 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePWOC-3D: Deep Occlusion-Aware End-to-End Scene Flow Estimation
Paper and Code


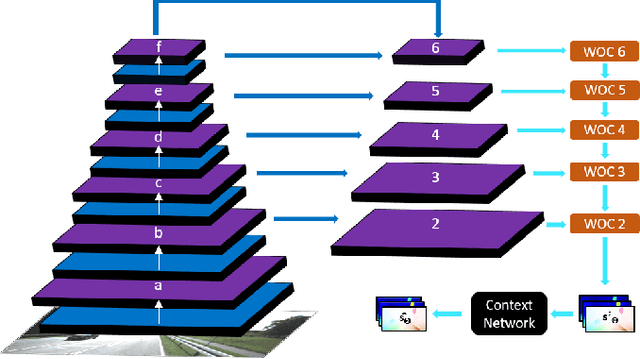
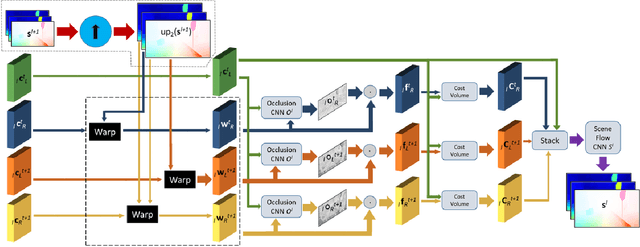
In the last few years, convolutional neural networks (CNNs) have demonstrated increasing success at learning many computer vision tasks including dense estimation problems such as optical flow and stereo matching. However, the joint prediction of these tasks, called scene flow, has traditionally been tackled using slow classical methods based on primitive assumptions which fail to generalize. The work presented in this paper overcomes these drawbacks efficiently (in terms of speed and accuracy) by proposing PWOC-3D, a compact CNN architecture to predict scene flow from stereo image sequences in an end-to-end supervised setting. Further, large motion and occlusions are well-known problems in scene flow estimation. PWOC-3D employs specialized design decisions to explicitly model these challenges. In this regard, we propose a novel self-supervised strategy to predict occlusions from images (learned without any labeled occlusion data). Leveraging several such constructs, our network achieves competitive results on the KITTI benchmark and the challenging FlyingThings3D dataset. Especially on KITTI, PWOC-3D achieves the second place among end-to-end deep learning methods with 48 times fewer parameters than the top-performing method.