 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Spherical Transformer for Efficient Molecular Modeling
May 29, 2025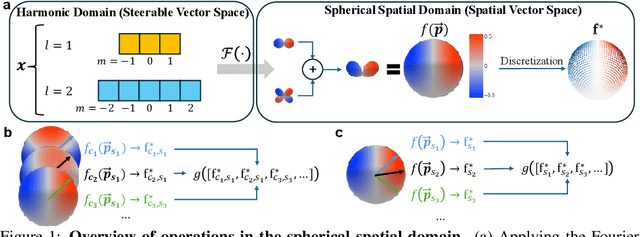
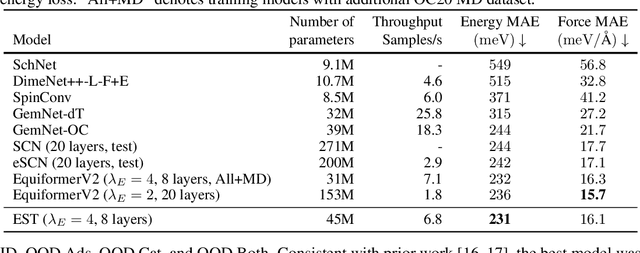
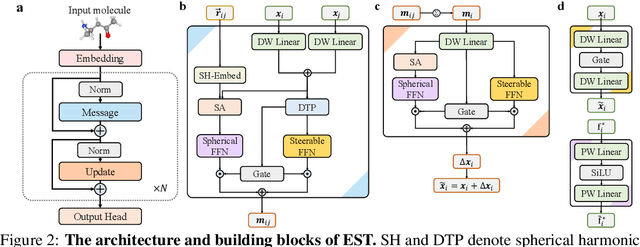
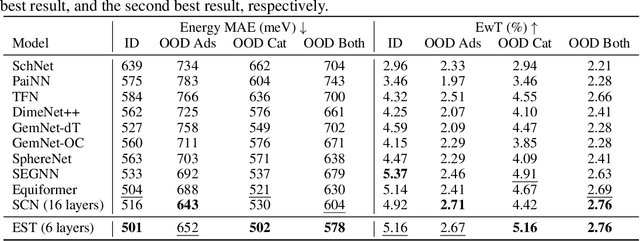
SE(3)-equivariant Graph Neural Networks (GNNs) have significantly advanced molecular system modeling by employing group representations. However, their message passing processes, which rely on tensor product-based convolutions, are limited by insufficient non-linearity and incomplete group representations, thereby restricting expressiveness. To overcome these limitations, we introduce the Equivariant Spherical Transformer (EST), a novel framework that leverages a Transformer structure within the spatial domain of group representations after Fourier transform. We theoretically and empirically demonstrate that EST can encompass the function space of tensor products while achieving superior expressiveness. Furthermore, EST's equivariant inductive bias is guaranteed through a uniform sampling strategy for the Fourier transform. Our experiments demonstrate state-of-the-art performance by EST on various molecular benchmarks, including OC20 and QM9.
PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning
Feb 20, 2019
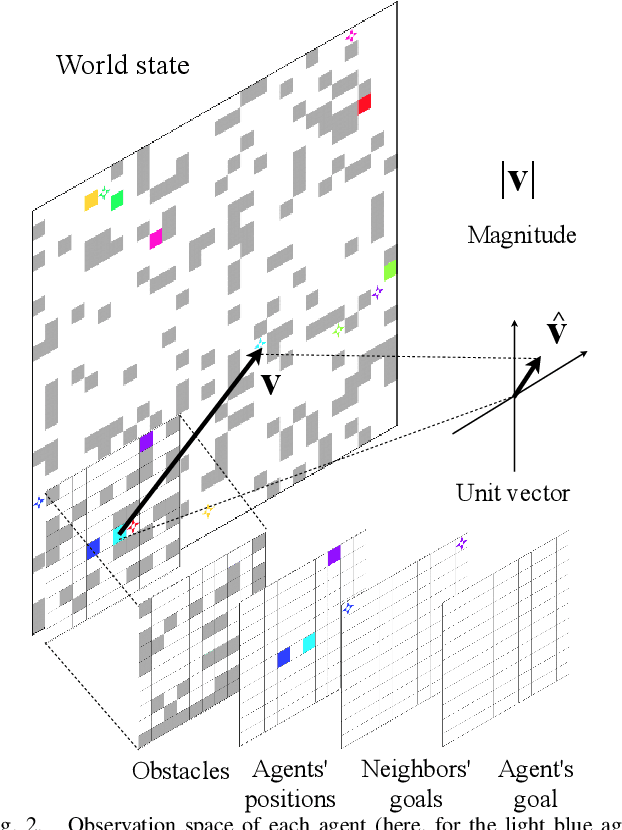
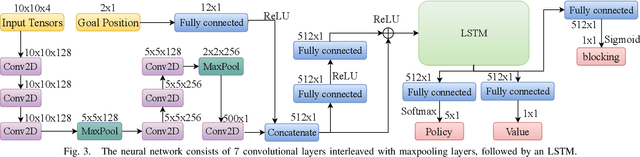
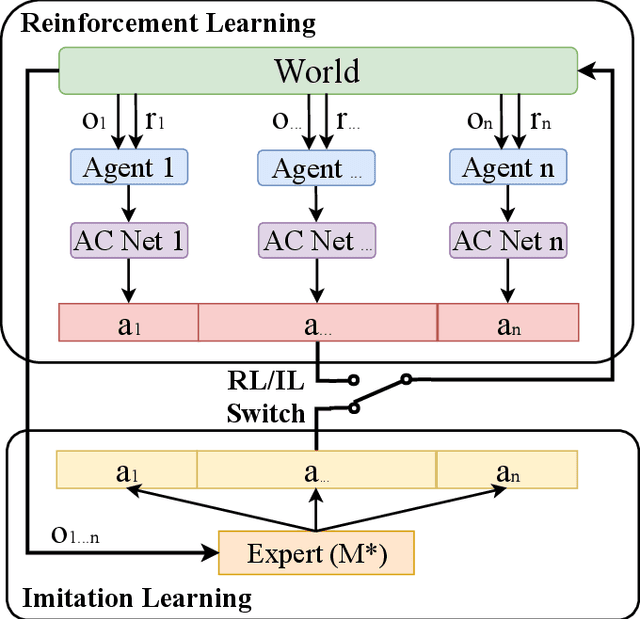
Multi-agent path finding (MAPF) is an essential component of many large-scale, real-world robot deployments, from aerial swarms to warehouse automation. However, despite the community's continued efforts, most state-of-the-art MAPF planners still rely on centralized planning and scale poorly past a few hundred agents. Such planning approaches are maladapted to real-world deployments, where noise and uncertainty often require paths be recomputed online, which is impossible when planning times are in seconds to minutes. We present PRIMAL, a novel framework for MAPF that combines reinforcement and imitation learning to teach fully-decentralized policies, where agents reactively plan paths online in a partially-observable world while exhibiting implicit coordination. This framework extends our previous work on distributed learning of collaborative policies by introducing demonstrations of an expert MAPF planner during training, as well as careful reward shaping and environment sampling. Once learned, the resulting policy can be copied onto any number of agents and naturally scales to different team sizes and world dimensions. We present results on randomized worlds with up to 1024 agents and compare success rates against state-of-the-art MAPF planners. Finally, we experimentally validate the learned policies in a hybrid simulation of a factory mockup, involving both real-world and simulated robots.
Distributed Learning of Decentralized Control Policies for Articulated Mobile Robots
Jan 24, 2019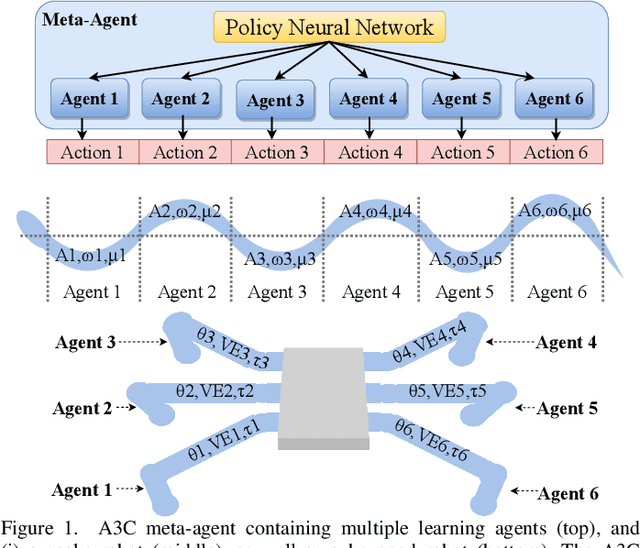
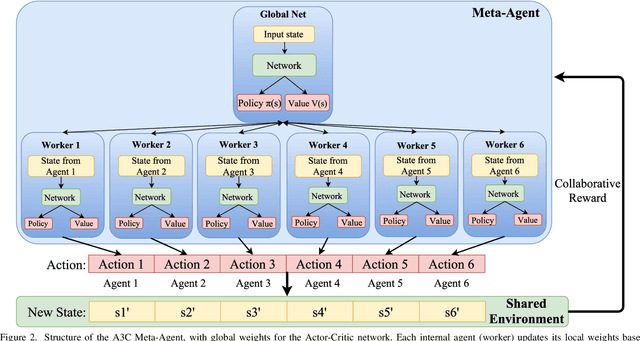
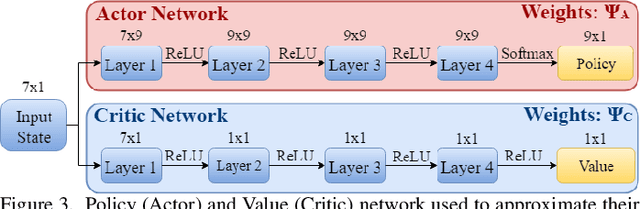
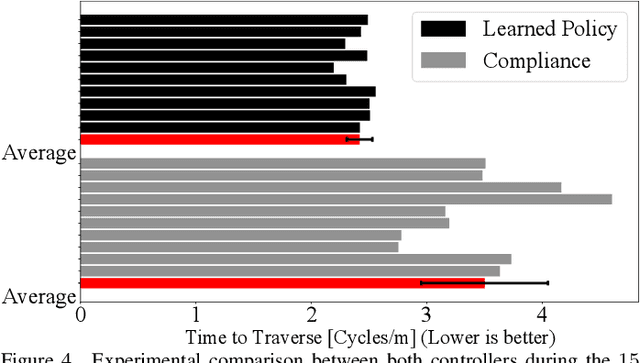
State-of-the-art distributed algorithms for reinforcement learning rely on multiple independent agents, which simultaneously learn in parallel environments while asynchronously updating a common, shared policy. Moreover, decentralized control architectures (e.g., CPGs) can coordinate spatially distributed portions of an articulated robot to achieve system-level objectives. In this work, we investigate the relationship between distributed learning and decentralized control by learning decentralized control policies for the locomotion of articulated robots in challenging environments. To this end, we present an approach that leverages the structure of the asynchronous advantage actor-critic (A3C) algorithm to provide a natural means of learning decentralized control policies on a single articulated robot. Our primary contribution shows individual agents in the A3C algorithm can be defined by independently controlled portions of the robot's body, thus enabling distributed learning on a single robot for efficient hardware implementation. We present results of closed-loop locomotion in unstructured terrains on a snake and a hexapod robot, using decentralized controllers learned offline and online respectively. Preprint of the paper submitted to the IEEE Transactions in Robotics (T-RO) journal in October 2018, and conditionally accepted for publication as a regular paper in January 2019.