 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Trans-layer Unsupervised Networks for Representation Learning
Sep 27, 2015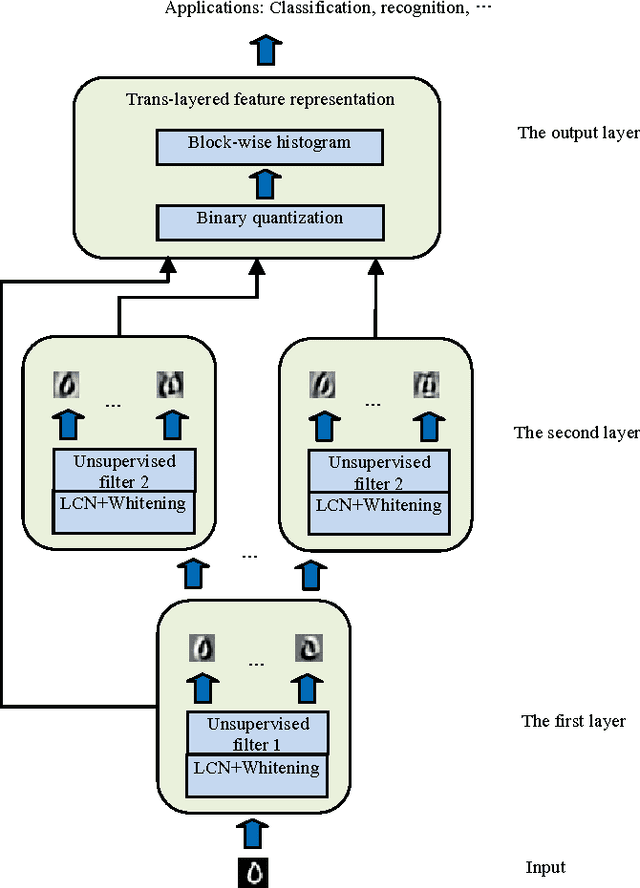

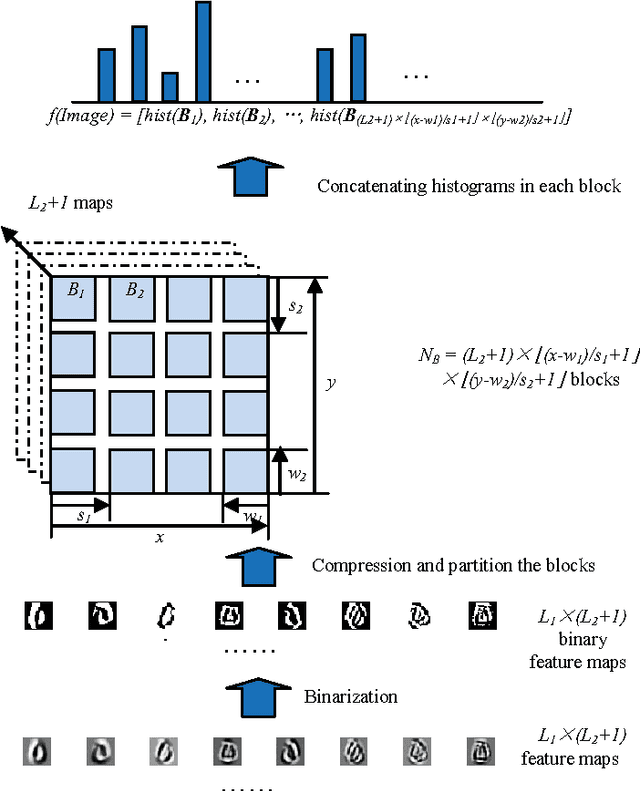

Learning features from massive unlabelled data is a vast prevalent topic for high-level tasks in many machine learning applications. The recent great improvements on benchmark data sets achieved by increasingly complex unsupervised learning methods and deep learning models with lots of parameters usually requires many tedious tricks and much expertise to tune. However, filters learned by these complex architectures are quite similar to standard hand-crafted features visually. In this paper, unsupervised learning methods, such as PCA or auto-encoder, are employed as the building block to learn filter banks at each layer. The lower layer responses are transferred to the last layer (trans-layer) to form a more complete representation retaining more information. In addition, some beneficial methods such as local contrast normalization and whitening are added to the proposed deep trans-layer networks to further boost performance. The trans-layer representations are followed by block histograms with binary encoder schema to learn translation and rotation invariant representations, which are utilized to do high-level tasks such as recognition and classification. Compared to traditional deep learning methods, the implemented feature learning method has much less parameters and is validated in several typical experiments, such as digit recognition on MNIST and MNIST variations, object recognition on Caltech 101 dataset and face verification on LFW dataset. The deep trans-layer unsupervised learning achieves 99.45% accuracy on MNIST dataset, 67.11% accuracy on 15 samples per class and 75.98% accuracy on 30 samples per class on Caltech 101 dataset, 87.10% on LFW dataset.
Constrained Extreme Learning Machines: A Study on Classification Cases
Feb 04, 2015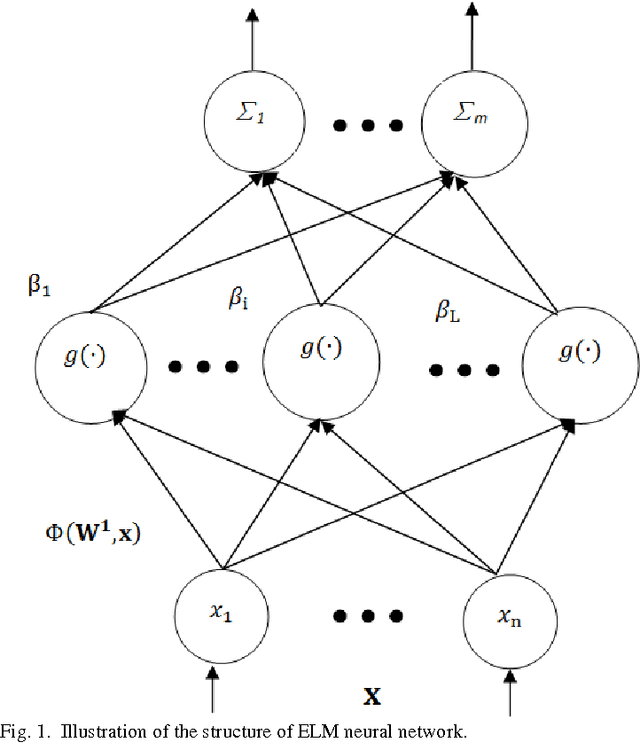
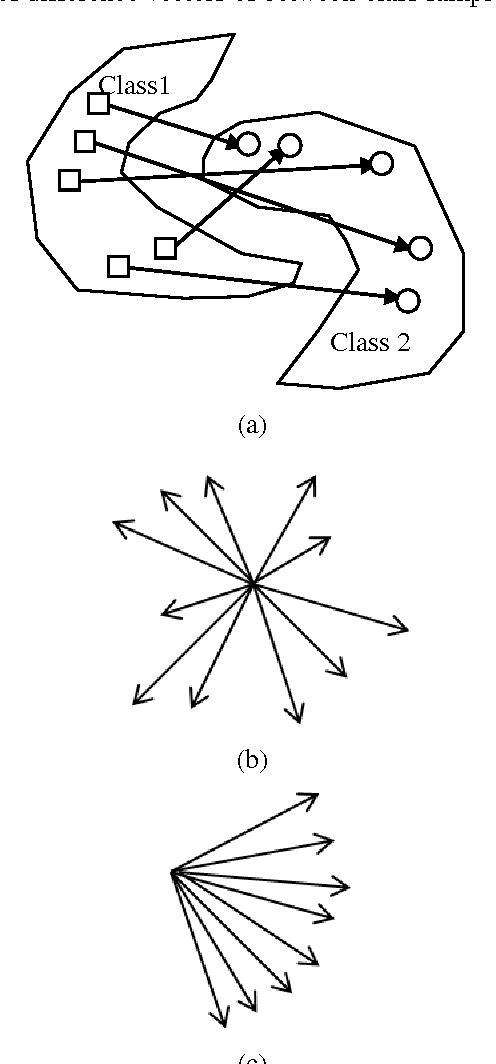
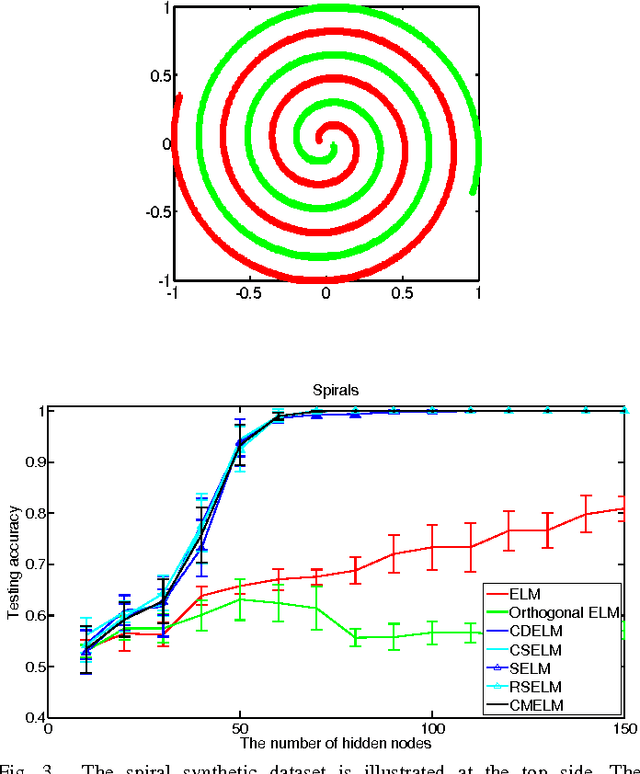
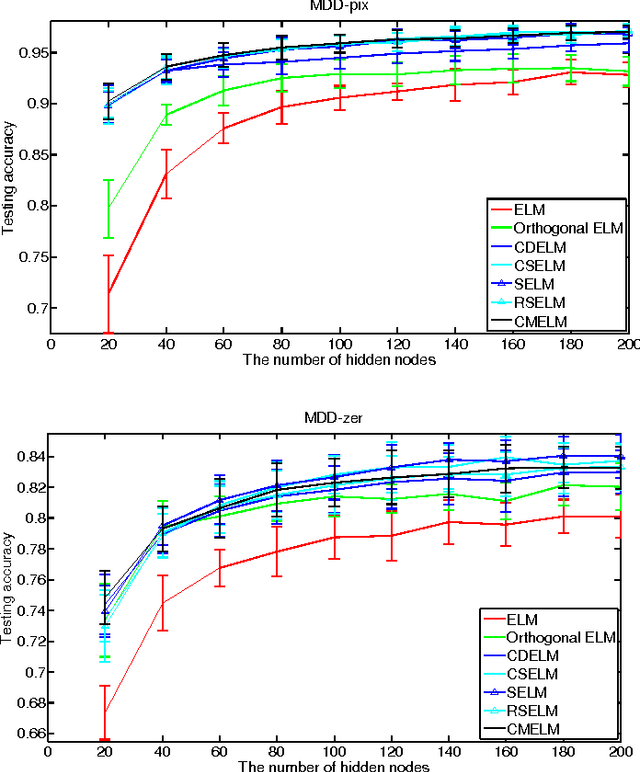
Extreme learning machine (ELM) is an extremely fast learning method and has a powerful performance for pattern recognition tasks proven by enormous researches and engineers. However, its good generalization ability is built on large numbers of hidden neurons, which is not beneficial to real time response in the test process. In this paper, we proposed new ways, named "constrained extreme learning machines" (CELMs), to randomly select hidden neurons based on sample distribution. Compared to completely random selection of hidden nodes in ELM, the CELMs randomly select hidden nodes from the constrained vector space containing some basic combinations of original sample vectors. The experimental results show that the CELMs have better generalization ability than traditional ELM, SVM and some other related methods. Additionally, the CELMs have a similar fast learning speed as ELM.