 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersoDPO: Scalable Preference Optimization for Instruction-Adherent, Persona-Grounded Dialogue via Multi-LLM Evaluation
Feb 04, 2026Personalization and contextual coherence are two essential components in building effective persona-grounded dialogue systems. These aspects play a crucial role in enhancing user engagement and ensuring responses are more relevant and consistent with user identity. However, recent studies indicate that open-source large language models (LLMs) continue to struggle to generate responses that are both contextually grounded and aligned with persona cues, despite exhibiting strong general conversational abilities like fluency and naturalness. We present PersoDPO, a scalable preference optimisation framework that uses supervision signals from automatic evaluations of responses generated by both closed-source and open-source LLMs to fine-tune dialogue models. The framework integrates evaluation metrics targeting coherence and personalization, along with a length-format compliance feature to promote instruction adherence. These signals are combined to automatically construct high-quality preference pairs without manual annotation, enabling a scalable and reproducible training pipeline. Experiments on the FoCus dataset show that an open-source language model fine-tuned with the PersoDPO framework consistently outperforms strong open-source baselines and a standard Direct Preference Optimization (DPO) variant across multiple evaluation dimensions.
PersoPilot: An Adaptive AI-Copilot for Transparent Contextualized Persona Classification and Personalized Response Generation
Feb 04, 2026Understanding and classifying user personas is critical for delivering effective personalization. While persona information offers valuable insights, its full potential is realized only when contextualized, linking user characteristics with situational context to enable more precise and meaningful service provision. Existing systems often treat persona and context as separate inputs, limiting their ability to generate nuanced, adaptive interactions. To address this gap, we present PersoPilot, an agentic AI-Copilot that integrates persona understanding with contextual analysis to support both end users and analysts. End users interact through a transparent, explainable chat interface, where they can express preferences in natural language, request recommendations, and receive information tailored to their immediate task. On the analyst side, PersoPilot delivers a transparent, reasoning-powered labeling assistant, integrated with an active learning-driven classification process that adapts over time with new labeled data. This feedback loop enables targeted service recommendations and adaptive personalization, bridging the gap between raw persona data and actionable, context-aware insights. As an adaptable framework, PersoPilot is applicable to a broad range of service personalization scenarios.
Modeling and Optimizing User Preferences in AI Copilots: A Comprehensive Survey and Taxonomy
May 28, 2025AI copilots, context-aware, AI-powered systems designed to assist users in tasks such as software development and content creation, are becoming integral to modern workflows. As these systems grow in capability and adoption, personalization has emerged as a cornerstone for ensuring usability, trust, and productivity. Central to this personalization is preference optimization: the ability of AI copilots to detect, interpret, and align with individual user preferences. While personalization techniques are well-established in domains like recommender systems and dialogue agents, their adaptation to interactive, real-time systems like AI copilots remains fragmented and underexplored. This survey addresses this gap by synthesizing research on how user preferences are captured, modeled, and refined within the design of AI copilots. We introduce a unified definition of AI copilots and propose a phase-based taxonomy of preference optimization strategies, structured around pre-interaction, mid-interaction, and post-interaction stages. We analyze techniques for acquiring preference signals, modeling user intent, and integrating feedback loops, highlighting both established approaches and recent innovations. By bridging insights from AI personalization, human-AI collaboration, and large language model adaptation, this survey provides a structured foundation for designing adaptive, preference-aware AI copilots. It offers a holistic view of the available preference resources, how they can be leveraged, and which technical approaches are most suited to each stage of system design.
PersoBench: Benchmarking Personalized Response Generation in Large Language Models
Oct 04, 2024


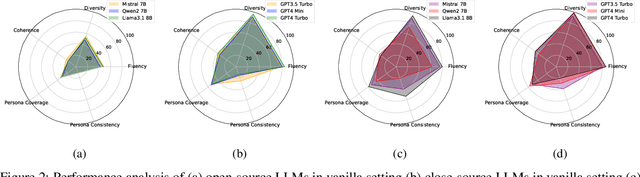
While large language models (LLMs) have exhibited impressive conversational capabilities, their proficiency in delivering personalized responses remains unclear. Although recent benchmarks automatically evaluate persona consistency in role-playing contexts using LLM-based judgment, the evaluation of personalization in response generation remains underexplored. To address this gap, we present a new benchmark, PersoBench, to evaluate the personalization ability of LLMs in persona-aware dialogue generation within a zero-shot setting. We assess the performance of three open-source and three closed-source LLMs using well-known datasets and a range of metrics. Our analysis, conducted on three well-known persona-aware datasets, evaluates multiple dimensions of response quality, including fluency, diversity, coherence, and personalization, across both standard and chain-of-thought prompting methods. Our findings reveal that while LLMs excel at generating fluent and diverse responses, they are far from satisfactory in delivering personalized and coherent responses considering both the conversation context and the provided personas. Our benchmark implementation is available at https://github.com/salehafzoon/PersoBench.