 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying global optimality for dictionary learning
Paper and Code
Aug 07, 2017

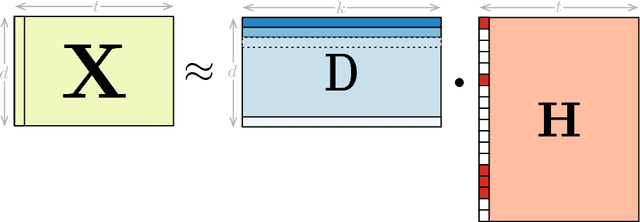
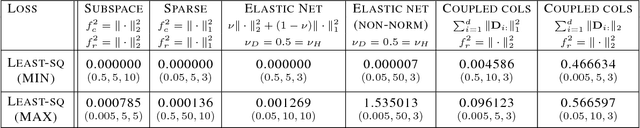
Learning new representations of input observations in machine learning is often tackled using a factorization of the data. For many such problems, including sparse coding and matrix completion, learning these factorizations can be difficult, in terms of efficiency and to guarantee that the solution is a global minimum. Recently, a general class of objectives have been introduced-which we term induced dictionary learning models (DLMs)-that have an induced convex form that enables global optimization. Though attractive theoretically, this induced form is impractical, particularly for large or growing datasets. In this work, we investigate the use of practical alternating minimization algorithms for induced DLMs, that ensure convergence to global optima. We characterize the stationary points of these models, and, using these insights, highlight practical choices for the objectives. We then provide theoretical and empirical evidence that alternating minimization, from a random initialization, converges to global minima for a large subclass of induced DLMs. In particular, we take advantage of the existence of the (potentially unknown) convex induced form, to identify when stationary points are global minima for the dictionary learning objective. We then provide an empirical investigation into practical optimization choices for using alternating minimization for induced DLMs, for both batch and stochastic gradient descent.