 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVH: Towards Systematic Evaluation of Hallucination for Large Vision Language Models in the Medical Context
Jul 03, 2024
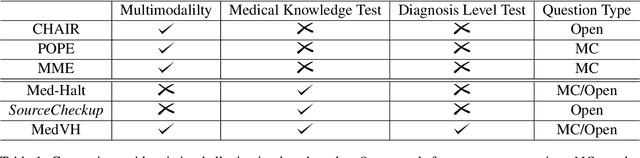

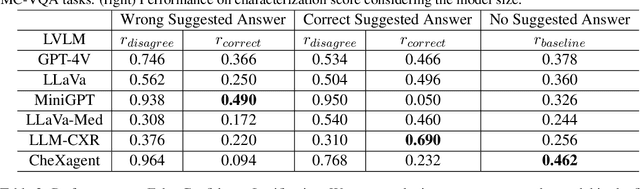
Large Vision Language Models (LVLMs) have recently achieved superior performance in various tasks on natural image and text data, which inspires a large amount of studies for LVLMs fine-tuning and training. Despite their advancements, there has been scant research on the robustness of these models against hallucination when fine-tuned on smaller datasets. In this study, we introduce a new benchmark dataset, the Medical Visual Hallucination Test (MedVH), to evaluate the hallucination of domain-specific LVLMs. MedVH comprises five tasks to evaluate hallucinations in LVLMs within the medical context, which includes tasks for comprehensive understanding of textual and visual input, as well as long textual response generation. Our extensive experiments with both general and medical LVLMs reveal that, although medical LVLMs demonstrate promising performance on standard medical tasks, they are particularly susceptible to hallucinations, often more so than the general models, raising significant concerns about the reliability of these domain-specific models. For medical LVLMs to be truly valuable in real-world applications, they must not only accurately integrate medical knowledge but also maintain robust reasoning abilities to prevent hallucination. Our work paves the way for future evaluations of these studies.
Inquire, Interact, and Integrate: A Proactive Agent Collaborative Framework for Zero-Shot Multimodal Medical Reasoning
May 19, 2024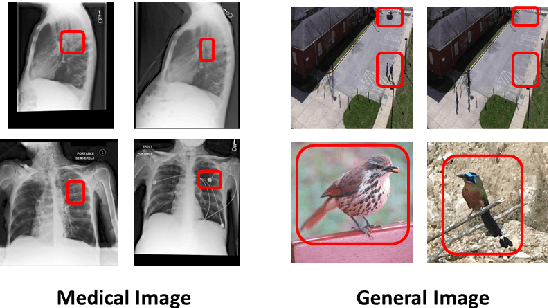
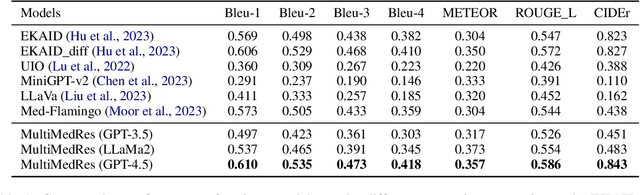
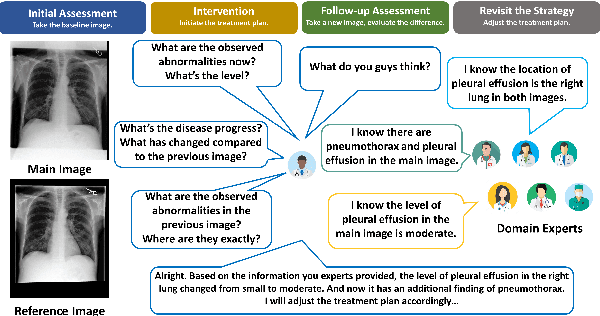
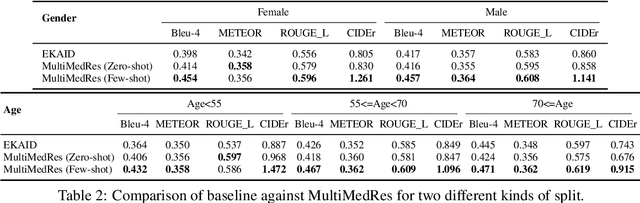
The adoption of large language models (LLMs) in healthcare has attracted significant research interest. However, their performance in healthcare remains under-investigated and potentially limited, due to i) they lack rich domain-specific knowledge and medical reasoning skills; and ii) most state-of-the-art LLMs are unimodal, text-only models that cannot directly process multimodal inputs. To this end, we propose a multimodal medical collaborative reasoning framework \textbf{MultiMedRes}, which incorporates a learner agent to proactively gain essential information from domain-specific expert models, to solve medical multimodal reasoning problems. Our method includes three steps: i) \textbf{Inquire}: The learner agent first decomposes given complex medical reasoning problems into multiple domain-specific sub-problems; ii) \textbf{Interact}: The agent then interacts with domain-specific expert models by repeating the ``ask-answer'' process to progressively obtain different domain-specific knowledge; iii) \textbf{Integrate}: The agent finally integrates all the acquired domain-specific knowledge to accurately address the medical reasoning problem. We validate the effectiveness of our method on the task of difference visual question answering for X-ray images. The experiments demonstrate that our zero-shot prediction achieves state-of-the-art performance, and even outperforms the fully supervised methods. Besides, our approach can be incorporated into various LLMs and multimodal LLMs to significantly boost their performance.
Are All Edges Necessary? A Unified Framework for Graph Purification
Nov 09, 2022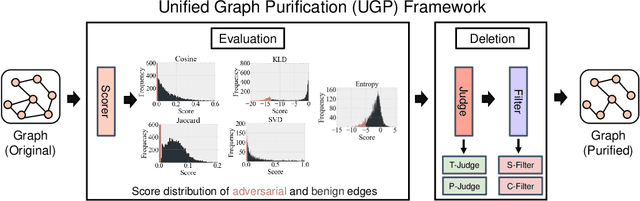
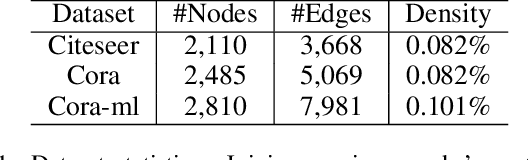
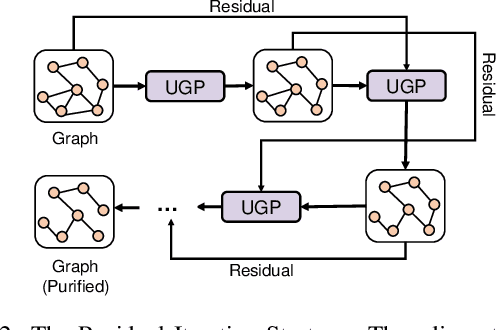

Graph Neural Networks (GNNs) as deep learning models working on graph-structure data have achieved advanced performance in many works. However, it has been proved repeatedly that, not all edges in a graph are necessary for the training of machine learning models. In other words, some of the connections between nodes may bring redundant or even misleading information to downstream tasks. In this paper, we try to provide a method to drop edges in order to purify the graph data from a new perspective. Specifically, it is a framework to purify graphs with the least loss of information, under which the core problems are how to better evaluate the edges and how to delete the relatively redundant edges with the least loss of information. To address the above two problems, we propose several measurements for the evaluation and different judges and filters for the edge deletion. We also introduce a residual-iteration strategy and a surrogate model for measurements requiring unknown information. The experimental results show that our proposed measurements for KL divergence with constraints to maintain the connectivity of the graph and delete edges in an iterative way can find out the most edges while keeping the performance of GNNs. What's more, further experiments show that this method also achieves the best defense performance against adversarial attacks.