 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous robot teams with unified perception and autonomy: How Team CSIRO Data61 tied for the top score at the DARPA Subterranean Challenge
Feb 26, 2023



The DARPA Subterranean Challenge was designed for competitors to develop and deploy teams of autonomous robots to explore difficult unknown underground environments. Categorised in to human-made tunnels, underground urban infrastructure and natural caves, each of these subdomains had many challenging elements for robot perception, locomotion, navigation and autonomy. These included degraded wireless communication, poor visibility due to smoke, narrow passages and doorways, clutter, uneven ground, slippery and loose terrain, stairs, ledges, overhangs, dripping water, and dynamic obstacles that move to block paths among others. In the Final Event of this challenge held in September 2021, the course consisted of all three subdomains. The task was for the robot team to perform a scavenger hunt for a number of pre-defined artefacts within a limited time frame. Only one human supervisor was allowed to communicate with the robots once they were in the course. Points were scored when accurate detections and their locations were communicated back to the scoring server. A total of 8 teams competed in the finals held at the Mega Cavern in Louisville, KY, USA. This article describes the systems deployed by Team CSIRO Data61 that tied for the top score and won second place at the event.
Heterogeneous Ground and Air Platforms, Homogeneous Sensing: Team CSIRO Data61's Approach to the DARPA Subterranean Challenge
Apr 19, 2021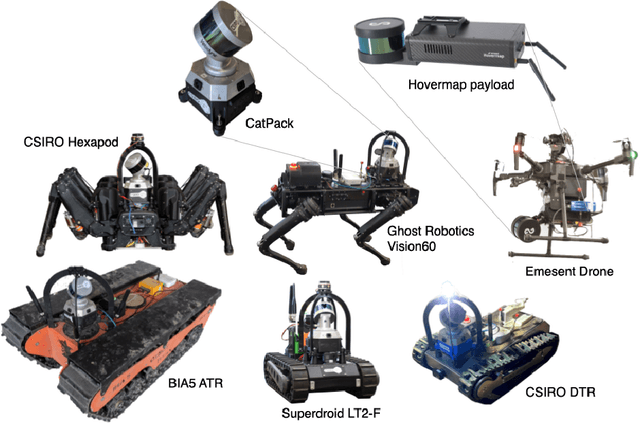
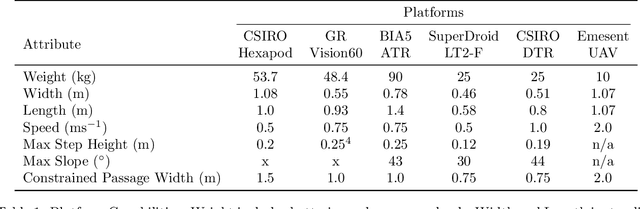
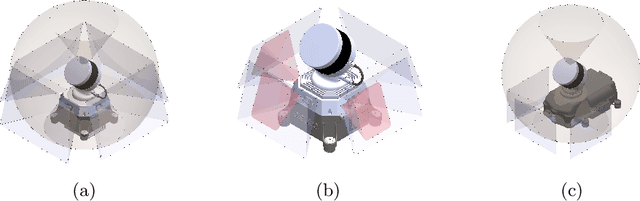
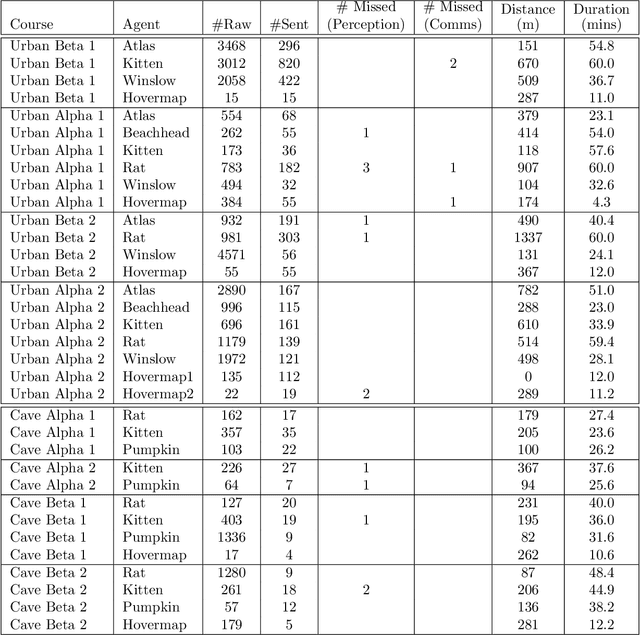
Heterogeneous teams of robots, leveraging a balance between autonomy and human interaction, bring powerful capabilities to the problem of exploring dangerous, unstructured subterranean environments. Here we describe the solution developed by Team CSIRO Data61, consisting of CSIRO, Emesent and Georgia Tech, during the DARPA Subterranean Challenge. These presented systems were fielded in the Tunnel Circuit in August 2019, the Urban Circuit in February 2020, and in our own Cave event, conducted in September 2020. A unique capability of the fielded team is the homogeneous sensing of the platforms utilised, which is leveraged to obtain a decentralised multi-agent SLAM solution on each platform (both ground agents and UAVs) using peer-to-peer communications. This enabled a shift in focus from constructing a pervasive communications network to relying on multi-agent autonomy, motivated by experiences in early circuit events. These experiences also showed the surprising capability of rugged tracked platforms for challenging terrain, which in turn led to the heterogeneous team structure based on a BIA5 OzBot Titan ground robot and an Emesent Hovermap UAV, supplemented by smaller tracked or legged ground robots. The ground agents use a common CatPack perception module, which allowed reuse of the perception and autonomy stack across all ground agents with minimal adaptation.
PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning
Feb 20, 2019
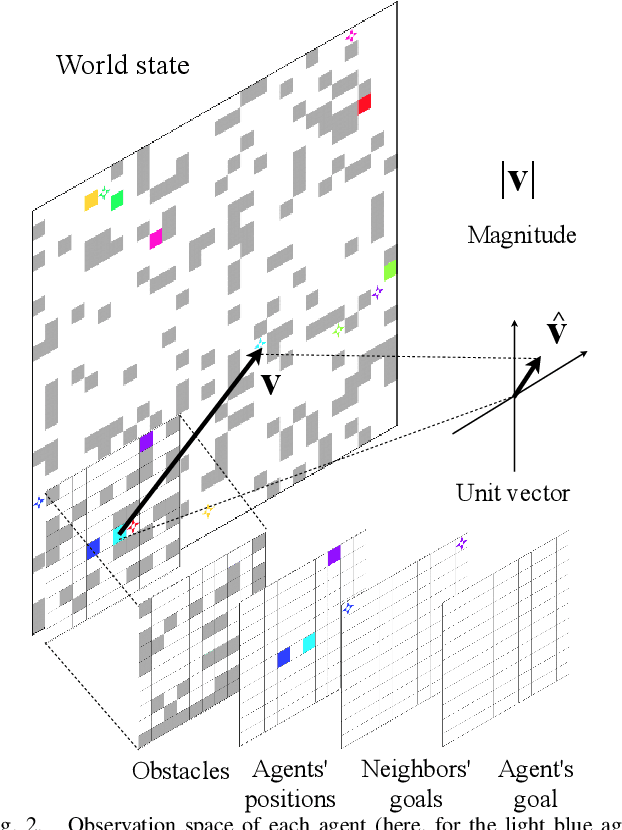
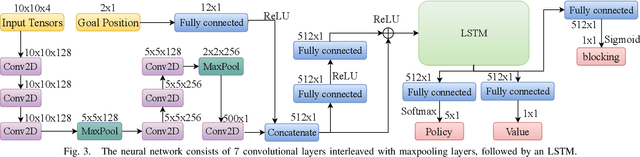
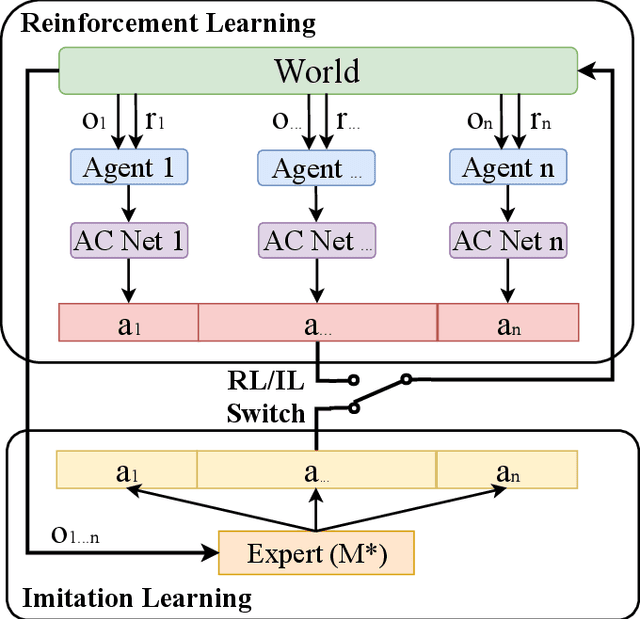
Multi-agent path finding (MAPF) is an essential component of many large-scale, real-world robot deployments, from aerial swarms to warehouse automation. However, despite the community's continued efforts, most state-of-the-art MAPF planners still rely on centralized planning and scale poorly past a few hundred agents. Such planning approaches are maladapted to real-world deployments, where noise and uncertainty often require paths be recomputed online, which is impossible when planning times are in seconds to minutes. We present PRIMAL, a novel framework for MAPF that combines reinforcement and imitation learning to teach fully-decentralized policies, where agents reactively plan paths online in a partially-observable world while exhibiting implicit coordination. This framework extends our previous work on distributed learning of collaborative policies by introducing demonstrations of an expert MAPF planner during training, as well as careful reward shaping and environment sampling. Once learned, the resulting policy can be copied onto any number of agents and naturally scales to different team sizes and world dimensions. We present results on randomized worlds with up to 1024 agents and compare success rates against state-of-the-art MAPF planners. Finally, we experimentally validate the learned policies in a hybrid simulation of a factory mockup, involving both real-world and simulated robots.
Multi-Agent Path Finding with Deadlines
Jun 11, 2018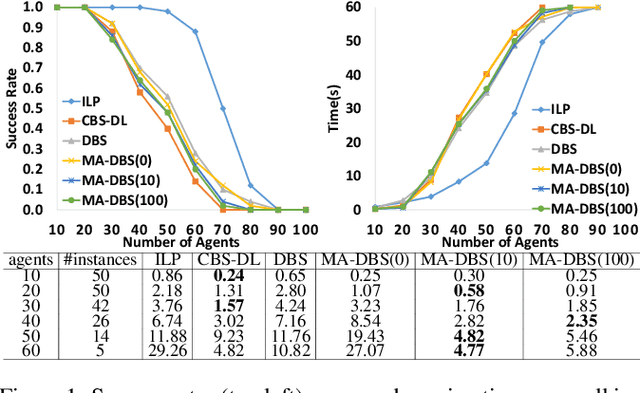
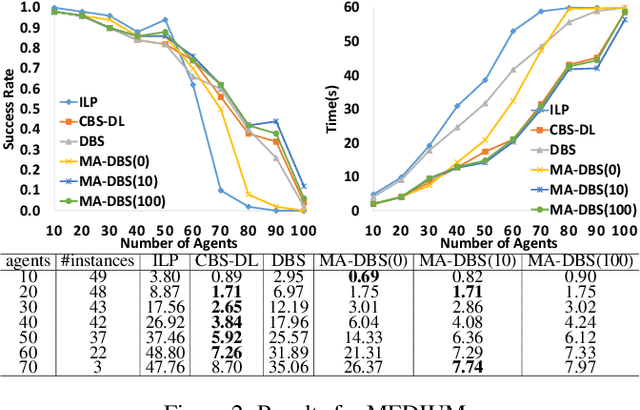
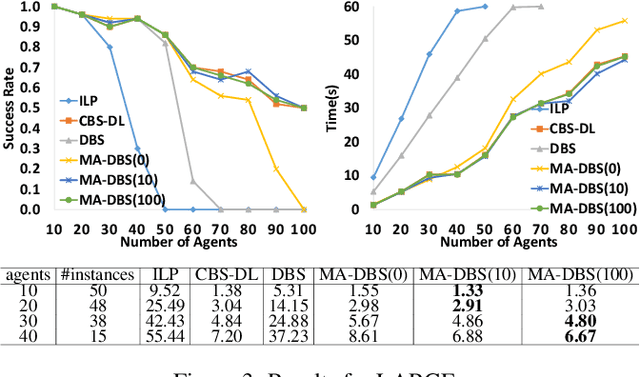
We formalize Multi-Agent Path Finding with Deadlines (MAPF-DL). The objective is to maximize the number of agents that can reach their given goal vertices from their given start vertices within the deadline, without colliding with each other. We first show that MAPF-DL is NP-hard to solve optimally. We then present two classes of optimal algorithms, one based on a reduction of MAPF-DL to a flow problem and a subsequent compact integer linear programming formulation of the resulting reduced abstracted multi-commodity flow network and the other one based on novel combinatorial search algorithms. Our empirical results demonstrate that these MAPF-DL solvers scale well and each one dominates the other ones in different scenarios.
Multi-Agent Path Finding with Deadlines: Preliminary Results
May 13, 2018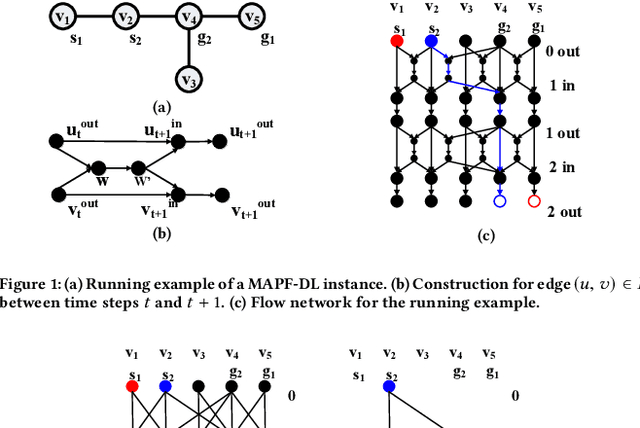
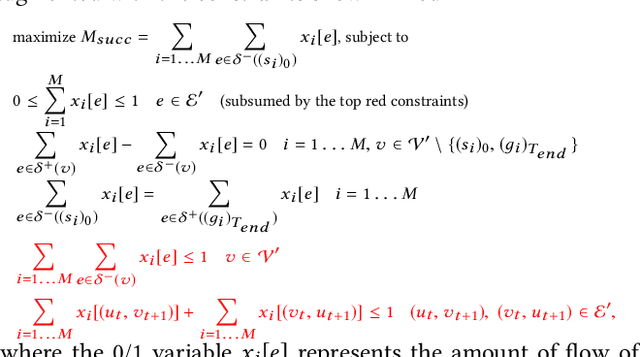
We formalize the problem of multi-agent path finding with deadlines (MAPF-DL). The objective is to maximize the number of agents that can reach their given goal vertices from their given start vertices within a given deadline, without colliding with each other. We first show that the MAPF-DL problem is NP-hard to solve optimally. We then present an optimal MAPF-DL algorithm based on a reduction of the MAPF-DL problem to a flow problem and a subsequent compact integer linear programming formulation of the resulting reduced abstracted multi-commodity flow network.
Rapid Randomized Restarts for Multi-Agent Path Finding Solvers
Jun 08, 2017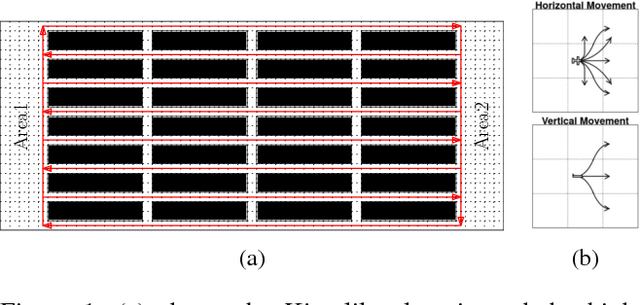
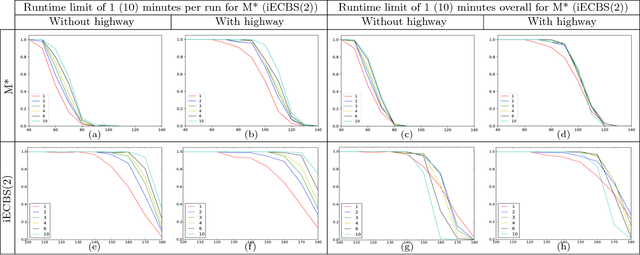
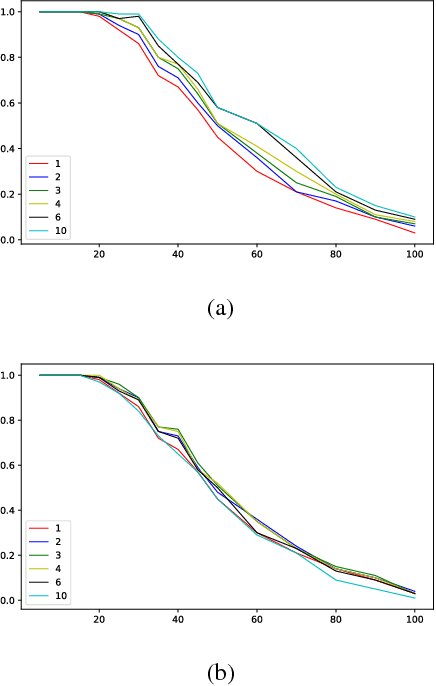
Multi-Agent Path Finding (MAPF) is an NP-hard problem well studied in artificial intelligence and robotics. It has many real-world applications for which existing MAPF solvers use various heuristics. However, these solvers are deterministic and perform poorly on "hard" instances typically characterized by many agents interfering with each other in a small region. In this paper, we enhance MAPF solvers with randomization and observe that they exhibit heavy-tailed distributions of runtimes on hard instances. This leads us to develop simple rapid randomized restart (RRR) strategies with the intuition that, given a hard instance, multiple short runs have a better chance of solving it compared to one long run. We validate this intuition through experiments and show that our RRR strategies indeed boost the performance of state-of-the-art MAPF solvers such as iECBS and M*.