 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Adaptation for ASR in low-resource Indian Languages
Jul 16, 2023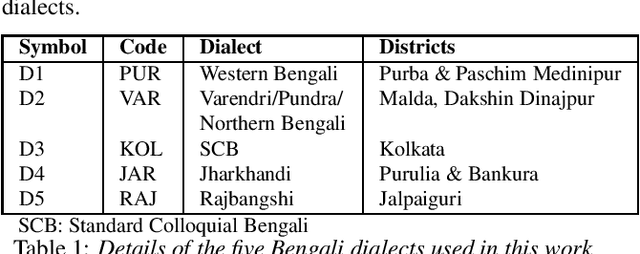

Automatic speech recognition (ASR) performance has improved drastically in recent years, mainly enabled by self-supervised learning (SSL) based acoustic models such as wav2vec2 and large-scale multi-lingual training like Whisper. A huge challenge still exists for low-resource languages where the availability of both audio and text is limited. This is further complicated by the presence of multiple dialects like in Indian languages. However, many Indian languages can be grouped into the same families and share the same script and grammatical structure. This is where a lot of adaptation and fine-tuning techniques can be applied to overcome the low-resource nature of the data by utilising well-resourced similar languages. In such scenarios, it is important to understand the extent to which each modality, like acoustics and text, is important in building a reliable ASR. It could be the case that an abundance of acoustic data in a language reduces the need for large text-only corpora. Or, due to the availability of various pretrained acoustic models, the vice-versa could also be true. In this proposed special session, we encourage the community to explore these ideas with the data in two low-resource Indian languages of Bengali and Bhojpuri. These approaches are not limited to Indian languages, the solutions are potentially applicable to various languages spoken around the world.
UGV-UAV Object Geolocation in Unstructured Environments
Jan 14, 2022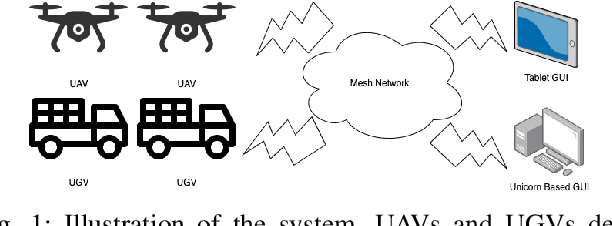


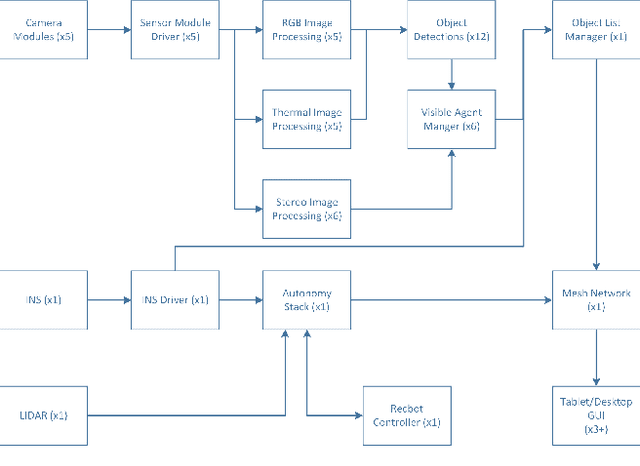
A robotic system of multiple unmanned ground vehicles (UGVs) and unmanned aerial vehicles (UAVs) has the potential for advancing autonomous object geolocation performance. Much research has focused on algorithmic improvements on individual components, such as navigation, motion planning, and perception. In this paper, we present a UGV-UAV object detection and geolocation system, which performs perception, navigation, and planning autonomously in real scale in unstructured environment. We designed novel sensor pods equipped with multispectral (visible, near-infrared, thermal), high resolution (181.6 Mega Pixels), stereo (near-infrared pair), wide field of view (192 degree HFOV) array. We developed a novel on-board software-hardware architecture to process the high volume sensor data in real-time, and we built a custom AI subsystem composed of detection, tracking, navigation, and planning for autonomous objects geolocation in real-time. This research is the first real scale demonstration of such high speed data processing capability. Our novel modular sensor pod can boost relevant computer vision and machine learning research. Our novel hardware-software architecture is a solid foundation for system-level and component-level research. Our system is validated through data-driven offline tests as well as a series of field tests in unstructured environments. We present quantitative results as well as discussions on key robotic system level challenges which manifest when we build and test the system. This system is the first step toward a UGV-UAV cooperative reconnaissance system in the future.
An Intelligent Recommendation-cum-Reminder System
Aug 09, 2021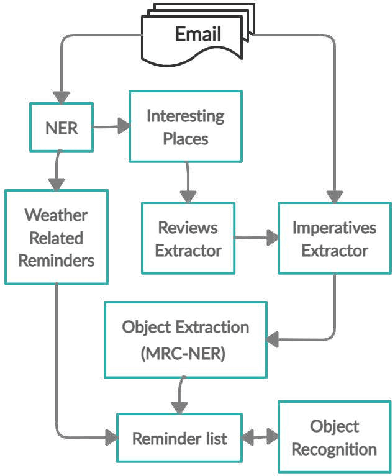

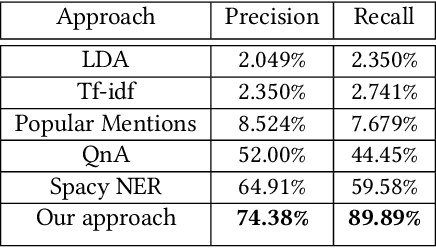
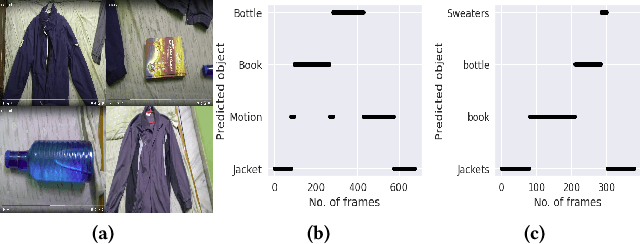
Intelligent recommendation and reminder systems are the need of the fast-pacing life. Current intelligent systems such as Siri, Google Assistant, Microsoft Cortona, etc., have limited capability. For example, if you want to wake up at 6 am because you have an upcoming trip, you have to set the alarm manually. Besides, these systems do not recommend or remind what else to carry, such as carrying an umbrella during a likely rain. The present work proposes a system that takes an email as input and returns a recommendation-cumreminder list. As a first step, we parse the emails, recognize the entities using named entity recognition (NER). In the second step, information retrieval over the web is done to identify nearby places, climatic conditions, etc. Imperative sentences from the reviews of all places are extracted and passed to the object extraction module. The main challenge lies in extracting the objects (items) of interest from the review. To solve it, a modified Machine Reading Comprehension-NER (MRC-NER) model is trained to tag objects of interest by formulating annotation rules as a query. The objects so found are recommended to the user one day in advance. The final reminder list of objects is pruned by our proposed model for tracking objects kept during the "packing activity." Eventually, when the user leaves for the event/trip, an alert is sent containing the reminding list items. Our approach achieves superior performance compared to several baselines by as much as 30% on recall and 10% on precision.
PWOC-3D: Deep Occlusion-Aware End-to-End Scene Flow Estimation
Apr 12, 2019

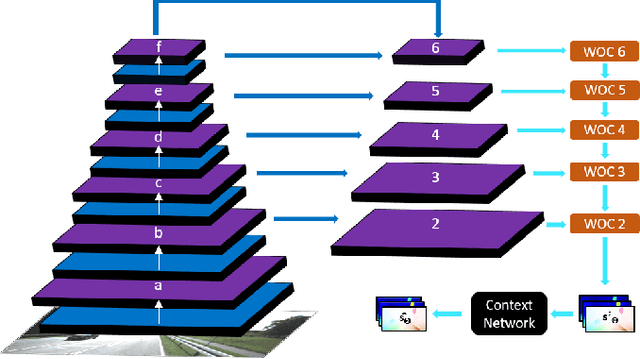
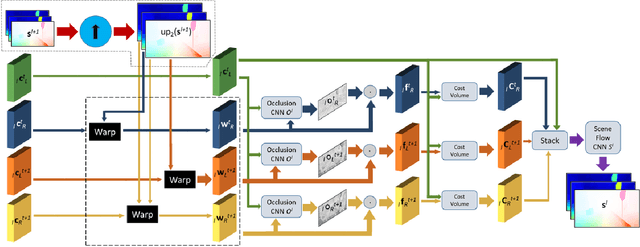
In the last few years, convolutional neural networks (CNNs) have demonstrated increasing success at learning many computer vision tasks including dense estimation problems such as optical flow and stereo matching. However, the joint prediction of these tasks, called scene flow, has traditionally been tackled using slow classical methods based on primitive assumptions which fail to generalize. The work presented in this paper overcomes these drawbacks efficiently (in terms of speed and accuracy) by proposing PWOC-3D, a compact CNN architecture to predict scene flow from stereo image sequences in an end-to-end supervised setting. Further, large motion and occlusions are well-known problems in scene flow estimation. PWOC-3D employs specialized design decisions to explicitly model these challenges. In this regard, we propose a novel self-supervised strategy to predict occlusions from images (learned without any labeled occlusion data). Leveraging several such constructs, our network achieves competitive results on the KITTI benchmark and the challenging FlyingThings3D dataset. Especially on KITTI, PWOC-3D achieves the second place among end-to-end deep learning methods with 48 times fewer parameters than the top-performing method.