 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-View Predictive Diffusion: Lightweight Speech Enhancement via Spectrogram-Image Synergy
Jan 31, 2026Diffusion models have recently set new benchmarks in Speech Enhancement (SE). However, most existing score-based models treat speech spectrograms merely as generic 2D images, applying uniform processing that ignores the intrinsic structural sparsity of audio, which results in inefficient spectral representation and prohibitive computational complexity. To bridge this gap, we propose DVPD, an extremely lightweight Dual-View Predictive Diffusion model, which uniquely exploits the dual nature of spectrograms as both visual textures and physical frequency-domain representations across both training and inference stages. Specifically, during training, we optimize spectral utilization via the Frequency-Adaptive Non-uniform Compression (FANC) encoder, which preserves critical low-frequency harmonics while pruning high-frequency redundancies. Simultaneously, we introduce a Lightweight Image-based Spectro-Awareness (LISA) module to capture features from a visual perspective with minimal overhead. During inference, we propose a Training-free Lossless Boost (TLB) strategy that leverages the same dual-view priors to refine generation quality without any additional fine-tuning. Extensive experiments across various benchmarks demonstrate that DVPD achieves state-of-the-art performance while requiring only 35% of the parameters and 40% of the inference MACs compared to SOTA lightweight model, PGUSE. These results highlight DVPD's superior ability to balance high-fidelity speech quality with extreme architectural efficiency. Code and audio samples are available at the anonymous website: {https://anonymous.4open.science/r/dvpd_demo-E630}
DualStream Contextual Fusion Network: Efficient Target Speaker Extraction by Leveraging Mixture and Enrollment Interactions
Feb 12, 2025



Target speaker extraction focuses on extracting a target speech signal from an environment with multiple speakers by leveraging an enrollment. Existing methods predominantly rely on speaker embeddings obtained from the enrollment, potentially disregarding the contextual information and the internal interactions between the mixture and enrollment. In this paper, we propose a novel DualStream Contextual Fusion Network (DCF-Net) in the time-frequency (T-F) domain. Specifically, DualStream Fusion Block (DSFB) is introduced to obtain contextual information and capture the interactions between contextualized enrollment and mixture representation across both spatial and channel dimensions, and then rich and consistent representations are utilized to guide the extraction network for better extraction. Experimental results demonstrate that DCF-Net outperforms state-of-the-art (SOTA) methods, achieving a scale-invariant signal-to-distortion ratio improvement (SI-SDRi) of 21.6 dB on the benchmark dataset, and exhibits its robustness and effectiveness in both noise and reverberation scenarios. In addition, the wrong extraction results of our model, called target confusion problem, reduce to 0.4%, which highlights the potential of DCF-Net for practical applications.
Beamforming Design with Partial Channel Estimation and Feedback for FDD RIS-Assisted Systems
Feb 23, 2023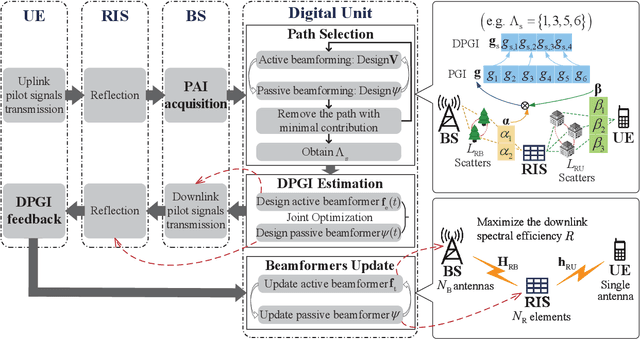
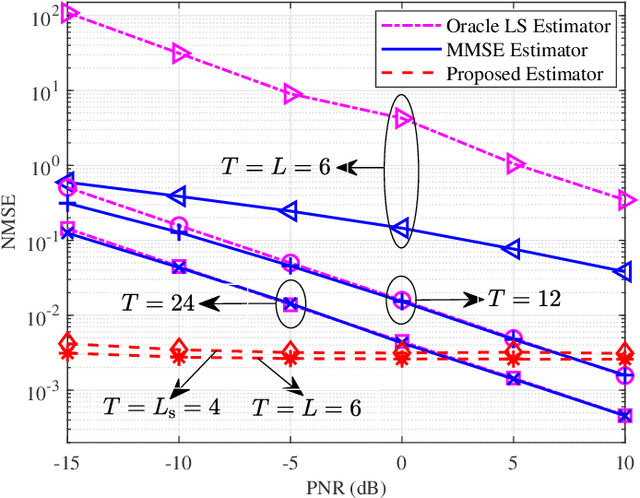
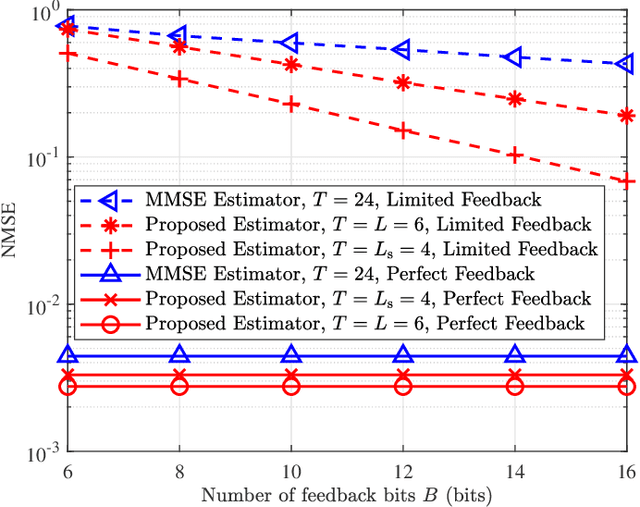
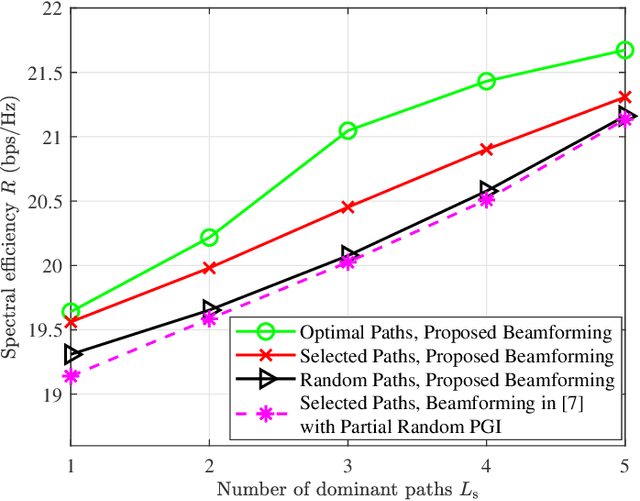
Beamforming design with partial channel estimation and feedback for frequency-division duplexing (FDD) reconfigurable intelligent surface (RIS) assisted systems is considered in this paper. We leverage the observation that path angle information (PAI) varies more slowly than path gain information (PGI). Then, several dominant paths are selected among all the cascaded paths according to the known PAI for maximizing the spectral efficiency of downlink data transmission. To acquire the dominating path gain information (DPGI, also regarded as the path gains of selected dominant paths) at the base station (BS), we propose a DPGI estimation and feedback scheme by jointly beamforming design at BS and RIS. Both the required number of downlink pilot signals and the length of uplink feedback vector are reduced to the number of dominant paths, and thus we achieve a great reduction of the pilot overhead and feedback overhead. Furthermore, we optimize the active BS beamformer and passive RIS beamformer by exploiting the feedback DPGI to further improve the spectral efficiency. From numerical results, we demonstrate the superiority of our proposed algorithms over the conventional schemes.