 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBimodal Camera Pose Prediction for Endoscopy
Paper and Code
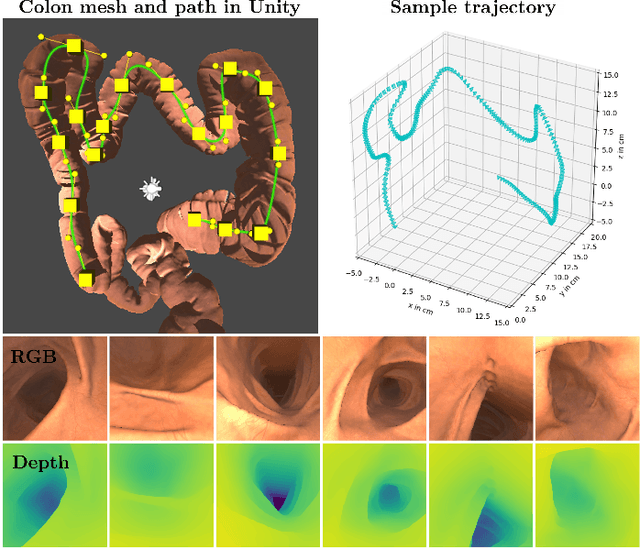
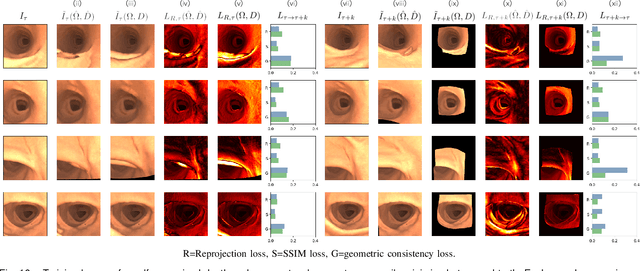
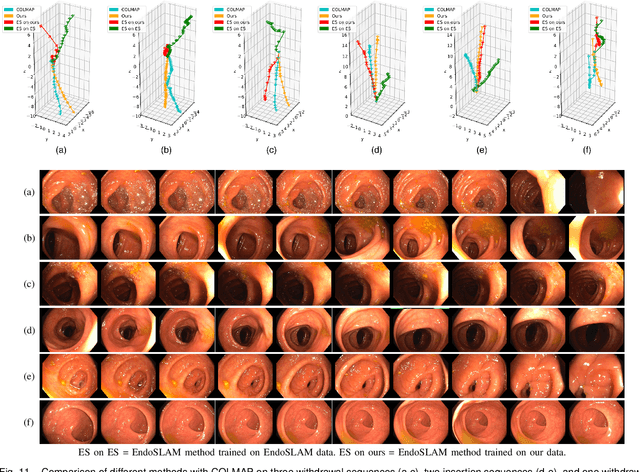
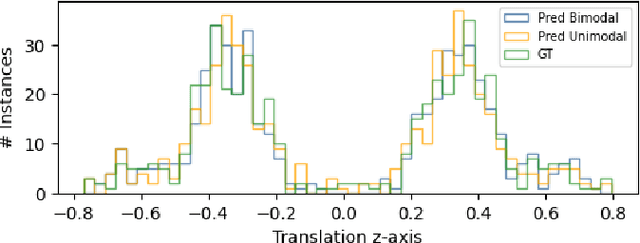
Deducing the 3D structure of endoscopic scenes from images remains extremely challenging. In addition to deformation and view-dependent lighting, tubular structures like the colon present problems stemming from the self-occluding, repetitive anatomical structures. In this paper, we propose SimCol, a synthetic dataset for camera pose estimation in colonoscopy and a novel method that explicitly learns a bimodal distribution to predict the endoscope pose. Our dataset replicates real colonoscope motion and highlights drawbacks of existing methods. We publish 18k RGB images from simulated colonoscopy with corresponding depth and camera poses and make our data generation environment in Unity publicly available. We evaluate different camera pose prediction methods and demonstrate that, when trained on our data, they generalize to real colonoscopy sequences and our bimodal approach outperforms prior unimodal work.