 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColombian Waitresses y Jueces canadienses: Gender and Country Biases in Occupation Recommendations from LLMs
May 05, 2025One of the goals of fairness research in NLP is to measure and mitigate stereotypical biases that are propagated by NLP systems. However, such work tends to focus on single axes of bias (most often gender) and the English language. Addressing these limitations, we contribute the first study of multilingual intersecting country and gender biases, with a focus on occupation recommendations generated by large language models. We construct a benchmark of prompts in English, Spanish and German, where we systematically vary country and gender, using 25 countries and four pronoun sets. Then, we evaluate a suite of 5 Llama-based models on this benchmark, finding that LLMs encode significant gender and country biases. Notably, we find that even when models show parity for gender or country individually, intersectional occupational biases based on both country and gender persist. We also show that the prompting language significantly affects bias, and instruction-tuned models consistently demonstrate the lowest and most stable levels of bias. Our findings highlight the need for fairness researchers to use intersectional and multilingual lenses in their work.
BasqueParl: A Bilingual Corpus of Basque Parliamentary Transcriptions
May 03, 2022
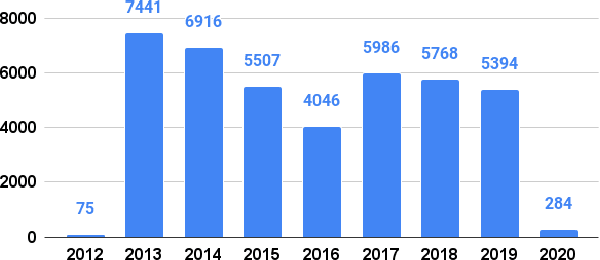

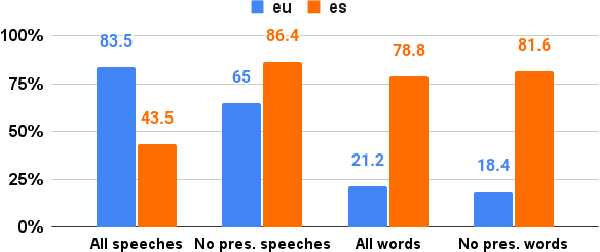
Parliamentary transcripts provide a valuable resource to understand the reality and know about the most important facts that occur over time in our societies. Furthermore, the political debates captured in these transcripts facilitate research on political discourse from a computational social science perspective. In this paper we release the first version of a newly compiled corpus from Basque parliamentary transcripts. The corpus is characterized by heavy Basque-Spanish code-switching, and represents an interesting resource to study political discourse in contrasting languages such as Basque and Spanish. We enrich the corpus with metadata related to relevant attributes of the speakers and speeches (language, gender, party...) and process the text to obtain named entities and lemmas. The obtained metadata is then used to perform a detailed corpus analysis which provides interesting insights about the language use of the Basque political representatives across time, parties and gender.
Does Corpus Quality Really Matter for Low-Resource Languages?
Mar 15, 2022
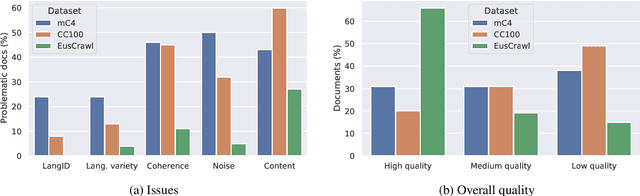
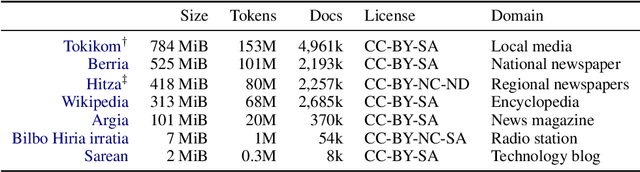

The vast majority of non-English corpora are derived from automatically filtered versions of CommonCrawl. While prior work has identified major issues on the quality of these datasets (Kreutzer et al., 2021), it is not clear how this impacts downstream performance. Taking Basque as a case study, we explore tailored crawling (manually identifying and scraping websites with high-quality content) as an alternative to filtering CommonCrawl. Our new corpus, called EusCrawl, is similar in size to the Basque portion of popular multilingual corpora like CC100 and mC4, yet it has a much higher quality according to native annotators. For instance, 66% of documents are rated as high-quality for EusCrawl, in contrast with <33% for both mC4 and CC100. Nevertheless, we obtain similar results on downstream tasks regardless of the corpus used for pre-training. Our work suggests that NLU performance in low-resource languages is primarily constrained by the quantity rather than the quality of the data, prompting for methods to exploit more diverse data sources.