 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating ChatGPT Facts through RDF Knowledge Graphs and Sentence Similarity
Nov 17, 2023Since ChatGPT offers detailed responses without justifications, and erroneous facts even for popular persons, events and places, in this paper we present a novel pipeline that retrieves the response of ChatGPT in RDF and tries to validate the ChatGPT facts using one or more RDF Knowledge Graphs (KGs). To this end we leverage DBpedia and LODsyndesis (an aggregated Knowledge Graph that contains 2 billion triples from 400 RDF KGs of many domains) and short sentence embeddings, and introduce an algorithm that returns the more relevant triple(s) accompanied by their provenance and a confidence score. This enables the validation of ChatGPT responses and their enrichment with justifications and provenance. To evaluate this service (such services in general), we create an evaluation benchmark that includes 2,000 ChatGPT facts; specifically 1,000 facts for famous Greek Persons, 500 facts for popular Greek Places, and 500 facts for Events related to Greece. The facts were manually labelled (approximately 73% of ChatGPT facts were correct and 27% of facts were erroneous). The results are promising; indicatively for the whole benchmark, we managed to verify the 85.3% of the correct facts of ChatGPT and to find the correct answer for the 58% of the erroneous ChatGPT facts.
Using Multiple RDF Knowledge Graphs for Enriching ChatGPT Responses
Apr 12, 2023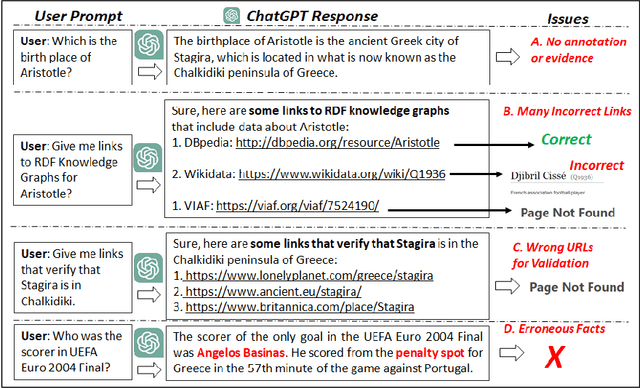
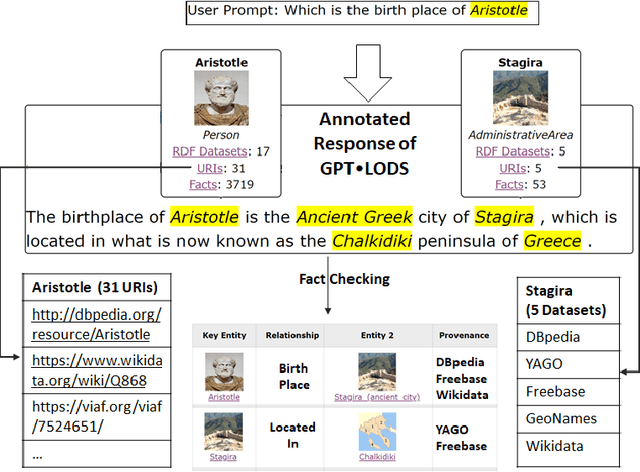
There is a recent trend for using the novel Artificial Intelligence ChatGPT chatbox, which provides detailed responses and articulate answers across many domains of knowledge. However, in many cases it returns plausible-sounding but incorrect or inaccurate responses, whereas it does not provide evidence. Therefore, any user has to further search for checking the accuracy of the answer or/and for finding more information about the entities of the response. At the same time there is a high proliferation of RDF Knowledge Graphs (KGs) over any real domain, that offer high quality structured data. For enabling the combination of ChatGPT and RDF KGs, we present a research prototype, called GPToLODS, which is able to enrich any ChatGPT response with more information from hundreds of RDF KGs. In particular, it identifies and annotates each entity of the response with statistics and hyperlinks to LODsyndesis KG (which contains integrated data from 400 RDF KGs and over 412 million entities). In this way, it is feasible to enrich the content of entities and to perform fact checking and validation for the facts of the response at real time.