 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Foundations for Continual Reinforcement Learning
Apr 10, 2025Algorithms and approaches for continual reinforcement learning have gained increasing attention. Much of this early progress rests on the foundations and standard practices of traditional reinforcement learning, without questioning if they are well-suited to the challenges of continual learning agents. We suggest that many core foundations of traditional RL are, in fact, antithetical to the goals of continual reinforcement learning. We enumerate four such foundations: the Markov decision process formalism, a focus on optimal policies, the expected sum of rewards as the primary evaluation metric, and episodic benchmark environments that embrace the other three foundations. Shedding such sacredly held and taught concepts is not easy. They are self-reinforcing in that each foundation depends upon and holds up the others, making it hard to rethink each in isolation. We propose an alternative set of all four foundations that are better suited to the continual learning setting. We hope to spur on others in rethinking the traditional foundations, proposing and critiquing alternatives, and developing new algorithms and approaches enabled by better-suited foundations.
Real-Time Recurrent Learning using Trace Units in Reinforcement Learning
Sep 02, 2024



Recurrent Neural Networks (RNNs) are used to learn representations in partially observable environments. For agents that learn online and continually interact with the environment, it is desirable to train RNNs with real-time recurrent learning (RTRL); unfortunately, RTRL is prohibitively expensive for standard RNNs. A promising direction is to use linear recurrent architectures (LRUs), where dense recurrent weights are replaced with a complex-valued diagonal, making RTRL efficient. In this work, we build on these insights to provide a lightweight but effective approach for training RNNs in online RL. We introduce Recurrent Trace Units (RTUs), a small modification on LRUs that we nonetheless find to have significant performance benefits over LRUs when trained with RTRL. We find RTUs significantly outperform other recurrent architectures across several partially observable environments while using significantly less computation.
Investigating the Histogram Loss in Regression
Feb 20, 2024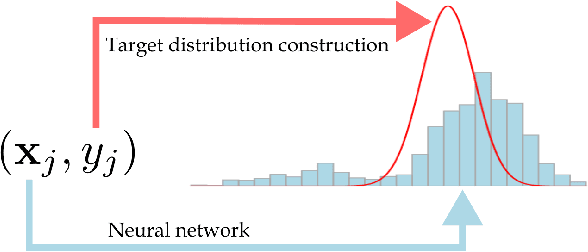
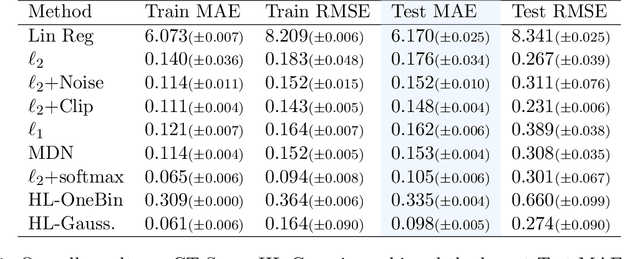
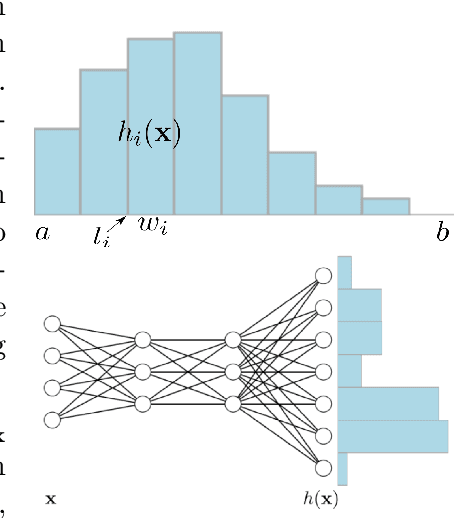

It is becoming increasingly common in regression to train neural networks that model the entire distribution even if only the mean is required for prediction. This additional modeling often comes with performance gain and the reasons behind the improvement are not fully known. This paper investigates a recent approach to regression, the Histogram Loss, which involves learning the conditional distribution of the target variable by minimizing the cross-entropy between a target distribution and a flexible histogram prediction. We design theoretical and empirical analyses to determine why and when this performance gain appears, and how different components of the loss contribute to it. Our results suggest that the benefits of learning distributions in this setup come from improvements in optimization rather than learning a better representation. We then demonstrate the viability of the Histogram Loss in common deep learning applications without a need for costly hyperparameter tuning.
Recurrent Linear Transformers
Oct 24, 2023The self-attention mechanism in the transformer architecture is capable of capturing long-range dependencies and it is the main reason behind its effectiveness in processing sequential data. Nevertheless, despite their success, transformers have two significant drawbacks that still limit their broader applicability: (1) In order to remember past information, the self-attention mechanism requires access to the whole history to be provided as context. (2) The inference cost in transformers is expensive. In this paper we introduce recurrent alternatives to the transformer self-attention mechanism that offer a context-independent inference cost, leverage long-range dependencies effectively, and perform well in practice. We evaluate our approaches in reinforcement learning problems where the aforementioned computational limitations make the application of transformers nearly infeasible. We quantify the impact of the different components of our architecture in a diagnostic environment and assess performance gains in 2D and 3D pixel-based partially-observable environments. When compared to a state-of-the-art architecture, GTrXL, inference in our approach is at least 40% cheaper while reducing memory use in more than 50%. Our approach either performs similarly or better than GTrXL, improving more than 37% upon GTrXL performance on harder tasks.