 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Effective is Incongruity? Implications for Code-mix Sarcasm Detection
Paper and Code
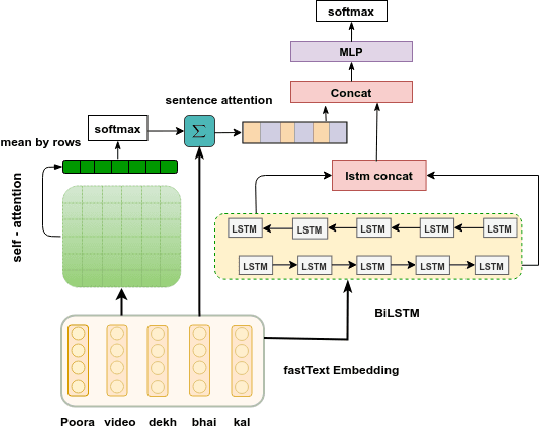
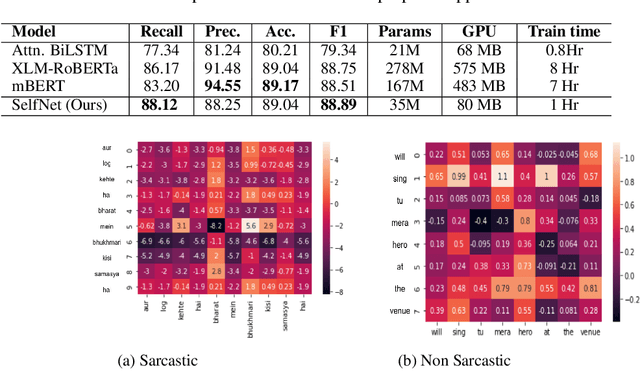
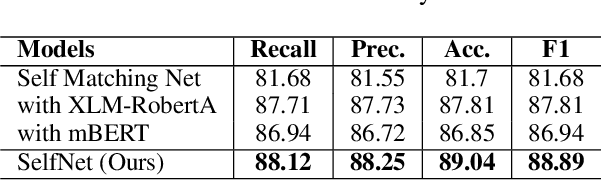
The presence of sarcasm in conversational systems and social media like chatbots, Facebook, Twitter, etc. poses several challenges for downstream NLP tasks. This is attributed to the fact that the intended meaning of a sarcastic text is contrary to what is expressed. Further, the use of code-mix language to express sarcasm is increasing day by day. Current NLP techniques for code-mix data have limited success due to the use of different lexicon, syntax, and scarcity of labeled corpora. To solve the joint problem of code-mixing and sarcasm detection, we propose the idea of capturing incongruity through sub-word level embeddings learned via fastText. Empirical results shows that our proposed model achieves F1-score on code-mix Hinglish dataset comparable to pretrained multilingual models while training 10x faster and using a lower memory footprint