 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Sparsity for Long Context Inference: Million Token Contexts on Commodity GPUs
Feb 10, 2025



There is growing demand for performing inference with hundreds of thousands of input tokens on trained transformer models. Inference at this extreme scale demands significant computational resources, hindering the application of transformers at long contexts on commodity (i.e not data center scale) hardware. To address the inference time costs associated with running self-attention based transformer language models on long contexts and enable their adoption on widely available hardware, we propose a tunable mechanism that reduces the cost of the forward pass by attending to only the most relevant tokens at every generation step using a top-k selection mechanism. We showcase the efficiency gains afforded by our method by performing inference on context windows up to 1M tokens using approximately 16GB of GPU RAM. Our experiments reveal that models are capable of handling the sparsity induced by the reduced number of keys and values. By attending to less than 2% of input tokens, we achieve over 95% of model performance on common long context benchmarks (LM-Eval, AlpacaEval, and RULER).
FAST: Factorizable Attention for Speeding up Transformers
Feb 12, 2024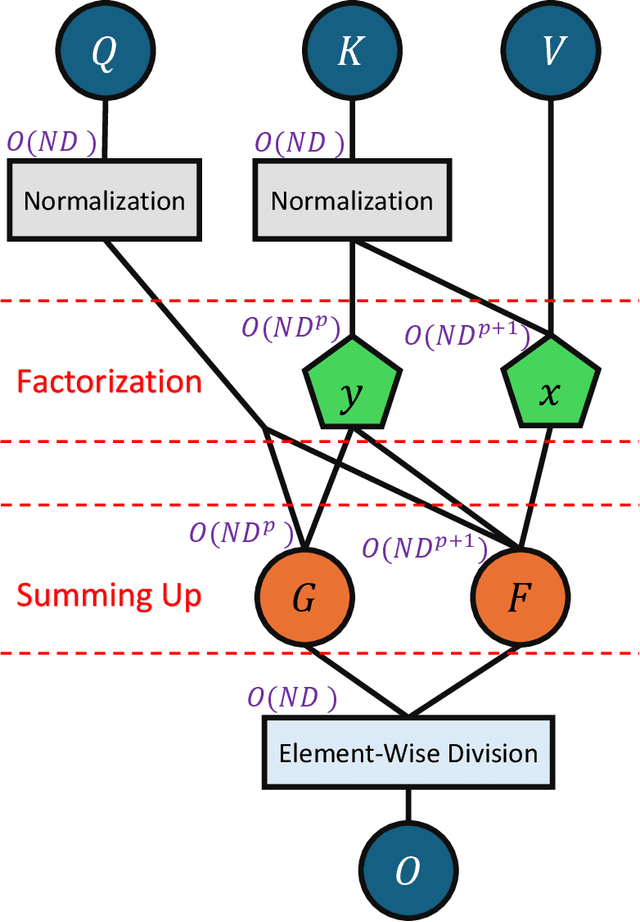
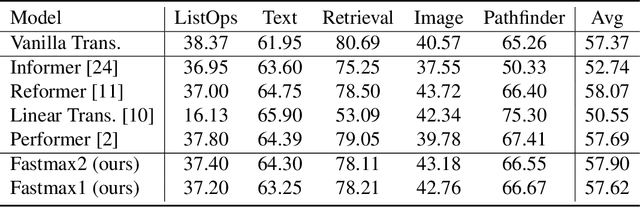

Motivated by the factorization inherent in the original fast multipole method and the improved fast Gauss transform we introduce a factorable form of attention that operates efficiently in high dimensions. This approach reduces the computational and memory complexity of the attention mechanism in transformers from $O(N^2)$ to $O(N)$. In comparison to previous attempts, our work presents a linearly scaled attention mechanism that maintains the full representation of the attention matrix without compromising on sparsification and incorporates the all-to-all relationship between tokens. We explore the properties of our new attention metric and conduct tests in various standard settings. Results indicate that our attention mechanism has a robust performance and holds significant promise for diverse applications where self-attention is used.
Machine Learning at Microsoft with ML .NET
May 15, 2019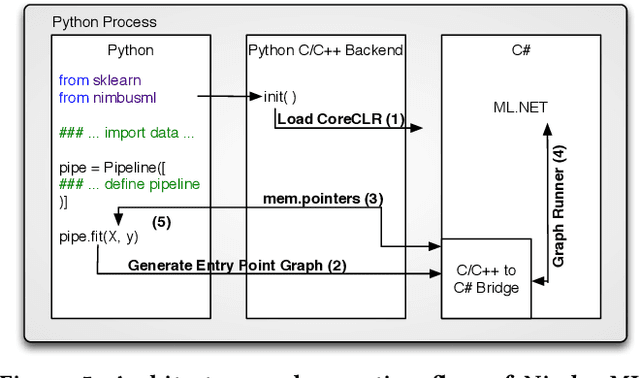
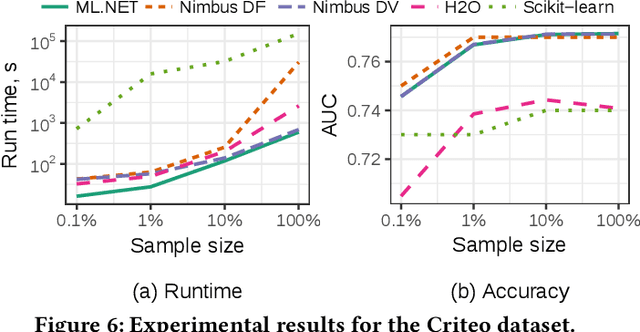
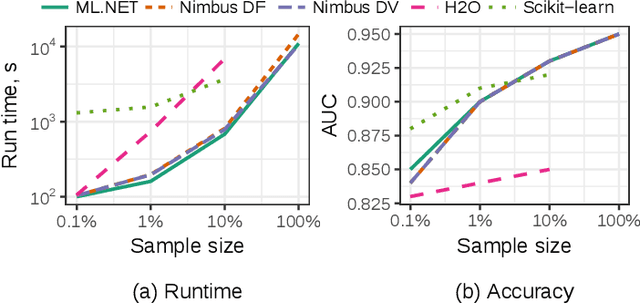
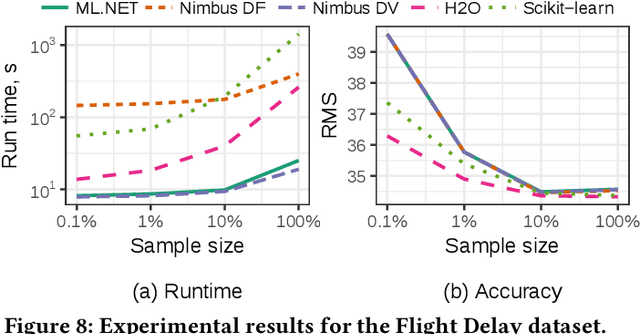
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.