 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cross-environment Hyperparameter Setting Benchmark for Reinforcement Learning
Jul 26, 2024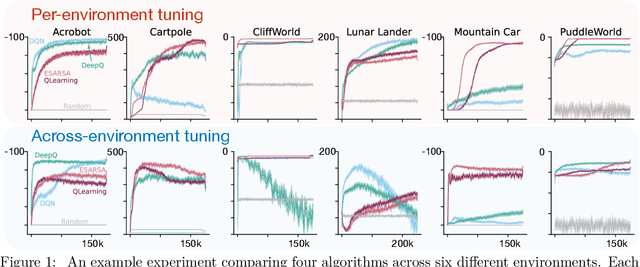
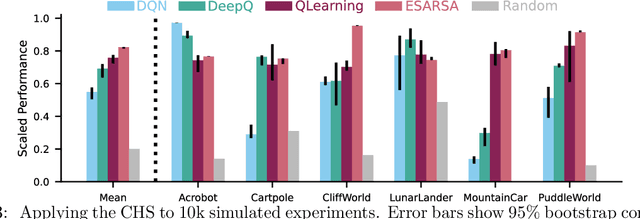
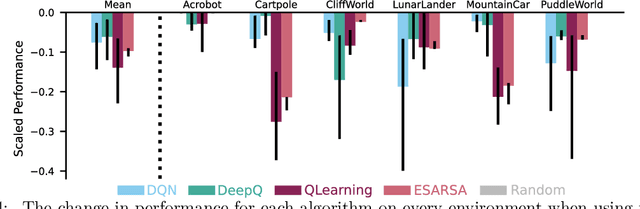
This paper introduces a new empirical methodology, the Cross-environment Hyperparameter Setting Benchmark, that compares RL algorithms across environments using a single hyperparameter setting, encouraging algorithmic development which is insensitive to hyperparameters. We demonstrate that this benchmark is robust to statistical noise and obtains qualitatively similar results across repeated applications, even when using few samples. This robustness makes the benchmark computationally cheap to apply, allowing statistically sound insights at low cost. We demonstrate two example instantiations of the CHS, on a set of six small control environments (SC-CHS) and on the entire DM Control suite of 28 environments (DMC-CHS). Finally, to illustrate the applicability of the CHS to modern RL algorithms on challenging environments, we conduct a novel empirical study of an open question in the continuous control literature. We show, with high confidence, that there is no meaningful difference in performance between Ornstein-Uhlenbeck noise and uncorrelated Gaussian noise for exploration with the DDPG algorithm on the DMC-CHS.
Empirical Design in Reinforcement Learning
Apr 03, 2023Empirical design in reinforcement learning is no small task. Running good experiments requires attention to detail and at times significant computational resources. While compute resources available per dollar have continued to grow rapidly, so have the scale of typical experiments in reinforcement learning. It is now common to benchmark agents with millions of parameters against dozens of tasks, each using the equivalent of 30 days of experience. The scale of these experiments often conflict with the need for proper statistical evidence, especially when comparing algorithms. Recent studies have highlighted how popular algorithms are sensitive to hyper-parameter settings and implementation details, and that common empirical practice leads to weak statistical evidence (Machado et al., 2018; Henderson et al., 2018). Here we take this one step further. This manuscript represents both a call to action, and a comprehensive resource for how to do good experiments in reinforcement learning. In particular, we cover: the statistical assumptions underlying common performance measures, how to properly characterize performance variation and stability, hypothesis testing, special considerations for comparing multiple agents, baseline and illustrative example construction, and how to deal with hyper-parameters and experimenter bias. Throughout we highlight common mistakes found in the literature and the statistical consequences of those in example experiments. The objective of this document is to provide answers on how we can use our unprecedented compute to do good science in reinforcement learning, as well as stay alert to potential pitfalls in our empirical design.