 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Sign Reenactor: Deep Photorealistic Sign Language Retargeting
Paper and Code
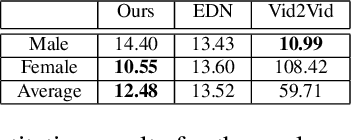
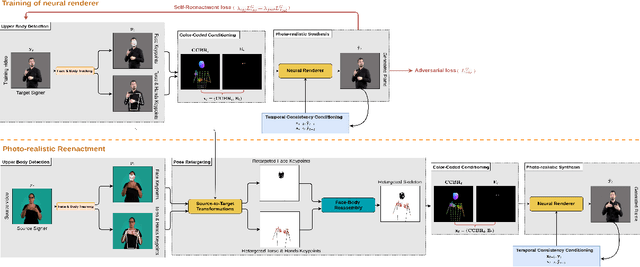

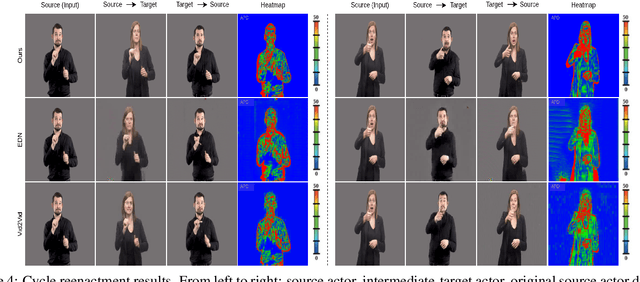
In this paper, we introduce a neural rendering pipeline for transferring the facial expressions, head pose and body movements of one person in a source video to another in a target video. We apply our method to the challenging case of Sign Language videos: given a source video of a sign language user, we can faithfully transfer the performed manual (e.g. handshape, palm orientation, movement, location) and non-manual (e.g. eye gaze, facial expressions, head movements) signs to a target video in a photo-realistic manner. To effectively capture the aforementioned cues, which are crucial for sign language communication, we build upon an effective combination of the most robust and reliable deep learning methods for body, hand and face tracking that have been introduced lately. Using a 3D-aware representation, the estimated motions of the body parts are combined and retargeted to the target signer. They are then given as conditional input to our Video Rendering Network, which generates temporally consistent and photo-realistic videos. We conduct detailed qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and its advantages over existing approaches. Our method yields promising results of unprecedented realism and can be used for Sign Language Anonymization. In addition, it can be readily applicable to reenactment of other types of full body activities (dancing, acting performance, exercising, etc.), as well as to the synthesis module of Sign Language Production systems.