 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based Effective Input Reformulation for Legal Case Retrieval
Paper and Code
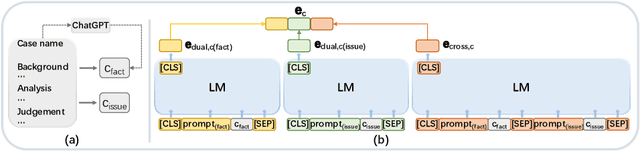



Legal case retrieval plays an important role for legal practitioners to effectively retrieve relevant cases given a query case. Most existing neural legal case retrieval models directly encode the whole legal text of a case to generate a case representation, which is then utilised to conduct a nearest neighbour search for retrieval. Although these straightforward methods have achieved improvement over conventional statistical methods in retrieval accuracy, two significant challenges are identified in this paper: (1) Legal feature alignment: the usage of the whole case text as the input will generally incorporate redundant and noisy information because, from the legal perspective, the determining factor of relevant cases is the alignment of key legal features instead of whole text matching; (2) Legal context preservation: furthermore, since the existing text encoding models usually have an input length limit shorter than the case, the whole case text needs to be truncated or divided into paragraphs, which leads to the loss of the global context of legal information. In this paper, a novel legal case retrieval framework, PromptCase, is proposed to tackle these challenges. Firstly, legal facts and legal issues are identified and formally defined as the key features facilitating legal case retrieval based on a thorough study of the definition of relevant cases from a legal perspective. Secondly, with the determining legal features, a prompt-based encoding scheme is designed to conduct an effective encoding with language models. Extensive zero-shot experiments have been conducted on two benchmark datasets in legal case retrieval, which demonstrate the superior retrieval effectiveness of the proposed PromptCase. The code has been released on https://github.com/yanran-tang/PromptCase.