 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaKase-8B: Legal Case Retrieval via Knowledge and Reasoning Representations with LLMs
Oct 30, 2025Legal case retrieval (LCR) is a cornerstone of real-world legal decision making, as it enables practitioners to identify precedents for a given query case. Existing approaches mainly rely on traditional lexical models and pretrained language models to encode the texts of legal cases. Yet there are rich information in the relations among different legal entities as well as the crucial reasoning process that uncovers how legal facts and legal issues can lead to judicial decisions. Such relational reasoning process reflects the distinctive characteristics of each case that can distinguish one from another, mirroring the real-world judicial process. Naturally, incorporating such information into the precise case embedding could further enhance the accuracy of case retrieval. In this paper, a novel ReaKase-8B framework is proposed to leverage extracted legal facts, legal issues, legal relation triplets and legal reasoning for effective legal case retrieval. ReaKase-8B designs an in-context legal case representation learning paradigm with a fine-tuned large language model. Extensive experiments on two benchmark datasets from COLIEE 2022 and COLIEE 2023 demonstrate that our knowledge and reasoning augmented embeddings substantially improve retrieval performance over baseline models, highlighting the potential of integrating legal reasoning into legal case retrieval systems. The code has been released on https://github.com/yanran-tang/ReaKase-8B.
ALSA: Anchors in Logit Space for Out-of-Distribution Accuracy Estimation
Aug 27, 2025Estimating model accuracy on unseen, unlabeled datasets is crucial for real-world machine learning applications, especially under distribution shifts that can degrade performance. Existing methods often rely on predicted class probabilities (softmax scores) or data similarity metrics. While softmax-based approaches benefit from representing predictions on the standard simplex, compressing logits into probabilities leads to information loss. Meanwhile, similarity-based methods can be computationally expensive and domain-specific, limiting their broader applicability. In this paper, we introduce ALSA (Anchors in Logit Space for Accuracy estimation), a novel framework that preserves richer information by operating directly in the logit space. Building on theoretical insights and empirical observations, we demonstrate that the aggregation and distribution of logits exhibit a strong correlation with the predictive performance of the model. To exploit this property, ALSA employs an anchor-based modeling strategy: multiple learnable anchors are initialized in logit space, each assigned an influence function that captures subtle variations in the logits. This allows ALSA to provide robust and accurate performance estimates across a wide range of distribution shifts. Extensive experiments on vision, language, and graph benchmarks demonstrate ALSA's superiority over both softmax- and similarity-based baselines. Notably, ALSA's robustness under significant distribution shifts highlights its potential as a practical tool for reliable model evaluation.
UQLegalAI@COLIEE2025: Advancing Legal Case Retrieval with Large Language Models and Graph Neural Networks
May 27, 2025Legal case retrieval plays a pivotal role in the legal domain by facilitating the efficient identification of relevant cases, supporting legal professionals and researchers to propose legal arguments and make informed decision-making. To improve retrieval accuracy, the Competition on Legal Information Extraction and Entailment (COLIEE) is held annually, offering updated benchmark datasets for evaluation. This paper presents a detailed description of CaseLink, the method employed by UQLegalAI, the second highest team in Task 1 of COLIEE 2025. The CaseLink model utilises inductive graph learning and Global Case Graphs to capture the intrinsic case connectivity to improve the accuracy of legal case retrieval. Specifically, a large language model specialized in text embedding is employed to transform legal texts into embeddings, which serve as the feature representations of the nodes in the constructed case graph. A new contrastive objective, incorporating a regularization on the degree of case nodes, is proposed to leverage the information within the case reference relationship for model optimization. The main codebase used in our method is based on an open-sourced repo of CaseLink: https://github.com/yanran-tang/CaseLink.
CaseGNN++: Graph Contrastive Learning for Legal Case Retrieval with Graph Augmentation
May 20, 2024



Legal case retrieval (LCR) is a specialised information retrieval task that aims to find relevant cases to a given query case. LCR holds pivotal significance in facilitating legal practitioners in finding precedents. Most of existing LCR methods are based on traditional lexical models and language models, which have gained promising performance in retrieval. However, the domain-specific structural information inherent in legal documents is yet to be exploited to further improve the performance. Our previous work CaseGNN successfully harnesses text-attributed graphs and graph neural networks to address the problem of legal structural information neglect. Nonetheless, there remain two aspects for further investigation: (1) The underutilization of rich edge information within text-attributed case graphs limits CaseGNN to generate informative case representation. (2) The inadequacy of labelled data in legal datasets hinders the training of CaseGNN model. In this paper, CaseGNN++, which is extended from CaseGNN, is proposed to simultaneously leverage the edge information and additional label data to discover the latent potential of LCR models. Specifically, an edge feature-based graph attention layer (EUGAT) is proposed to comprehensively update node and edge features during graph modelling, resulting in a full utilisation of structural information of legal cases. Moreover, a novel graph contrastive learning objective with graph augmentation is developed in CaseGNN++ to provide additional training signals, thereby enhancing the legal comprehension capabilities of CaseGNN++ model. Extensive experiments on two benchmark datasets from COLIEE 2022 and COLIEE 2023 demonstrate that CaseGNN++ not only significantly improves CaseGNN but also achieves supreme performance compared to state-of-the-art LCR methods. Code has been released on https://github.com/yanran-tang/CaseGNN.
CaseLink: Inductive Graph Learning for Legal Case Retrieval
Apr 10, 2024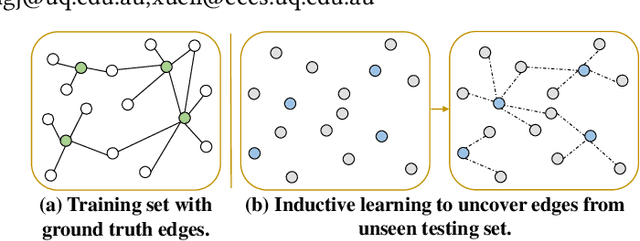
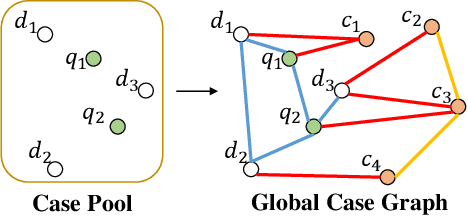

In case law, the precedents are the relevant cases that are used to support the decisions made by the judges and the opinions of lawyers towards a given case. This relevance is referred to as the case-to-case reference relation. To efficiently find relevant cases from a large case pool, retrieval tools are widely used by legal practitioners. Existing legal case retrieval models mainly work by comparing the text representations of individual cases. Although they obtain a decent retrieval accuracy, the intrinsic case connectivity relationships among cases have not been well exploited for case encoding, therefore limiting the further improvement of retrieval performance. In a case pool, there are three types of case connectivity relationships: the case reference relationship, the case semantic relationship, and the case legal charge relationship. Due to the inductive manner in the task of legal case retrieval, using case reference as input is not applicable for testing. Thus, in this paper, a CaseLink model based on inductive graph learning is proposed to utilise the intrinsic case connectivity for legal case retrieval, a novel Global Case Graph is incorporated to represent both the case semantic relationship and the case legal charge relationship. A novel contrastive objective with a regularisation on the degree of case nodes is proposed to leverage the information carried by the case reference relationship to optimise the model. Extensive experiments have been conducted on two benchmark datasets, which demonstrate the state-of-the-art performance of CaseLink. The code has been released on https://github.com/yanran-tang/CaseLink.
PUMA: Efficient Continual Graph Learning with Graph Condensation
Dec 22, 2023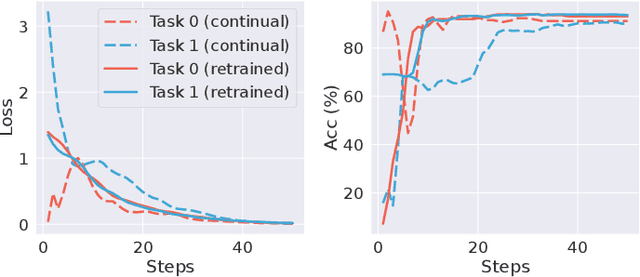

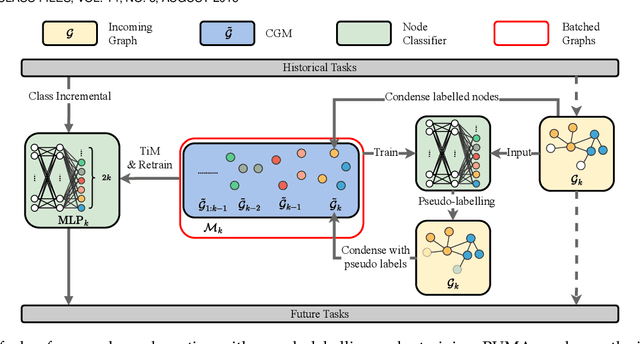
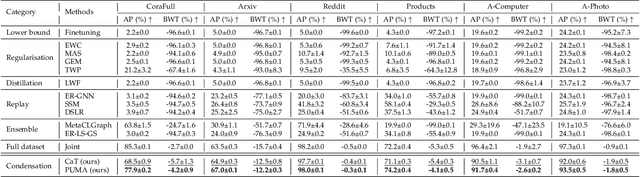
When handling streaming graphs, existing graph representation learning models encounter a catastrophic forgetting problem, where previously learned knowledge of these models is easily overwritten when learning with newly incoming graphs. In response, Continual Graph Learning emerges as a novel paradigm enabling graph representation learning from static to streaming graphs. Our prior work, CaT is a replay-based framework with a balanced continual learning procedure, which designs a small yet effective memory bank for replaying data by condensing incoming graphs. Although the CaT alleviates the catastrophic forgetting problem, there exist three issues: (1) The graph condensation algorithm derived in CaT only focuses on labelled nodes while neglecting abundant information carried by unlabelled nodes; (2) The continual training scheme of the CaT overemphasises on the previously learned knowledge, limiting the model capacity to learn from newly added memories; (3) Both the condensation process and replaying process of the CaT are time-consuming. In this paper, we propose a psudo-label guided memory bank (PUMA) CGL framework, extending from the CaT to enhance its efficiency and effectiveness by overcoming the above-mentioned weaknesses and limits. To fully exploit the information in a graph, PUMA expands the coverage of nodes during graph condensation with both labelled and unlabelled nodes. Furthermore, a training-from-scratch strategy is proposed to upgrade the previous continual learning scheme for a balanced training between the historical and the new graphs. Besides, PUMA uses a one-time prorogation and wide graph encoders to accelerate the graph condensation and the graph encoding process in the training stage to improve the efficiency of the whole framework. Extensive experiments on four datasets demonstrate the state-of-the-art performance and efficiency over existing methods.
CaseGNN: Graph Neural Networks for Legal Case Retrieval with Text-Attributed Graphs
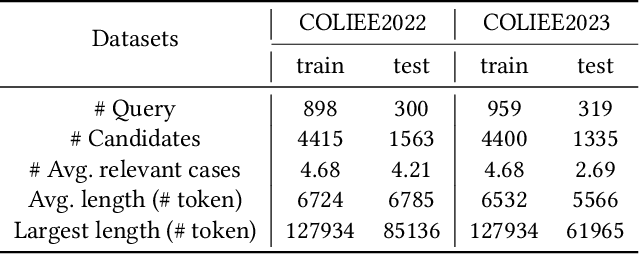
Dec 19, 2023Legal case retrieval is an information retrieval task in the legal domain, which aims to retrieve relevant cases with a given query case. Recent research of legal case retrieval mainly relies on traditional bag-of-words models and language models. Although these methods have achieved significant improvement in retrieval accuracy, there are still two challenges: (1) Legal structural information neglect. Previous neural legal case retrieval models mostly encode the unstructured raw text of case into a case representation, which causes the lack of important legal structural information in a case and leads to poor case representation; (2) Lengthy legal text limitation. When using the powerful BERT-based models, there is a limit of input text lengths, which inevitably requires to shorten the input via truncation or division with a loss of legal context information. In this paper, a graph neural networks-based legal case retrieval model, CaseGNN, is developed to tackle these challenges. To effectively utilise the legal structural information during encoding, a case is firstly converted into a Text-Attributed Case Graph (TACG), followed by a designed Edge Graph Attention Layer and a readout function to obtain the case graph representation. The CaseGNN model is optimised with a carefully designed contrastive loss with easy and hard negative sampling. Since the text attributes in the case graph come from individual sentences, the restriction of using language models is further avoided without losing the legal context. Extensive experiments have been conducted on two benchmarks from COLIEE 2022 and COLIEE 2023, which demonstrate that CaseGNN outperforms other state-of-the-art legal case retrieval methods. The code has been released on https://github.com/yanran-tang/CaseGNN.
Prompt-based Effective Input Reformulation for Legal Case Retrieval
Sep 06, 2023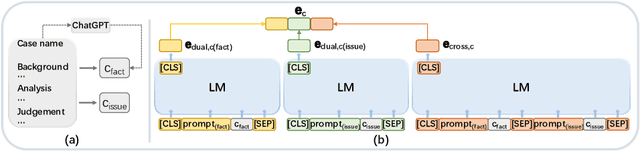



Legal case retrieval plays an important role for legal practitioners to effectively retrieve relevant cases given a query case. Most existing neural legal case retrieval models directly encode the whole legal text of a case to generate a case representation, which is then utilised to conduct a nearest neighbour search for retrieval. Although these straightforward methods have achieved improvement over conventional statistical methods in retrieval accuracy, two significant challenges are identified in this paper: (1) Legal feature alignment: the usage of the whole case text as the input will generally incorporate redundant and noisy information because, from the legal perspective, the determining factor of relevant cases is the alignment of key legal features instead of whole text matching; (2) Legal context preservation: furthermore, since the existing text encoding models usually have an input length limit shorter than the case, the whole case text needs to be truncated or divided into paragraphs, which leads to the loss of the global context of legal information. In this paper, a novel legal case retrieval framework, PromptCase, is proposed to tackle these challenges. Firstly, legal facts and legal issues are identified and formally defined as the key features facilitating legal case retrieval based on a thorough study of the definition of relevant cases from a legal perspective. Secondly, with the determining legal features, a prompt-based encoding scheme is designed to conduct an effective encoding with language models. Extensive zero-shot experiments have been conducted on two benchmark datasets in legal case retrieval, which demonstrate the superior retrieval effectiveness of the proposed PromptCase. The code has been released on https://github.com/yanran-tang/PromptCase.