 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqualizing Credit Opportunity in Algorithms: Aligning Algorithmic Fairness Research with U.S. Fair Lending Regulation
Oct 05, 2022Credit is an essential component of financial wellbeing in America, and unequal access to it is a large factor in the economic disparities between demographic groups that exist today. Today, machine learning algorithms, sometimes trained on alternative data, are increasingly being used to determine access to credit, yet research has shown that machine learning can encode many different versions of "unfairness," thus raising the concern that banks and other financial institutions could -- potentially unwittingly -- engage in illegal discrimination through the use of this technology. In the US, there are laws in place to make sure discrimination does not happen in lending and agencies charged with enforcing them. However, conversations around fair credit models in computer science and in policy are often misaligned: fair machine learning research often lacks legal and practical considerations specific to existing fair lending policy, and regulators have yet to issue new guidance on how, if at all, credit risk models should be utilizing practices and techniques from the research community. This paper aims to better align these sides of the conversation. We describe the current state of credit discrimination regulation in the United States, contextualize results from fair ML research to identify the specific fairness concerns raised by the use of machine learning in lending, and discuss regulatory opportunities to address these concerns.
Quantifying Challenges in the Application of Graph Representation Learning
Jun 18, 2020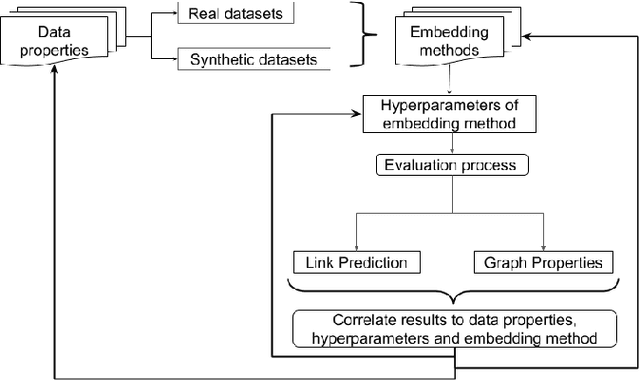

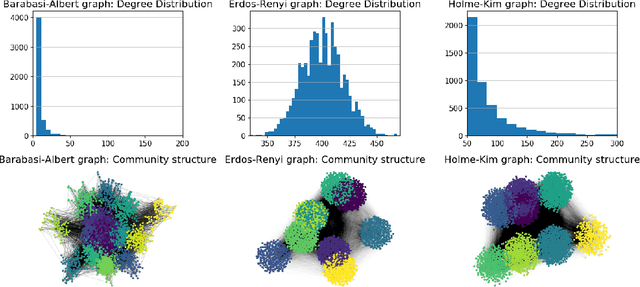
Graph Representation Learning (GRL) has experienced significant progress as a means to extract structural information in a meaningful way for subsequent learning tasks. Current approaches including shallow embeddings and Graph Neural Networks have mostly been tested with node classification and link prediction tasks. In this work, we provide an application oriented perspective to a set of popular embedding approaches and evaluate their representational power with respect to real-world graph properties. We implement an extensive empirical data-driven framework to challenge existing norms regarding the expressive power of embedding approaches in graphs with varying patterns along with a theoretical analysis of the limitations we discovered in this process. Our results suggest that "one-to-fit-all" GRL approaches are hard to define in real-world scenarios and as new methods are being introduced they should be explicit about their ability to capture graph properties and their applicability in datasets with non-trivial structural differences.
On the Interpretability and Evaluation of Graph Representation Learning
Oct 07, 2019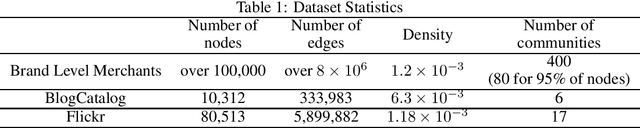
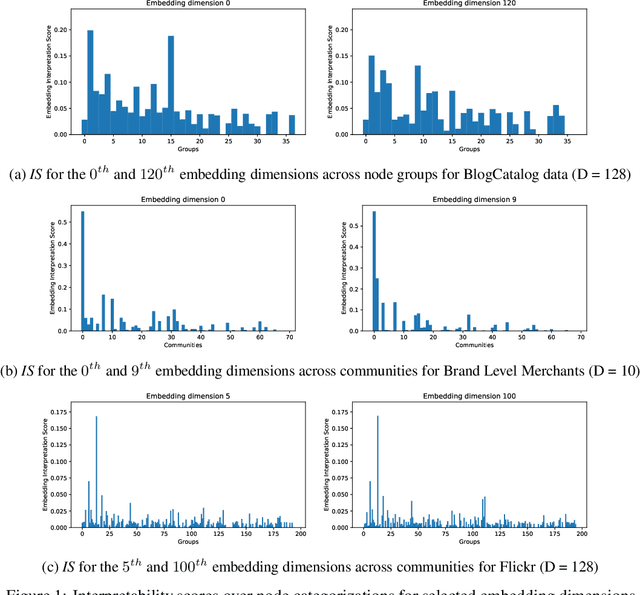
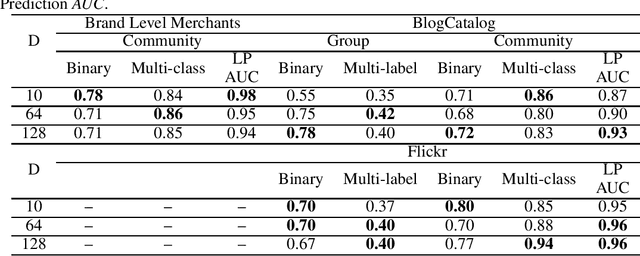
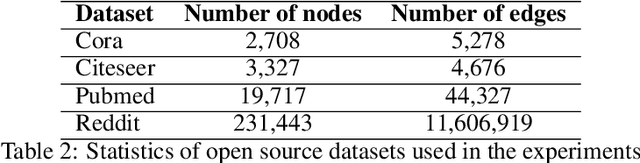
With the rising interest in graph representation learning, a variety of approaches have been proposed to effectively capture a graph's properties. While these approaches have improved performance in graph machine learning tasks compared to traditional graph techniques, they are still perceived as techniques with limited insight into the information encoded in these representations. In this work, we explore methods to interpret node embeddings and propose the creation of a robust evaluation framework for comparing graph representation learning algorithms and hyperparameters. We test our methods on graphs with different properties and investigate the relationship between embedding training parameters and the ability of the produced embedding to recover the structure of the original graph in a downstream task.
DeepTrax: Embedding Graphs of Financial Transactions
Jul 16, 2019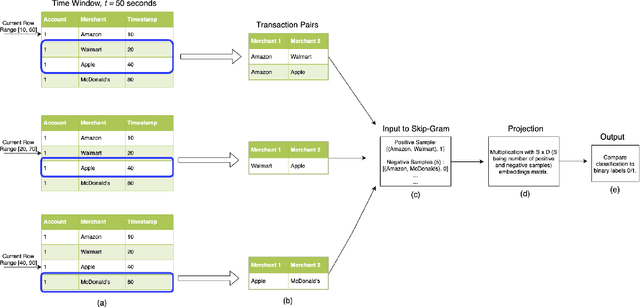
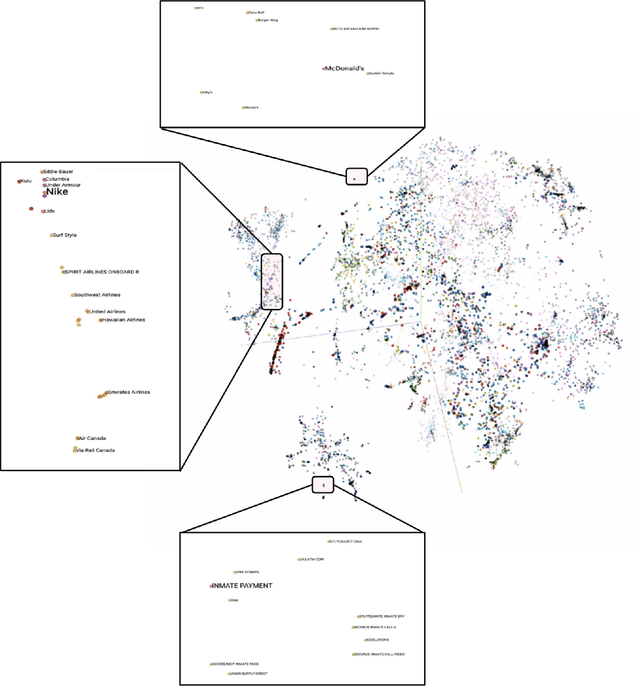
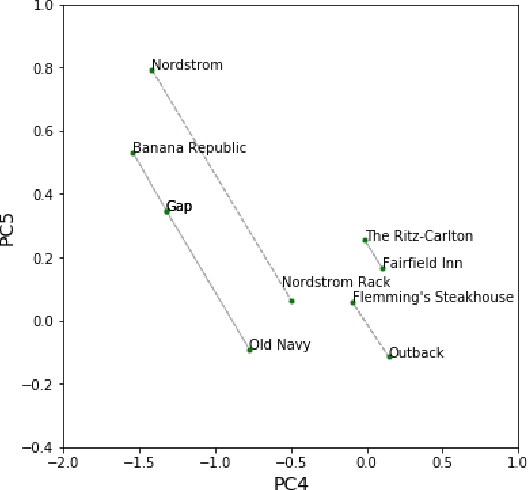
Financial transactions can be considered edges in a heterogeneous graph between entities sending money and entities receiving money. For financial institutions, such a graph is likely large (with millions or billions of edges) while also sparsely connected. It becomes challenging to apply machine learning to such large and sparse graphs. Graph representation learning seeks to embed the nodes of a graph into a Euclidean vector space such that graph topological properties are preserved after the transformation. In this paper, we present a novel application of representation learning to bipartite graphs of credit card transactions in order to learn embeddings of account and merchant entities. Our framework is inspired by popular approaches in graph embeddings and is trained on two internal transaction datasets. This approach yields highly effective embeddings, as quantified by link prediction AUC and F1 score. Further, the resulting entity vectors retain intuitive semantic similarity that is explored through visualizations and other qualitative analyses. Finally, we show how these embeddings can be used as features in downstream machine learning business applications such as fraud detection.
Graph Embeddings at Scale
Jul 03, 2019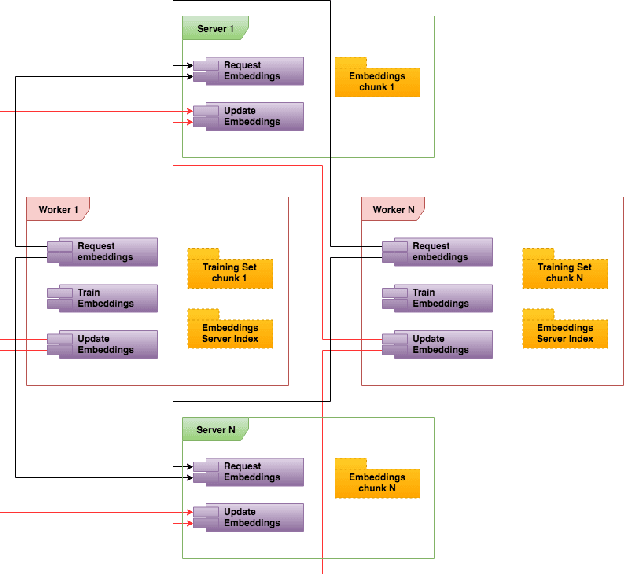

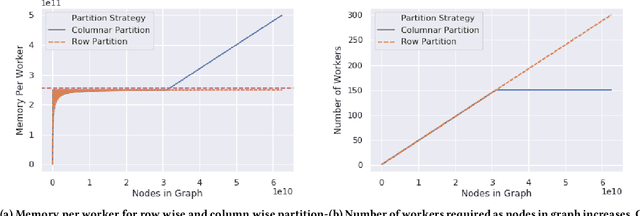

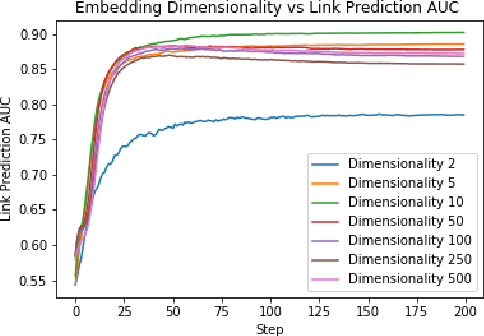
Graph embedding is a popular algorithmic approach for creating vector representations for individual vertices in networks. Training these algorithms at scale is important for creating embeddings that can be used for classification, ranking, recommendation and other common applications in industry. While industrial systems exist for training graph embeddings on large datasets, many of these distributed architectures are forced to partition copious amounts of data and model logic across many worker nodes. In this paper, we propose a distributed infrastructure that completely avoids graph partitioning, dynamically creates size constrained computational graphs across worker nodes, and uses highly efficient indexing operations for updating embeddings that allow the system to function at scale. We show that our system can scale an existing embeddings algorithm - skip-gram - to train on the open-source Friendster network (68 million vertices) and on an internal heterogeneous graph (50 million vertices). We measure the performance of our system on two key quantitative metrics: link-prediction accuracy and rate of convergence. We conclude this work by analyzing how a greater number of worker nodes actually improves our system's performance on the aforementioned metrics and discuss our next steps for rigorously evaluating the embedding vectors produced by our system.
A Multitask Network for Localization and Recognition of Text in Images
Jun 21, 2019
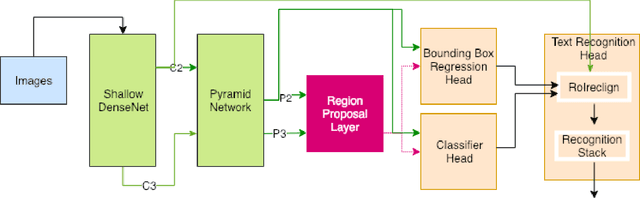

We present an end-to-end trainable multi-task network that addresses the problem of lexicon-free text extraction from complex documents. This network simultaneously solves the problems of text localization and text recognition and text segments are identified with no post-processing, cropping, or word grouping. A convolutional backbone and Feature Pyramid Network are combined to provide a shared representation that benefits each of three model heads: text localization, classification, and text recognition. To improve recognition accuracy, we describe a dynamic pooling mechanism that retains high-resolution information across all RoIs. For text recognition, we propose a convolutional mechanism with attention which out-performs more common recurrent architectures. Our model is evaluated against benchmark datasets and comparable methods and achieves high performance in challenging regimes of non-traditional OCR.