 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Avatars with Hybrid 3D Representations
Paper and Code

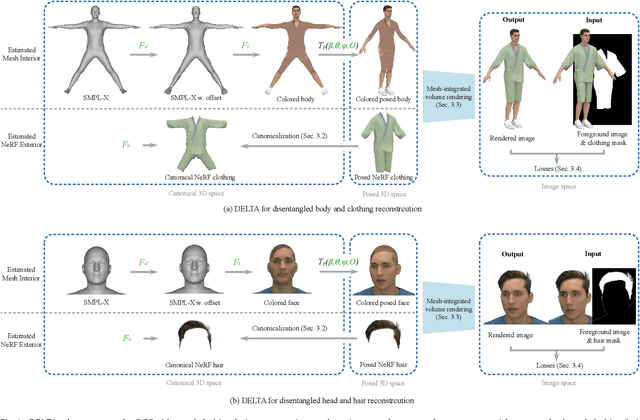
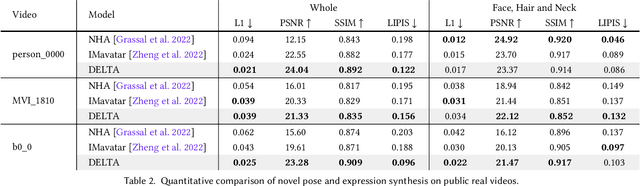
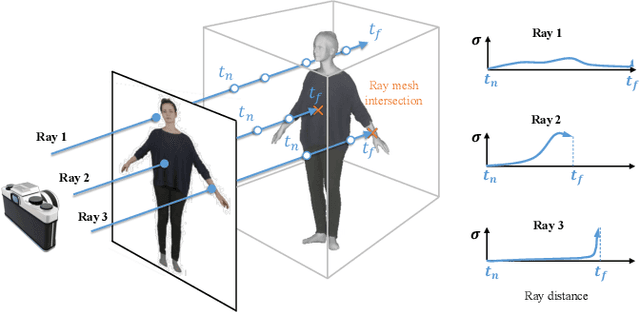
Tremendous efforts have been made to learn animatable and photorealistic human avatars. Towards this end, both explicit and implicit 3D representations are heavily studied for a holistic modeling and capture of the whole human (e.g., body, clothing, face and hair), but neither representation is an optimal choice in terms of representation efficacy since different parts of the human avatar have different modeling desiderata. For example, meshes are generally not suitable for modeling clothing and hair. Motivated by this, we present Disentangled Avatars~(DELTA), which models humans with hybrid explicit-implicit 3D representations. DELTA takes a monocular RGB video as input, and produces a human avatar with separate body and clothing/hair layers. Specifically, we demonstrate two important applications for DELTA. For the first one, we consider the disentanglement of the human body and clothing and in the second, we disentangle the face and hair. To do so, DELTA represents the body or face with an explicit mesh-based parametric 3D model and the clothing or hair with an implicit neural radiance field. To make this possible, we design an end-to-end differentiable renderer that integrates meshes into volumetric rendering, enabling DELTA to learn directly from monocular videos without any 3D supervision. Finally, we show that how these two applications can be easily combined to model full-body avatars, such that the hair, face, body and clothing can be fully disentangled yet jointly rendered. Such a disentanglement enables hair and clothing transfer to arbitrary body shapes. We empirically validate the effectiveness of DELTA's disentanglement by demonstrating its promising performance on disentangled reconstruction, virtual clothing try-on and hairstyle transfer. To facilitate future research, we also release an open-sourced pipeline for the study of hybrid human avatar modeling.