 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Pitfalls: Evaluating LLMs in Machine Learning Programming Education
May 23, 2025The rapid advancement of Large Language Models (LLMs) has opened new avenues in education. This study examines the use of LLMs in supporting learning in machine learning education; in particular, it focuses on the ability of LLMs to identify common errors of practice (pitfalls) in machine learning code, and their ability to provide feedback that can guide learning. Using a portfolio of code samples, we consider four different LLMs: one closed model and three open models. Whilst the most basic pitfalls are readily identified by all models, many common pitfalls are not. They particularly struggle to identify pitfalls in the early stages of the ML pipeline, especially those which can lead to information leaks, a major source of failure within applied ML projects. They also exhibit limited success at identifying pitfalls around model selection, which is a concept that students often struggle with when first transitioning from theory to practice. This questions the use of current LLMs to support machine learning education, and also raises important questions about their use by novice practitioners. Nevertheless, when LLMs successfully identify pitfalls in code, they do provide feedback that includes advice on how to proceed, emphasising their potential role in guiding learners. We also compare the capability of closed and open LLM models, and find that the gap is relatively small given the large difference in model sizes. This presents an opportunity to deploy, and potentially customise, smaller more efficient LLM models within education, avoiding risks around cost and data sharing associated with commercial models.
Self-Supervised Learning for Pre-training Capsule Networks: Overcoming Medical Imaging Dataset Challenges
Feb 07, 2025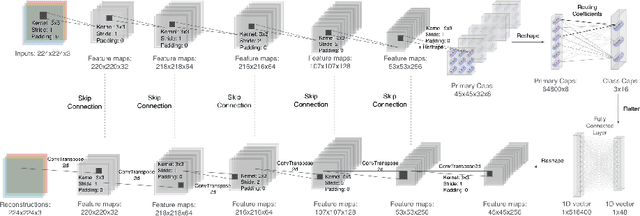
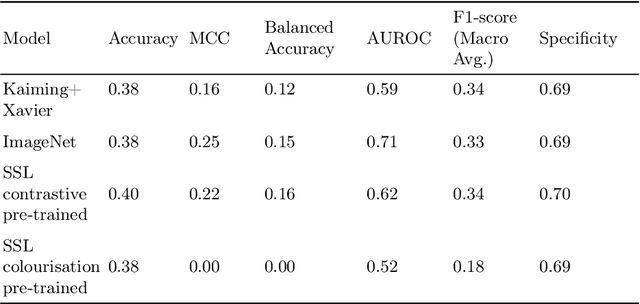
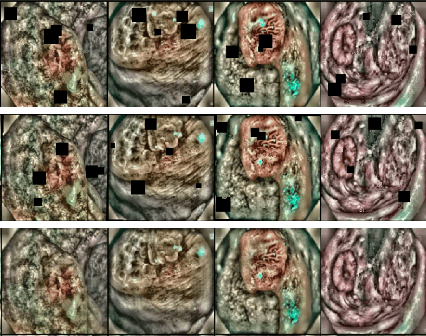
Deep learning techniques are increasingly being adopted in diagnostic medical imaging. However, the limited availability of high-quality, large-scale medical datasets presents a significant challenge, often necessitating the use of transfer learning approaches. This study investigates self-supervised learning methods for pre-training capsule networks in polyp diagnostics for colon cancer. We used the PICCOLO dataset, comprising 3,433 samples, which exemplifies typical challenges in medical datasets: small size, class imbalance, and distribution shifts between data splits. Capsule networks offer inherent interpretability due to their architecture and inter-layer information routing mechanism. However, their limited native implementation in mainstream deep learning frameworks and the lack of pre-trained versions pose a significant challenge. This is particularly true if aiming to train them on small medical datasets, where leveraging pre-trained weights as initial parameters would be beneficial. We explored two auxiliary self-supervised learning tasks, colourisation and contrastive learning, for capsule network pre-training. We compared self-supervised pre-trained models against alternative initialisation strategies. Our findings suggest that contrastive learning and in-painting techniques are suitable auxiliary tasks for self-supervised learning in the medical domain. These techniques helped guide the model to capture important visual features that are beneficial for the downstream task of polyp classification, increasing its accuracy by 5.26% compared to other weight initialisation methods.
ActDroid: An active learning framework for Android malware detection
Jan 30, 2024The growing popularity of Android requires malware detection systems that can keep up with the pace of new software being released. According to a recent study, a new piece of malware appears online every 12 seconds. To address this, we treat Android malware detection as a streaming data problem and explore the use of active online learning as a means of mitigating the problem of labelling applications in a timely and cost-effective manner. Our resulting framework achieves accuracies of up to 96\%, requires as little of 24\% of the training data to be labelled, and compensates for concept drift that occurs between the release and labelling of an application. We also consider the broader practicalities of online learning within Android malware detection, and systematically explore the trade-offs between using different static, dynamic and hybrid feature sets to classify malware.
A Comprehensive Investigation of Feature and Model Importance in Android Malware Detection
Jan 30, 2023The popularity and relative openness of Android means it is a popular target for malware. Over the years, various studies have found that machine learning models can effectively discriminate malware from benign applications. However, as the operating system evolves, so does malware, bringing into question the findings of these previous studies, many of which used small, outdated, and often imbalanced datasets. In this paper, we reimplement 16 representative past works and evaluate them on a balanced, relevant and up-to-date dataset comprising 124,000 Android applications. We also carry out new experiments designed to fill holes in existing knowledge, and use our findings to identify the most effective features and models to use for Android malware detection within a contemporary environment. Our results suggest that accuracies of up to 96.8% can be achieved using static features alone, with a further 1% achievable using more expensive dynamic analysis approaches. We find the best models to be random forests built from API call usage and TCP network traffic features.