 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVCoder: A Systematic Framework for Automated Verilog Code Generation using LLMs
Jul 21, 2024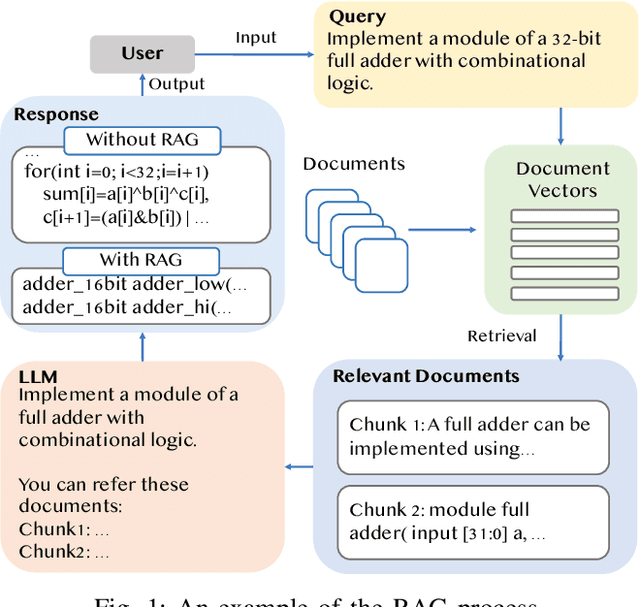
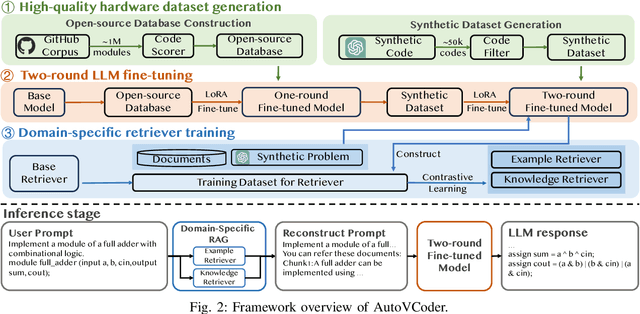
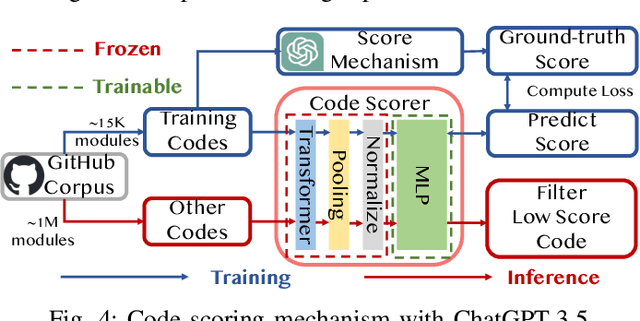
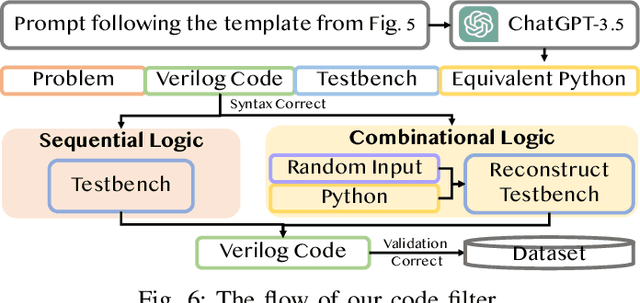
Recently, the use of large language models (LLMs) for software code generation, e.g., C/C++ and Python, has proven a great success. However, LLMs still suffer from low syntactic and functional correctness when it comes to the generation of register-transfer level (RTL) code, such as Verilog. To address this issue, in this paper, we develop AutoVCoder, a systematic open-source framework that significantly improves the LLMs' correctness of generating Verilog code and enhances the quality of its output at the same time. Our framework integrates three novel techniques, including a high-quality hardware dataset generation approach, a two-round LLM fine-tuning method and a domain-specific retrieval-augmented generation (RAG) mechanism. Experimental results demonstrate that AutoVCoder outperforms both industrial and academic LLMs in Verilog code generation. Specifically, AutoVCoder shows a 0.5% and 2.2% improvement in functional correctness on the EvalMachine and EvalHuman benchmarks compared with BetterV, and also achieves a 3.4% increase in syntax correctness and a 3.4% increase in functional correctness on the RTLLM benchmark compared with RTLCoder.
Hierarchical Source-to-Post-Route QoR Prediction in High-Level Synthesis with GNNs
Jan 14, 2024



High-level synthesis (HLS) notably speeds up the hardware design process by avoiding RTL programming. However, the turnaround time of HLS increases significantly when post-route quality of results (QoR) are considered during optimization. To tackle this issue, we propose a hierarchical post-route QoR prediction approach for FPGA HLS, which features: (1) a modeling flow that directly estimates latency and post-route resource usage from C/C++ programs; (2) a graph construction method that effectively represents the control and data flow graph of source code and effects of HLS pragmas; and (3) a hierarchical GNN training and prediction method capable of capturing the impact of loop hierarchies. Experimental results show that our method presents a prediction error of less than 10% for different types of QoR metrics, which gains tremendous improvement compared with the state-of-the-art GNN methods. By adopting our proposed methodology, the runtime for design space exploration in HLS is shortened to tens of minutes and the achieved ADRS is reduced to 6.91% on average.