 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisMMOE: Exploiting Visual-Expert Affinity for Efficient Visual-Language MoE Offloading
May 07, 2026Large-scale vision-language mixture-of-experts (VL-MoE) models provide strong multimodal capability, but efficient deployment on memory-constrained platforms remains difficult. Existing MoE offloading systems are largely designed for text-centric workloads and become much less effective for visual-heavy inputs, where large numbers of visual tokens induce broader and less predictable expert accesses. We present VisMMoE, a VL-MoE offloading system built on a single systems insight: pruning redundant visual tokens can improve offloading not only by reducing computation, but also by reshaping expert demand. We refer to this effect as \textit{visual-expert affinity}: token pruning makes expert accesses more concentrated within layers and more stable across layers, producing a smaller and more predictable expert working set. Guided by this insight, VisMMoE combines affinity-aware token compression, lookahead expert prediction, and cache/pipeline orchestration to improve expert locality and prefetch effectiveness under tight memory budgets. We implement VisMMoE on multiple frameworks and evaluate it on representative VL-MoE models and benchmarks. VisMMoE improves end-to-end inference performance by up to 2.68x and 1.61x, respectively, over strong baselines for today's VL-MoE deployments while maintaining competitive accuracy.
MoE-SpeQ: Speculative Quantized Decoding with Proactive Expert Prefetching and Offloading for Mixture-of-Experts
Nov 18, 2025The immense memory requirements of state-of-the-art Mixture-of-Experts (MoE) models present a significant challenge for inference, often exceeding the capacity of a single accelerator. While offloading experts to host memory is a common solution, it introduces a severe I/O bottleneck over the PCIe bus, as the data-dependent nature of expert selection places these synchronous transfers directly on the critical path of execution, crippling performance. This paper argues that the I/O bottleneck can be overcome by trading a small amount of cheap, on-device computation to hide the immense cost of data movement. We present MoE-SpeQ, a new inference system built on a novel co-design of speculative execution and expert offloading. MoE-SpeQ employs a small, on-device draft model to predict the sequence of required experts for future tokens. This foresight enables a runtime orchestrator to prefetch these experts from host memory, effectively overlapping the expensive I/O with useful computation and hiding the latency from the critical path. To maximize performance, an adaptive governor, guided by an Amortization Roofline Model, dynamically tunes the speculation strategy to the underlying hardware. Our evaluation on memory-constrained devices shows that for the Phi-MoE model, MoE-SpeQ achieves at most 2.34x speedup over the state-of-the-art offloading framework. Our work establishes a new, principled approach for managing data-dependent memory access in resource-limited environments, making MoE inference more accessible on commodity hardware.
A Survey on Inference Optimization Techniques for Mixture of Experts Models
Dec 18, 2024



The emergence of large-scale Mixture of Experts (MoE) models has marked a significant advancement in artificial intelligence, offering enhanced model capacity and computational efficiency through conditional computation. However, the deployment and inference of these models present substantial challenges in terms of computational resources, latency, and energy efficiency. This comprehensive survey systematically analyzes the current landscape of inference optimization techniques for MoE models across the entire system stack. We first establish a taxonomical framework that categorizes optimization approaches into model-level, system-level, and hardware-level optimizations. At the model level, we examine architectural innovations including efficient expert design, attention mechanisms, various compression techniques such as pruning, quantization, and knowledge distillation, as well as algorithm improvement including dynamic routing strategies and expert merging methods. At the system level, we investigate distributed computing approaches, load balancing mechanisms, and efficient scheduling algorithms that enable scalable deployment. Furthermore, we delve into hardware-specific optimizations and co-design strategies that maximize throughput and energy efficiency. This survey not only provides a structured overview of existing solutions but also identifies key challenges and promising research directions in MoE inference optimization. Our comprehensive analysis serves as a valuable resource for researchers and practitioners working on large-scale deployment of MoE models in resource-constrained environments. To facilitate ongoing updates and the sharing of cutting-edge advances in MoE inference optimization research, we have established a repository accessible at \url{https://github.com/MoE-Inf/awesome-moe-inference/}.
HOBBIT: A Mixed Precision Expert Offloading System for Fast MoE Inference
Nov 03, 2024

The Mixture-of-Experts (MoE) architecture has demonstrated significant advantages in the era of Large Language Models (LLMs), offering enhanced capabilities with reduced inference costs. However, deploying MoE-based LLMs on memoryconstrained edge devices remains challenging due to their substantial memory requirements. While existing expertoffloading methods alleviate the memory requirements, they often incur significant expert-loading costs or compromise model accuracy. We present HOBBIT, a mixed precision expert offloading system to enable flexible and efficient MoE inference. Our key insight is that dynamically replacing less critical cache-miss experts with low precision versions can substantially reduce expert-loading latency while preserving model accuracy. HOBBIT introduces three innovative techniques that map the natural hierarchy of MoE computation: (1) a token-level dynamic expert loading mechanism, (2) a layer-level adaptive expert prefetching technique, and (3) a sequence-level multidimensional expert caching policy. These innovations fully leverage the benefits of mixedprecision expert inference. By implementing HOBBIT on top of the renowned LLM inference framework Llama.cpp, we evaluate its performance across different edge devices with representative MoE models. The results demonstrate that HOBBIT achieves up to a 9.93x speedup in decoding compared to state-of-the-art MoE offloading systems.
AutoVCoder: A Systematic Framework for Automated Verilog Code Generation using LLMs
Jul 21, 2024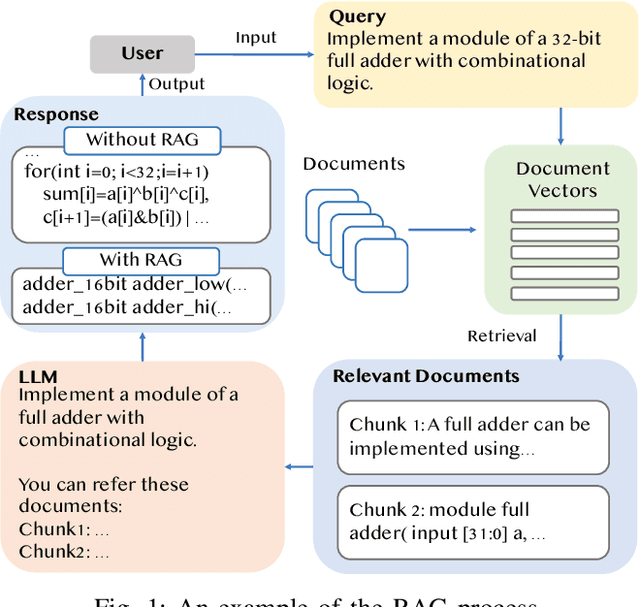
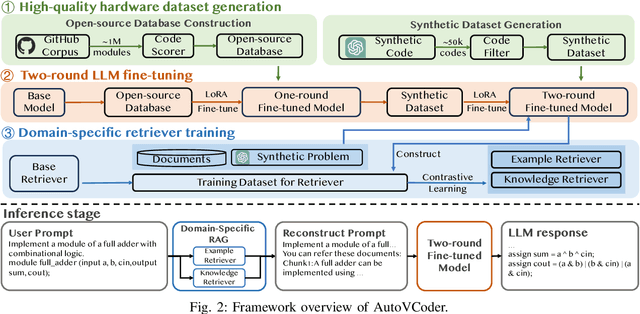
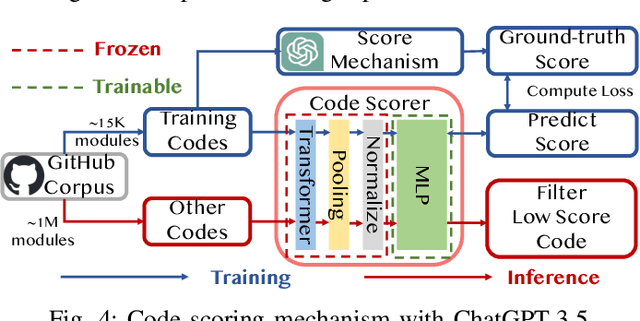
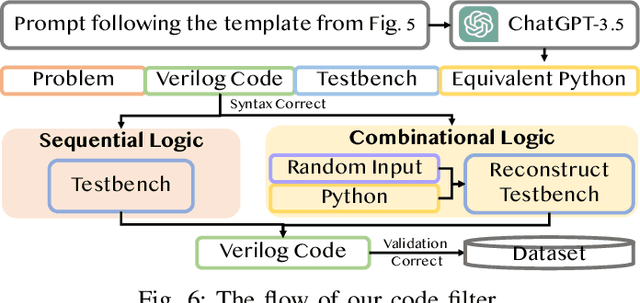
Recently, the use of large language models (LLMs) for software code generation, e.g., C/C++ and Python, has proven a great success. However, LLMs still suffer from low syntactic and functional correctness when it comes to the generation of register-transfer level (RTL) code, such as Verilog. To address this issue, in this paper, we develop AutoVCoder, a systematic open-source framework that significantly improves the LLMs' correctness of generating Verilog code and enhances the quality of its output at the same time. Our framework integrates three novel techniques, including a high-quality hardware dataset generation approach, a two-round LLM fine-tuning method and a domain-specific retrieval-augmented generation (RAG) mechanism. Experimental results demonstrate that AutoVCoder outperforms both industrial and academic LLMs in Verilog code generation. Specifically, AutoVCoder shows a 0.5% and 2.2% improvement in functional correctness on the EvalMachine and EvalHuman benchmarks compared with BetterV, and also achieves a 3.4% increase in syntax correctness and a 3.4% increase in functional correctness on the RTLLM benchmark compared with RTLCoder.
DataCLUE: A Benchmark Suite for Data-centric NLP
Nov 17, 2021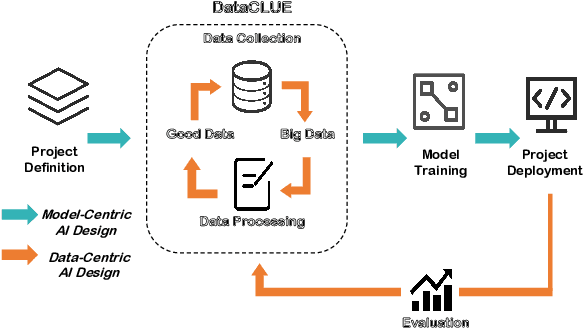
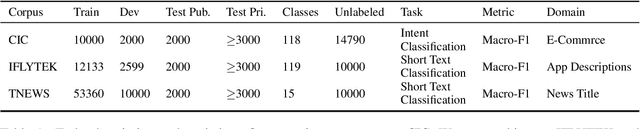

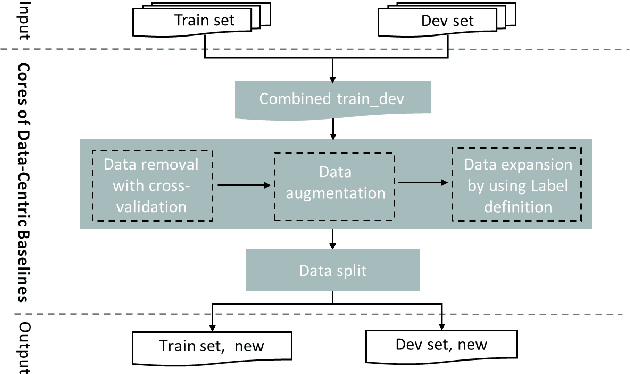
Data-centric AI has recently proven to be more effective and high-performance, while traditional model-centric AI delivers fewer and fewer benefits. It emphasizes improving the quality of datasets to achieve better model performance. This field has significant potential because of its great practicability and getting more and more attention. However, we have not seen significant research progress in this field, especially in NLP. We propose DataCLUE, which is the first Data-Centric benchmark applied in NLP field. We also provide three simple but effective baselines to foster research in this field (improve Macro-F1 up to 5.7% point). In addition, we conduct comprehensive experiments with human annotators and show the hardness of DataCLUE. We also try an advanced method: the forgetting informed bootstrapping label correction method. All the resources related to DataCLUE, including datasets, toolkit, leaderboard, and baselines, is available online at https://github.com/CLUEbenchmark/DataCLUE
A method using deep learning to discover new predictors of CRT response from mechanical dyssynchrony on gated SPECT MPI
Jun 01, 2021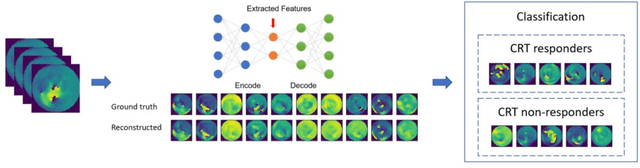
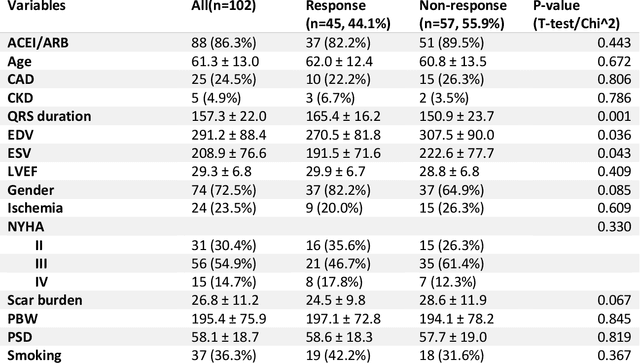
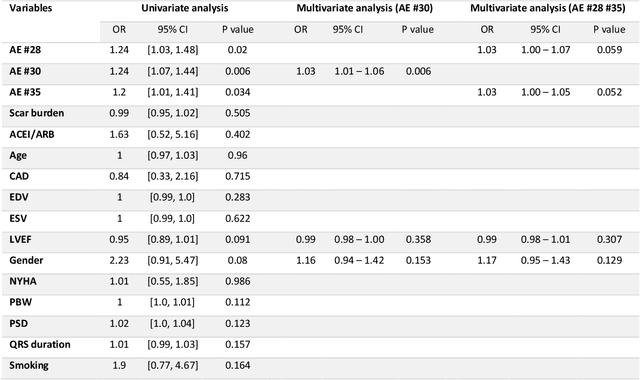
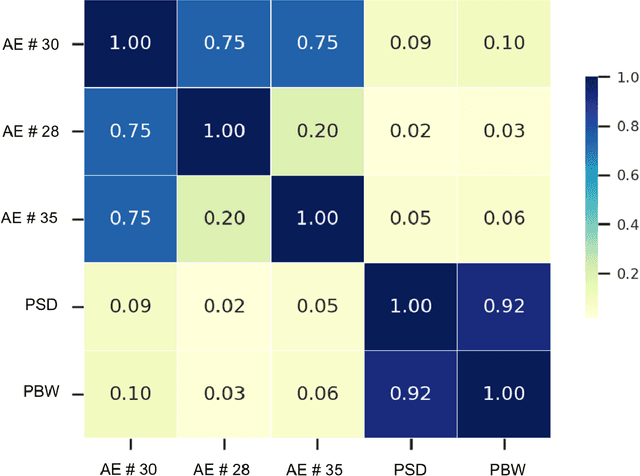
Background. Studies have shown that the conventional left ventricular mechanical dyssynchrony (LVMD) parameters have their own statistical limitations. The purpose of this study is to extract new LVMD parameters from the phase analysis of gated SPECT MPI by deep learning to help CRT patient selection. Methods. One hundred and three patients who underwent rest gated SPECT MPI were enrolled in this study. CRT response was defined as a decrease in left ventricular end-systolic volume (LVESV) >= 15% at 6 +- 1 month follow up. Autoencoder (AE), an unsupervised deep learning method, was trained by the raw LV systolic phase polar maps to extract new LVMD parameters, called AE-based LVMD parameters. Correlation analysis was used to explain the relationships between new parameters with conventional LVMD parameters. Univariate and multivariate analyses were used to establish a multivariate model for predicting CRT response. Results. Complete data were obtained in 102 patients, 44.1% of them were classified as CRT responders. AE-based LVMD parameter was significant in the univariate (OR 1.24, 95% CI 1.07 - 1.44, P = 0.006) and multivariate analyses (OR 1.03, 95% CI 1.01 - 1.06, P = 0.006). Moreover, it had incremental value over PSD (AUC 0.72 vs. 0.63, LH 8.06, P = 0.005) and PBW (AUC 0.72 vs. 0.64, LH 7.87, P = 0.005), combined with significant clinic characteristics, including LVEF and gender. Conclusions. The new LVMD parameters extracted by autoencoder from the baseline gated SPECT MPI has the potential to improve the prediction of CRT response.