 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for The Greek Language: A Longer Survey
Aug 20, 2024English language is in the spotlight of the Natural Language Processing (NLP) community with other languages, like Greek, lagging behind in terms of offered methods, tools and resources. Due to the increasing interest in NLP, in this paper we try to condense research efforts for the automatic processing of Greek language covering the last three decades. In particular, we list and briefly discuss related works, resources and tools, categorized according to various processing layers and contexts. We are not restricted to the modern form of Greek language but also cover Ancient Greek and various Greek dialects. This survey can be useful for researchers and students interested in NLP tasks, Information Retrieval and Knowledge Management for the Greek language.
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 25, 2024



Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Linguistic Cues of Deception in a Multilingual April Fools' Day Context
Nov 09, 2021

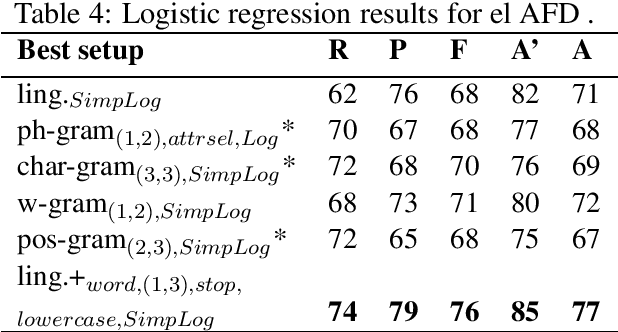
In this work we consider the collection of deceptive April Fools' Day(AFD) news articles as a useful addition in existing datasets for deception detection tasks. Such collections have an established ground truth and are relatively easy to construct across languages. As a result, we introduce a corpus that includes diachronic AFD and normal articles from Greek newspapers and news websites. On top of that, we build a rich linguistic feature set, and analyze and compare its deception cues with the only AFD collection currently available, which is in English. Following a current research thread, we also discuss the individualism/collectivism dimension in deception with respect to these two datasets. Lastly, we build classifiers by testing various monolingual and crosslingual settings. The results showcase that AFD datasets can be helpful in deception detection studies, and are in alignment with the observations of other deception detection works.
Deception detection in text and its relation to the cultural dimension of individualism/collectivism
May 26, 2021



Deception detection is a task with many applications both in direct physical and in computer-mediated communication. Our focus is on automatic deception detection in text across cultures. We view culture through the prism of the individualism/collectivism dimension and we approximate culture by using country as a proxy. Having as a starting point recent conclusions drawn from the social psychology discipline, we explore if differences in the usage of specific linguistic features of deception across cultures can be confirmed and attributed to norms in respect to the individualism/collectivism divide. We also investigate if a universal feature set for cross-cultural text deception detection tasks exists. We evaluate the predictive power of different feature sets and approaches. We create culture/language-aware classifiers by experimenting with a wide range of n-gram features based on phonology, morphology and syntax, other linguistic cues like word and phoneme counts, pronouns use, etc., and token embeddings. We conducted our experiments over 11 datasets from 5 languages i.e., English, Dutch, Russian, Spanish and Romanian, from six countries (US, Belgium, India, Russia, Mexico and Romania), and we applied two classification methods i.e, logistic regression and fine-tuned BERT models. The results showed that our task is fairly complex and demanding. There are indications that some linguistic cues of deception have cultural origins, and are consistent in the context of diverse domains and dataset settings for the same language. This is more evident for the usage of pronouns and the expression of sentiment in deceptive language. The results of this work show that the automatic deception detection across cultures and languages cannot be handled in a unified manner, and that such approaches should be augmented with knowledge about cultural differences and the domains of interest.
CS563-QA: A Collection for Evaluating Question Answering Systems
Jul 02, 2019



Question Answering (QA) is a challenging topic since it requires tackling the various difficulties of natural language understanding. Since evaluation is important not only for identifying the strong and weak points of the various techniques for QA, but also for facilitating the inception of new methods and techniques, in this paper we present a collection for evaluating QA methods over free text that we have created. Although it is a small collection, it contains cases of increasing difficulty, therefore it has an educational value and it can be used for rapid evaluation of QA systems.