 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTasks that Require, or can Benefit from, Matching Blank Nodes
Paper and Code
Oct 30, 2014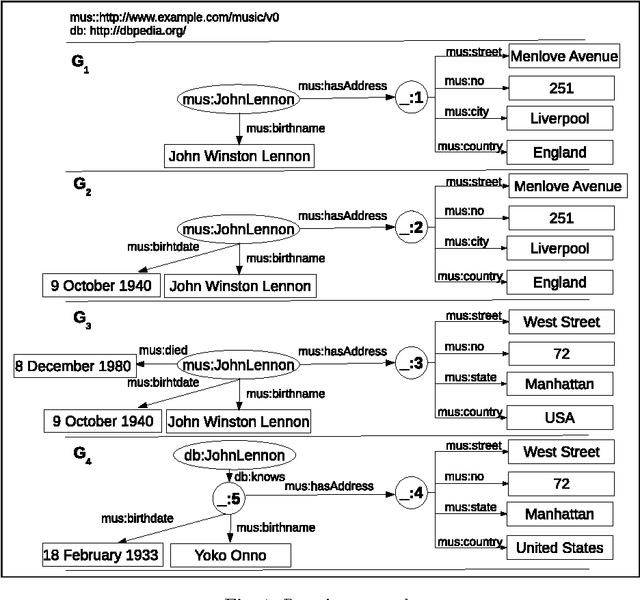

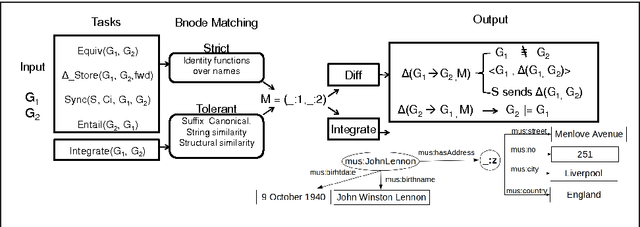
In various domains and cases, we observe the creation and usage of information elements which are unnamed. Such elements do not have a name, or may have a name that is not externally referable (usually meaningless and not persistent over time). This paper discusses why we will never `escape' from the problem of having to construct mappings between such unnamed elements in information systems. Since unnamed elements nowadays occur very often in the framework of the Semantic Web and Linked Data as blank nodes, the paper describes scenarios that can benefit from methods that compute mappings between the unnamed elements. For each scenario, the corresponding bnode matching problem is formally defined. Based on this analysis, we try to reach to more a general formulation of the problem, which can be useful for guiding the required technological advances. To this end, the paper finally discusses methods to realize blank node matching, the implementations that exist, and identifies open issues and challenges.