 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Actor-Critic with Emphatic Weightings
Paper and Code
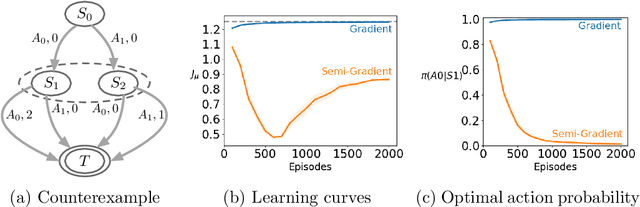
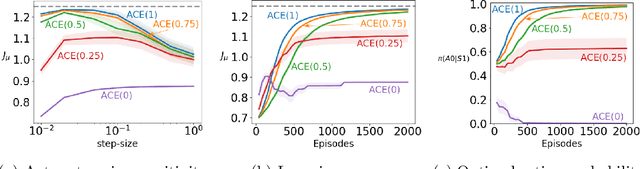
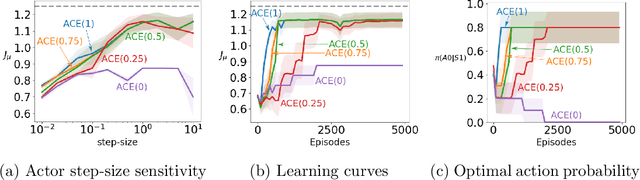
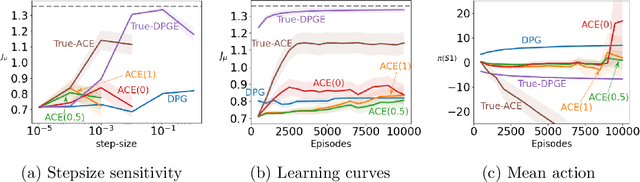
A variety of theoretically-sound policy gradient algorithms exist for the on-policy setting due to the policy gradient theorem, which provides a simplified form for the gradient. The off-policy setting, however, has been less clear due to the existence of multiple objectives and the lack of an explicit off-policy policy gradient theorem. In this work, we unify these objectives into one off-policy objective, and provide a policy gradient theorem for this unified objective. The derivation involves emphatic weightings and interest functions. We show multiple strategies to approximate the gradients, in an algorithm called Actor Critic with Emphatic weightings (ACE). We prove in a counterexample that previous (semi-gradient) off-policy actor-critic methods--particularly OffPAC and DPG--converge to the wrong solution whereas ACE finds the optimal solution. We also highlight why these semi-gradient approaches can still perform well in practice, suggesting strategies for variance reduction in ACE. We empirically study several variants of ACE on two classic control environments and an image-based environment designed to illustrate the tradeoffs made by each gradient approximation. We find that by approximating the emphatic weightings directly, ACE performs as well as or better than OffPAC in all settings tested.