 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hierarchical Domain Adaptation for Pretrained Language Models
Paper and Code
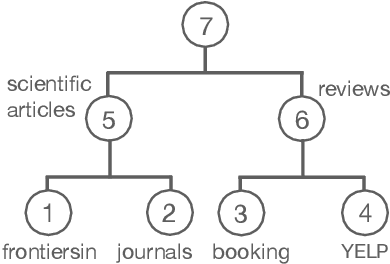
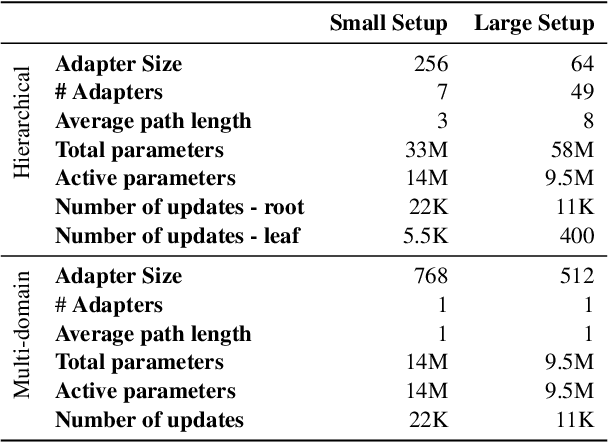


Generative language models are trained on diverse, general domain corpora. However, this limits their applicability to narrower domains, and prior work has shown that continued in-domain training can provide further gains. In this paper, we introduce a method to scale domain adaptation to many diverse domains using a computationally efficient adapter approach. Our method is based on the observation that textual domains are partially overlapping, and we represent domains as a hierarchical tree structure where each node in the tree is associated with a set of adapter weights. When combined with a frozen pretrained language model, this approach enables parameter sharing among related domains, while avoiding negative interference between unrelated ones. It is efficient and computational cost scales as O(log(D)) for D domains. Experimental results with GPT-2 and a large fraction of the 100 most represented websites in C4 show across-the-board improvements in-domain. We additionally provide an inference time algorithm for a held-out domain and show that averaging over multiple paths through the tree enables further gains in generalization, while adding only a marginal cost to inference.