 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLIP: Cross-modal Attention Masked Modelling for Medical Language-Image Pre-Training
Paper and Code
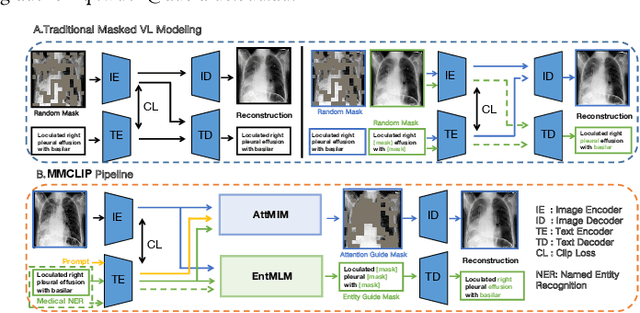
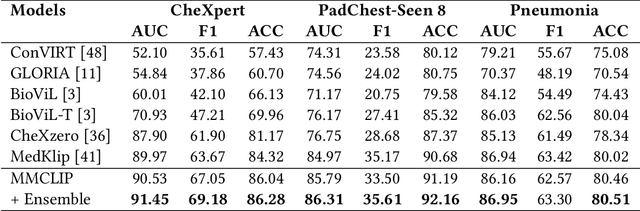
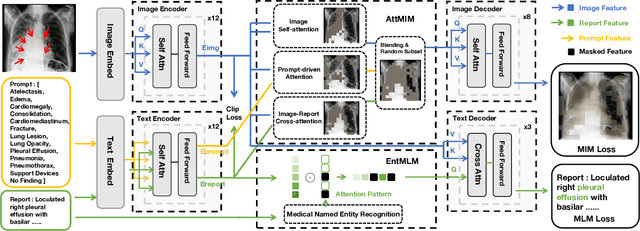

Vision-and-language pretraining (VLP) in the medical field utilizes contrastive learning on image-text pairs to achieve effective transfer across tasks. Yet, current VLP approaches with the masked modelling strategy face two challenges when applied to the medical domain. First, current models struggle to accurately reconstruct key pathological features due to the scarcity of medical data. Second, most methods only adopt either paired image-text or image-only data, failing to exploit the combination of both paired and unpaired data. To this end, this paper proposes a XLIP (Masked modelling for medical Language-Image Pre-training) framework to enhance pathological learning and feature learning via unpaired data. First, we introduce the attention-masked image modelling (AttMIM) and entity-driven masked language modelling module (EntMLM), which learns to reconstruct pathological visual and textual tokens via multi-modal feature interaction, thus improving medical-enhanced features. The AttMIM module masks a portion of the image features that are highly responsive to textual features. This allows XLIP to improve the reconstruction of highly similar image data in medicine efficiency. Second, our XLIP capitalizes unpaired data to enhance multimodal learning by introducing disease-kind prompts. The experimental results show that XLIP achieves SOTA for zero-shot and fine-tuning classification performance on five datasets. Our code will be available at https://github.com/White65534/XLIP