 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP$^2$-VAE: Differentially Private Pre-trained Variational Autoencoders
Paper and Code

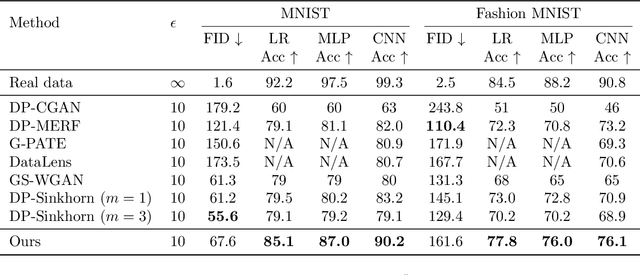

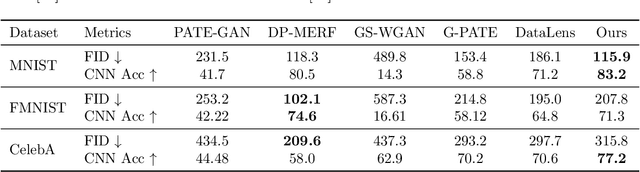
Modern machine learning systems achieve great success when trained on large datasets. However, these datasets usually contain sensitive information (e.g. medical records, face images), leading to serious privacy concerns. Differentially private generative models (DPGMs) emerge as a solution to circumvent such privacy concerns by generating privatized sensitive data. Similar to other differentially private (DP) learners, the major challenge for DPGM is also how to achieve a subtle balance between utility and privacy. We propose DP$^2$-VAE, a novel training mechanism for variational autoencoders (VAE) with provable DP guarantees and improved utility via \emph{pre-training on private data}. Under the same DP constraints, DP$^2$-VAE minimizes the perturbation noise during training, and hence improves utility. DP$^2$-VAE is very flexible and easily amenable to many other VAE variants. Theoretically, we study the effect of pretraining on private data. Empirically, we conduct extensive experiments on image datasets to illustrate our superiority over baselines under various privacy budgets and evaluation metrics.