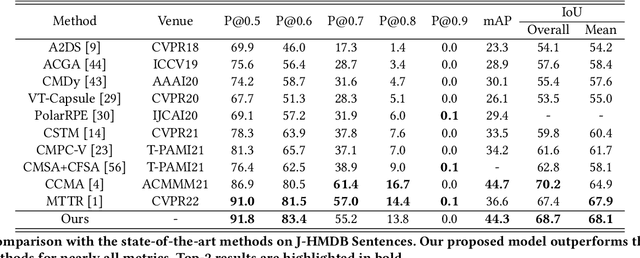
Referring video object segmentation aims to segment the object referred by a given language expression. Existing works typically require compressed video bitstream to be decoded to RGB frames before being segmented, which increases computation and storage requirements and ultimately slows the inference down. This may hamper its application in real-world computing resource limited scenarios, such as autonomous cars and drones. To alleviate this problem, in this paper, we explore the referring object segmentation task on compressed videos, namely on the original video data flow. Besides the inherent difficulty of the video referring object segmentation task itself, obtaining discriminative representation from compressed video is also rather challenging. To address this problem, we propose a multi-attention network which consists of dual-path dual-attention module and a query-based cross-modal Transformer module. Specifically, the dual-path dual-attention module is designed to extract effective representation from compressed data in three modalities, i.e., I-frame, Motion Vector and Residual. The query-based cross-modal Transformer firstly models the correlation between linguistic and visual modalities, and then the fused multi-modality features are used to guide object queries to generate a content-aware dynamic kernel and to predict final segmentation masks. Different from previous works, we propose to learn just one kernel, which thus removes the complicated post mask-matching procedure of existing methods. Extensive promising experimental results on three challenging datasets show the effectiveness of our method compared against several state-of-the-art methods which are proposed for processing RGB data. Source code is available at: https://github.com/DexiangHong/MANet.